 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGo Small and Similar: A Simple Output Decay Brings Better Performance
Paper and Code
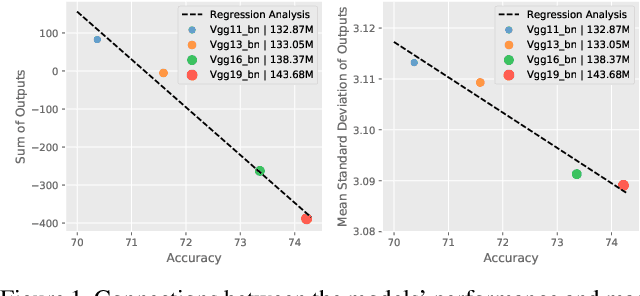
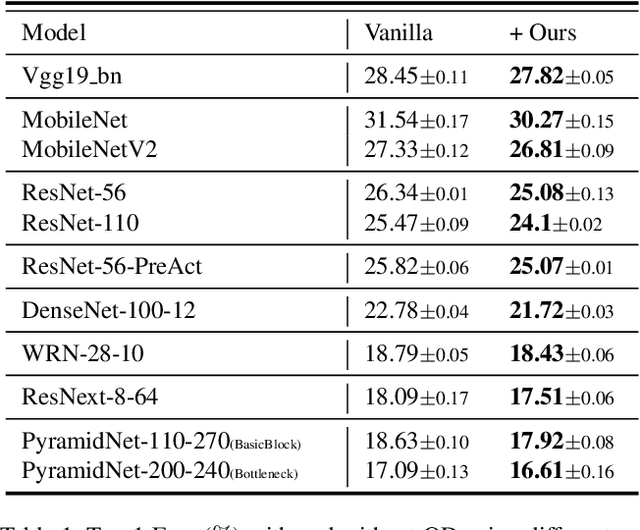
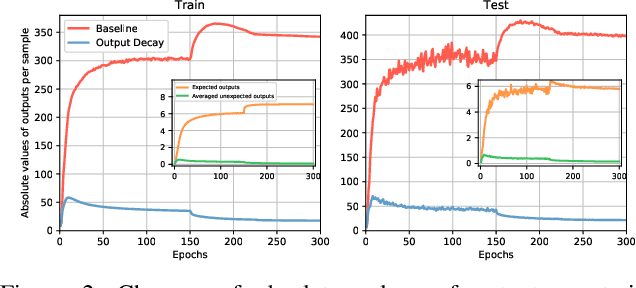

Regularization and data augmentation methods have been widely used and become increasingly indispensable in deep learning training. Researchers who devote themselves to this have considered various possibilities. But so far, there has been little discussion about regularizing outputs of the model. This paper begins with empirical observations that better performances are significantly associated with output distributions, that have smaller average values and variances. By audaciously assuming there is causality involved, we propose a novel regularization term, called Output Decay, that enforces the model to assign smaller and similar output values on each class. Though being counter-intuitive, such a small modification result in a remarkable improvement on performance. Extensive experiments demonstrate the wide applicability, versatility, and compatibility of Output Decay.