 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPSDA: Unsupervised Pseudo Semantic Data Augmentation for Zero-Shot Cross-Lingual Natural Language Understanding
Jun 24, 2024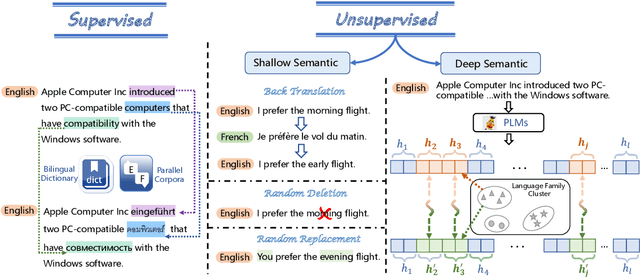
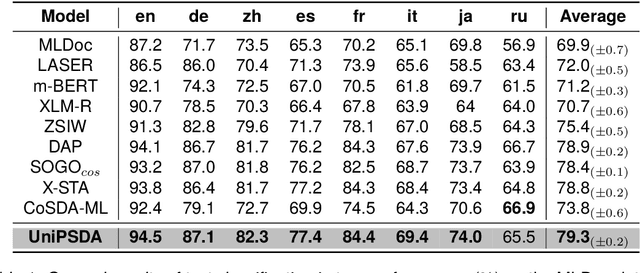
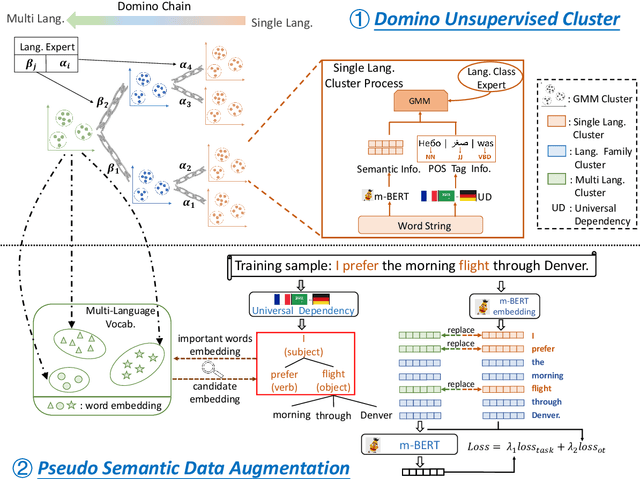
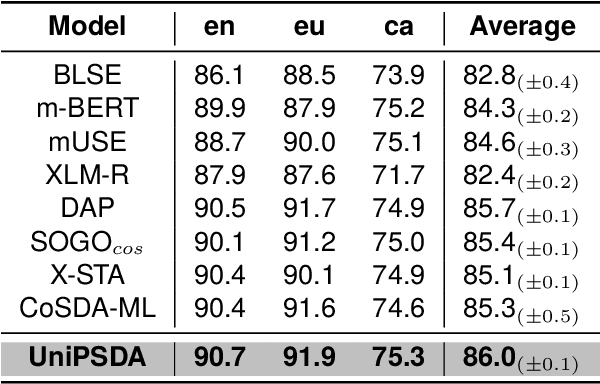
Cross-lingual representation learning transfers knowledge from resource-rich data to resource-scarce ones to improve the semantic understanding abilities of different languages. However, previous works rely on shallow unsupervised data generated by token surface matching, regardless of the global context-aware semantics of the surrounding text tokens. In this paper, we propose an Unsupervised Pseudo Semantic Data Augmentation (UniPSDA) mechanism for cross-lingual natural language understanding to enrich the training data without human interventions. Specifically, to retrieve the tokens with similar meanings for the semantic data augmentation across different languages, we propose a sequential clustering process in 3 stages: within a single language, across multiple languages of a language family, and across languages from multiple language families. Meanwhile, considering the multi-lingual knowledge infusion with context-aware semantics while alleviating computation burden, we directly replace the key constituents of the sentences with the above-learned multi-lingual family knowledge, viewed as pseudo-semantic. The infusion process is further optimized via three de-biasing techniques without introducing any neural parameters. Extensive experiments demonstrate that our model consistently improves the performance on general zero-shot cross-lingual natural language understanding tasks, including sequence classification, information extraction, and question answering.
Channel Self-Supervision for Online Knowledge Distillation
Mar 23, 2022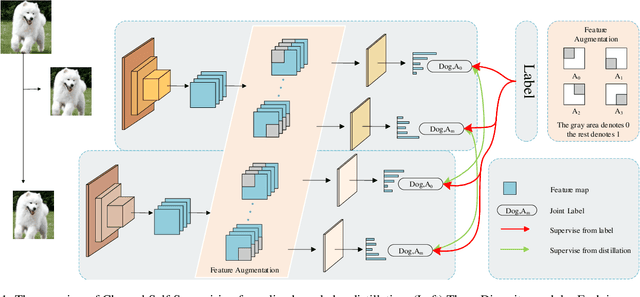
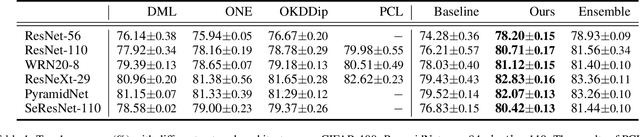
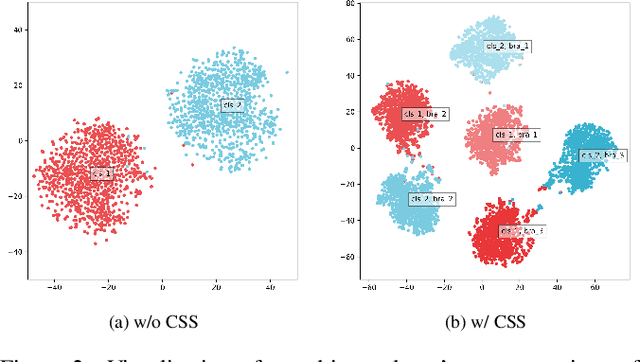
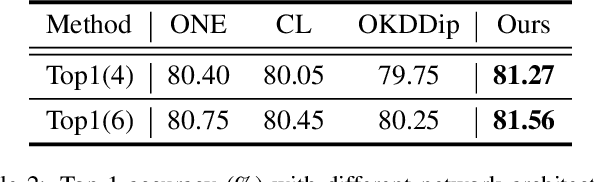
Recently, researchers have shown an increased interest in the online knowledge distillation. Adopting an one-stage and end-to-end training fashion, online knowledge distillation uses aggregated intermediated predictions of multiple peer models for training. However, the absence of a powerful teacher model may result in the homogeneity problem between group peers, affecting the effectiveness of group distillation adversely. In this paper, we propose a novel online knowledge distillation method, \textbf{C}hannel \textbf{S}elf-\textbf{S}upervision for Online Knowledge Distillation (CSS), which structures diversity in terms of input, target, and network to alleviate the homogenization problem. Specifically, we construct a dual-network multi-branch structure and enhance inter-branch diversity through self-supervised learning, adopting the feature-level transformation and augmenting the corresponding labels. Meanwhile, the dual network structure has a larger space of independent parameters to resist the homogenization problem during distillation. Extensive quantitative experiments on CIFAR-100 illustrate that our method provides greater diversity than OKDDip and we also give pretty performance improvement, even over the state-of-the-art such as PCL. The results on three fine-grained datasets (StanfordDogs, StanfordCars, CUB-200-211) also show the significant generalization capability of our approach.
Temporally Resolution Decrement: Utilizing the Shape Consistency for Higher Computational Efficiency
Dec 02, 2021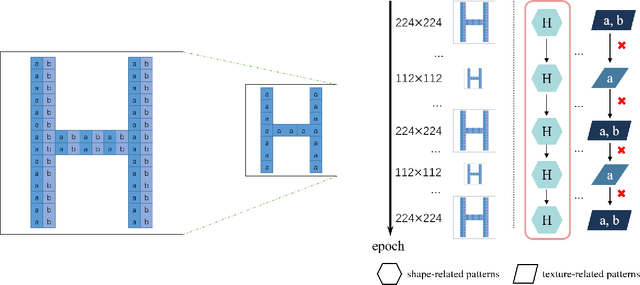
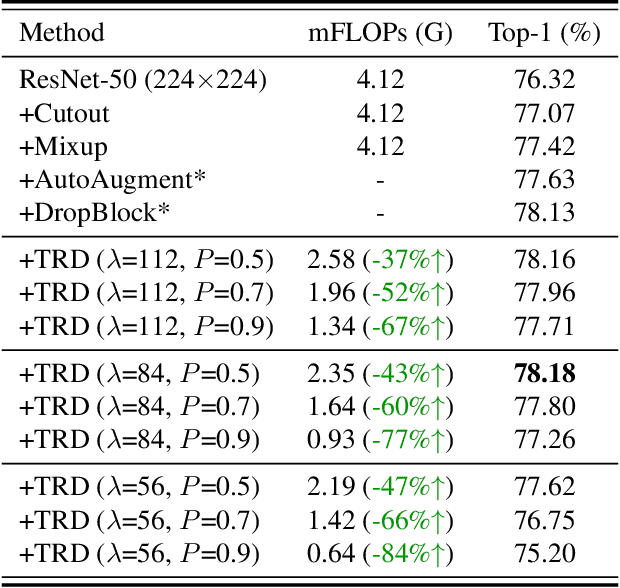
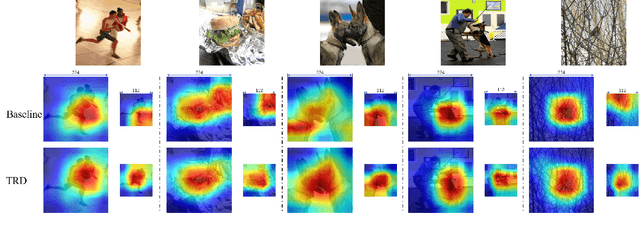
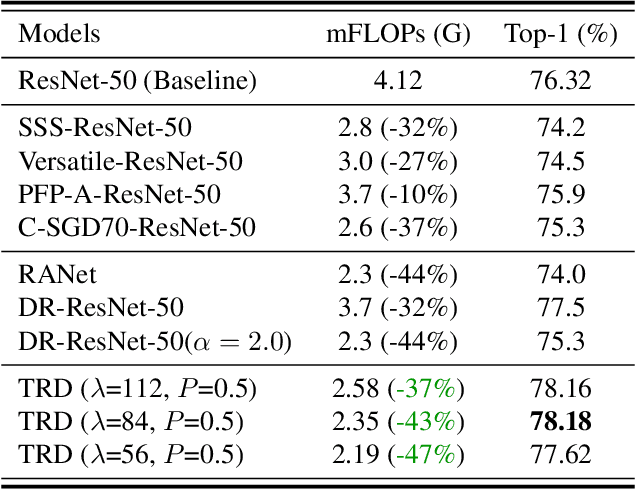
Image resolution that has close relations with accuracy and computational cost plays a pivotal role in network training. In this paper, we observe that the reduced image retains relatively complete shape semantics but loses extensive texture information. Inspired by the consistency of the shape semantics as well as the fragility of the texture information, we propose a novel training strategy named Temporally Resolution Decrement. Wherein, we randomly reduce the training images to a smaller resolution in the time domain. During the alternate training with the reduced images and the original images, the unstable texture information in the images results in a weaker correlation between the texture-related patterns and the correct label, naturally enforcing the model to rely more on shape properties that are robust and conform to the human decision rule. Surprisingly, our approach greatly improves the computational efficiency of convolutional neural networks. On ImageNet classification, using only 33% calculation quantity (randomly reducing the training image to 112$\times$112 within 90% epochs) can still improve ResNet-50 from 76.32% to 77.71%, and using 63% calculation quantity (randomly reducing the training image to 112 x 112 within 50% epochs) can improve ResNet-50 to 78.18%.
Feature Mining: A Novel Training Strategy for Convolutional Neural Network
Jul 18, 2021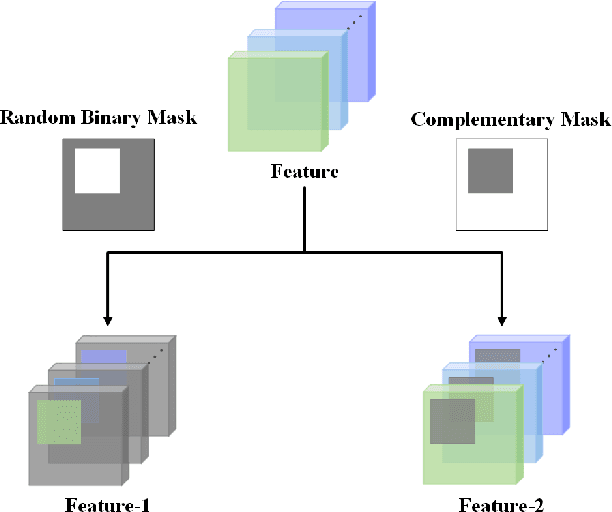
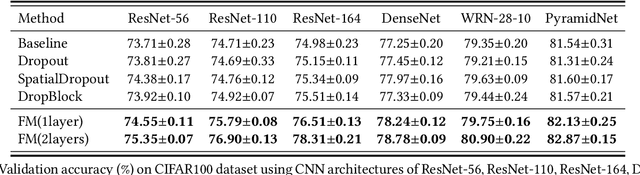


In this paper, we propose a novel training strategy for convolutional neural network(CNN) named Feature Mining, that aims to strengthen the network's learning of the local feature. Through experiments, we find that semantic contained in different parts of the feature is different, while the network will inevitably lose the local information during feedforward propagation. In order to enhance the learning of local feature, Feature Mining divides the complete feature into two complementary parts and reuse these divided feature to make the network learn more local information, we call the two steps as feature segmentation and feature reusing. Feature Mining is a parameter-free method and has plug-and-play nature, and can be applied to any CNN models. Extensive experiments demonstrate the wide applicability, versatility, and compatibility of our method.
Go Small and Similar: A Simple Output Decay Brings Better Performance
Jun 12, 2021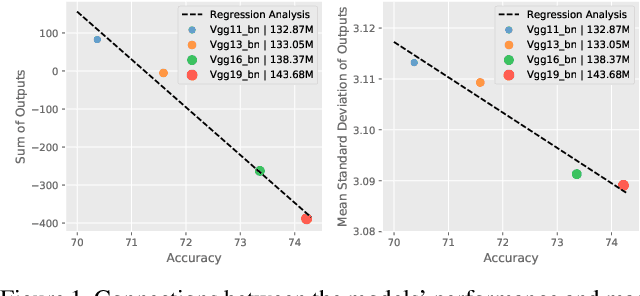
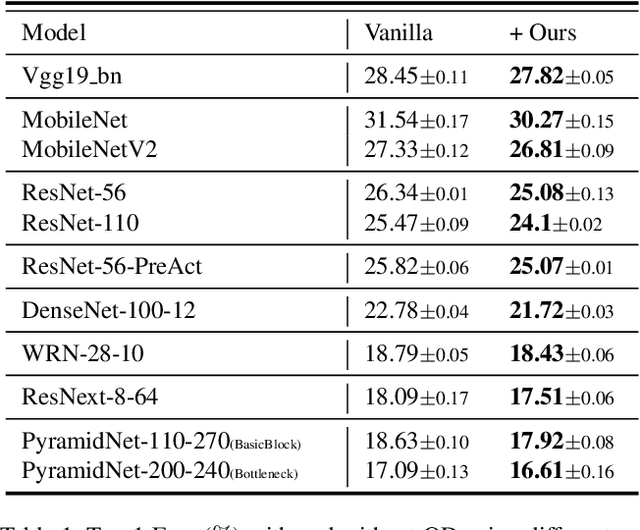
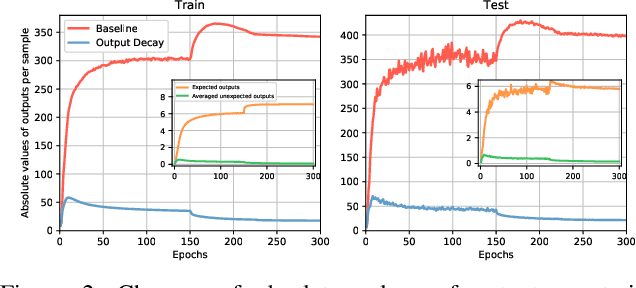

Regularization and data augmentation methods have been widely used and become increasingly indispensable in deep learning training. Researchers who devote themselves to this have considered various possibilities. But so far, there has been little discussion about regularizing outputs of the model. This paper begins with empirical observations that better performances are significantly associated with output distributions, that have smaller average values and variances. By audaciously assuming there is causality involved, we propose a novel regularization term, called Output Decay, that enforces the model to assign smaller and similar output values on each class. Though being counter-intuitive, such a small modification result in a remarkable improvement on performance. Extensive experiments demonstrate the wide applicability, versatility, and compatibility of Output Decay.
White Paper Assistance: A Step Forward Beyond the Shortcut Learning
Jun 08, 2021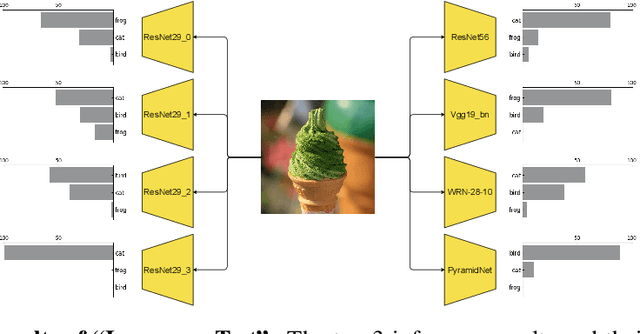

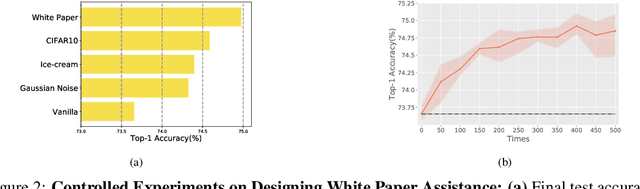
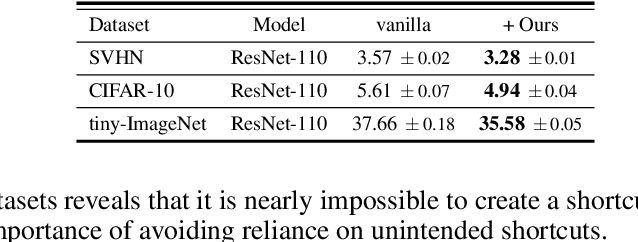
The promising performances of CNNs often overshadow the need to examine whether they are doing in the way we are actually interested. We show through experiments that even over-parameterized models would still solve a dataset by recklessly leveraging spurious correlations, or so-called 'shortcuts'. To combat with this unintended propensity, we borrow the idea of printer test page and propose a novel approach called White Paper Assistance. Our proposed method involves the white paper to detect the extent to which the model has preference for certain characterized patterns and alleviates it by forcing the model to make a random guess on the white paper. We show the consistent accuracy improvements that are manifest in various architectures, datasets and combinations with other techniques. Experiments have also demonstrated the versatility of our approach on fine-grained recognition, imbalanced classification and robustness to corruptions.
FocusedDropout for Convolutional Neural Network
Mar 29, 2021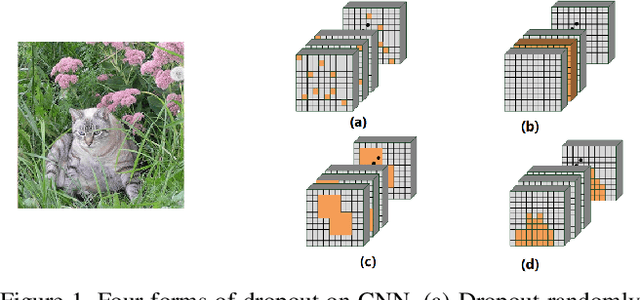
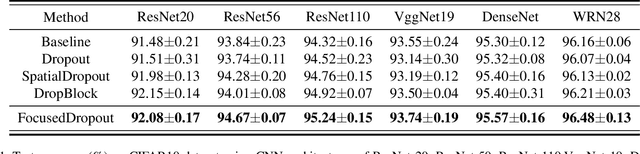

In convolutional neural network (CNN), dropout cannot work well because dropped information is not entirely obscured in convolutional layers where features are correlated spatially. Except randomly discarding regions or channels, many approaches try to overcome this defect by dropping influential units. In this paper, we propose a non-random dropout method named FocusedDropout, aiming to make the network focus more on the target. In FocusedDropout, we use a simple but effective way to search for the target-related features, retain these features and discard others, which is contrary to the existing methods. We found that this novel method can improve network performance by making the network more target-focused. Besides, increasing the weight decay while using FocusedDropout can avoid the overfitting and increase accuracy. Experimental results show that even a slight cost, 10\% of batches employing FocusedDropout, can produce a nice performance boost over the baselines on multiple datasets of classification, including CIFAR10, CIFAR100, Tiny Imagenet, and has a good versatility for different CNN models.
Selective Output Smoothing Regularization: Regularize Neural Networks by Softening Output Distributions
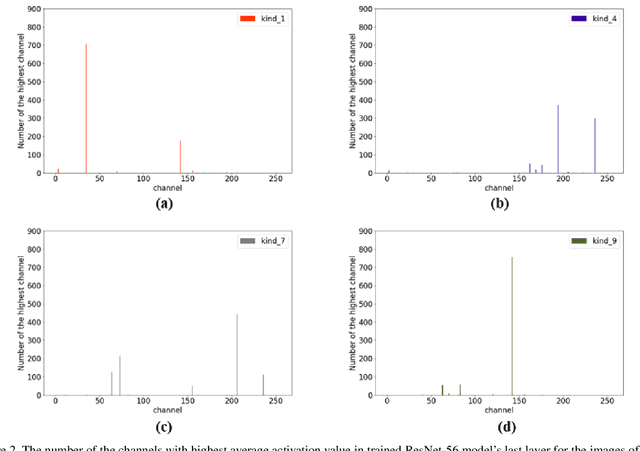
Mar 29, 2021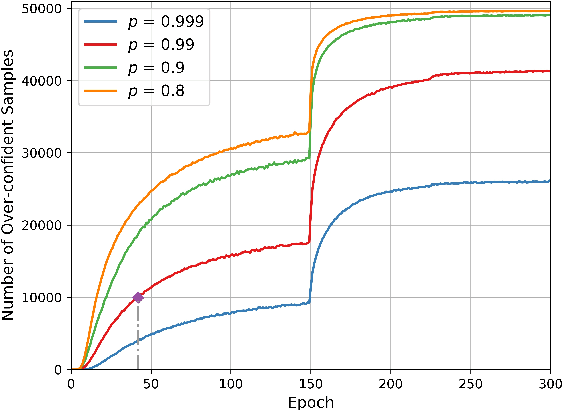
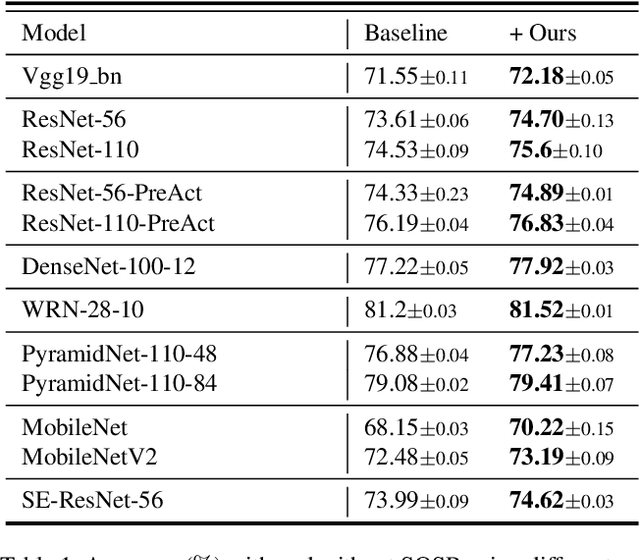
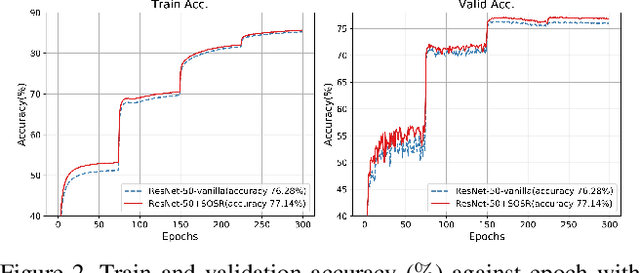

In this paper, we propose Selective Output Smoothing Regularization, a novel regularization method for training the Convolutional Neural Networks (CNNs). Inspired by the diverse effects on training from different samples, Selective Output Smoothing Regularization improves the performance by encouraging the model to produce equal logits on incorrect classes when dealing with samples that the model classifies correctly and over-confidently. This plug-and-play regularization method can be conveniently incorporated into almost any CNN-based project without extra hassle. Extensive experiments have shown that Selective Output Smoothing Regularization consistently achieves significant improvement in image classification benchmarks, such as CIFAR-100, Tiny ImageNet, ImageNet, and CUB-200-2011. Particularly, our method obtains 77.30$\%$ accuracy on ImageNet with ResNet-50, which gains 1.1$\%$ than baseline (76.2$\%$). We also empirically demonstrate the ability of our method to make further improvements when combining with other widely used regularization techniques. On Pascal detection, using the SOSR-trained ImageNet classifier as the pretrained model leads to better detection performances. Moreover, we demonstrate the effectiveness of our method in small sample size problem and imbalanced dataset problem.
Thumbnail: A Novel Data Augmentation for Convolutional Neural Network
Mar 09, 2021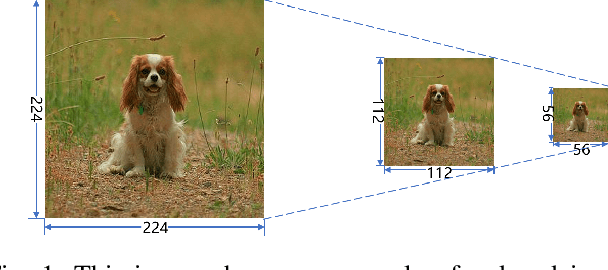


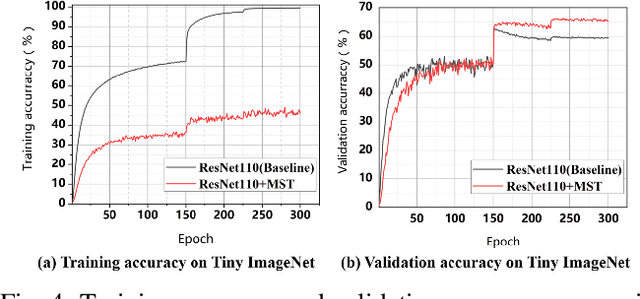
In this paper, we propose a new data augmentation strategy named Thumbnail, which aims to strengthen the network's capture of global features. We get a generated image by reducing an image to a certain size, which is called as the thumbnail, and pasting it in the random position of the original image. The generated image not only retains most of the original image information but also has the global information in the thumbnail. Furthermore, we find that the idea of thumbnail can be perfectly integrated with Mixed Sample Data Augmentation, so we paste the thumbnail in another image where the ground truth labels are also mixed with a certain weight, which makes great achievements on various computer vision tasks. Extensive experiments show that Thumbnail works better than the state-of-the-art augmentation strategies across classification, fine-grained image classification, and object detection. On ImageNet classification, ResNet50 architecture with our method achieves 79.21% accuracy, which is more than 2.89% improvement on the baseline.