 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceRefiner: High-Fidelity Facial Texture Refinement with Differentiable Rendering-based Style Transfer
Jan 08, 2026Recent facial texture generation methods prefer to use deep networks to synthesize image content and then fill in the UV map, thus generating a compelling full texture from a single image. Nevertheless, the synthesized texture UV map usually comes from a space constructed by the training data or the 2D face generator, which limits the methods' generalization ability for in-the-wild input images. Consequently, their facial details, structures and identity may not be consistent with the input. In this paper, we address this issue by proposing a style transfer-based facial texture refinement method named FaceRefiner. FaceRefiner treats the 3D sampled texture as style and the output of a texture generation method as content. The photo-realistic style is then expected to be transferred from the style image to the content image. Different from current style transfer methods that only transfer high and middle level information to the result, our style transfer method integrates differentiable rendering to also transfer low level (or pixel level) information in the visible face regions. The main benefit of such multi-level information transfer is that, the details, structures and semantics in the input can thus be well preserved. The extensive experiments on Multi-PIE, CelebA and FFHQ datasets demonstrate that our refinement method can improve the texture quality and the face identity preserving ability, compared with state-of-the-arts.
DNPM: A Neural Parametric Model for the Synthesis of Facial Geometric Details
May 30, 2024



Parametric 3D models have enabled a wide variety of computer vision and graphics tasks, such as modeling human faces, bodies and hands. In 3D face modeling, 3DMM is the most widely used parametric model, but can't generate fine geometric details solely from identity and expression inputs. To tackle this limitation, we propose a neural parametric model named DNPM for the facial geometric details, which utilizes deep neural network to extract latent codes from facial displacement maps encoding details and wrinkles. Built upon DNPM, a novel 3DMM named Detailed3DMM is proposed, which augments traditional 3DMMs by including the synthesis of facial details only from the identity and expression inputs. Moreover, we show that DNPM and Detailed3DMM can facilitate two downstream applications: speech-driven detailed 3D facial animation and 3D face reconstruction from a degraded image. Extensive experiments have shown the usefulness of DNPM and Detailed3DMM, and the progressiveness of two proposed applications.
Learn2Talk: 3D Talking Face Learns from 2D Talking Face
Apr 19, 2024



Speech-driven facial animation methods usually contain two main classes, 3D and 2D talking face, both of which attract considerable research attention in recent years. However, to the best of our knowledge, the research on 3D talking face does not go deeper as 2D talking face, in the aspect of lip-synchronization (lip-sync) and speech perception. To mind the gap between the two sub-fields, we propose a learning framework named Learn2Talk, which can construct a better 3D talking face network by exploiting two expertise points from the field of 2D talking face. Firstly, inspired by the audio-video sync network, a 3D sync-lip expert model is devised for the pursuit of lip-sync between audio and 3D facial motion. Secondly, a teacher model selected from 2D talking face methods is used to guide the training of the audio-to-3D motions regression network to yield more 3D vertex accuracy. Extensive experiments show the advantages of the proposed framework in terms of lip-sync, vertex accuracy and speech perception, compared with state-of-the-arts. Finally, we show two applications of the proposed framework: audio-visual speech recognition and speech-driven 3D Gaussian Splatting based avatar animation.
Towards a Simultaneous and Granular Identity-Expression Control in Personalized Face Generation
Jan 02, 2024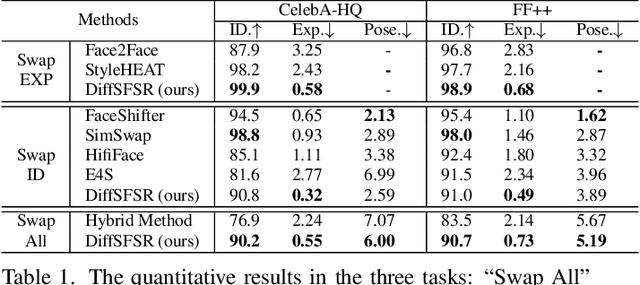
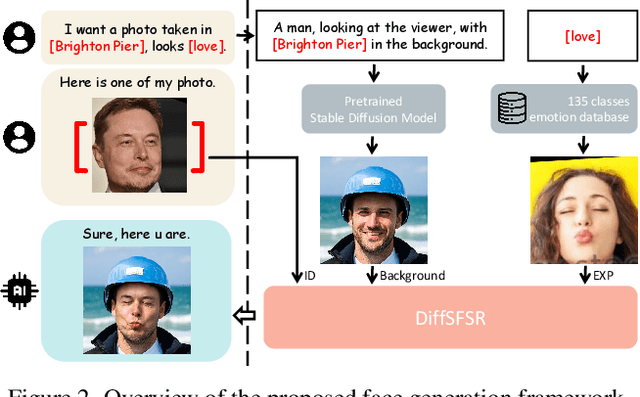

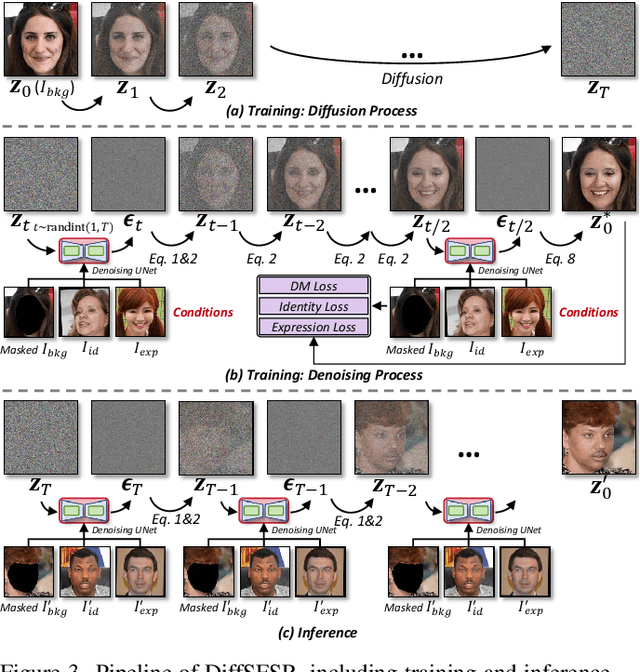
In human-centric content generation, the pre-trained text-to-image models struggle to produce user-wanted portrait images, which retain the identity of individuals while exhibiting diverse expressions. This paper introduces our efforts towards personalized face generation. To this end, we propose a novel multi-modal face generation framework, capable of simultaneous identity-expression control and more fine-grained expression synthesis. Our expression control is so sophisticated that it can be specialized by the fine-grained emotional vocabulary. We devise a novel diffusion model that can undertake the task of simultaneously face swapping and reenactment. Due to the entanglement of identity and expression, it's nontrivial to separately and precisely control them in one framework, thus has not been explored yet. To overcome this, we propose several innovative designs in the conditional diffusion model, including balancing identity and expression encoder, improved midpoint sampling, and explicitly background conditioning. Extensive experiments have demonstrated the controllability and scalability of the proposed framework, in comparison with state-of-the-art text-to-image, face swapping, and face reenactment methods.
EMEF: Ensemble Multi-Exposure Image Fusion
May 22, 2023



Although remarkable progress has been made in recent years, current multi-exposure image fusion (MEF) research is still bounded by the lack of real ground truth, objective evaluation function, and robust fusion strategy. In this paper, we study the MEF problem from a new perspective. We don't utilize any synthesized ground truth, design any loss function, or develop any fusion strategy. Our proposed method EMEF takes advantage of the wisdom of multiple imperfect MEF contributors including both conventional and deep learning-based methods. Specifically, EMEF consists of two main stages: pre-train an imitator network and tune the imitator in the runtime. In the first stage, we make a unified network imitate different MEF targets in a style modulation way. In the second stage, we tune the imitator network by optimizing the style code, in order to find an optimal fusion result for each input pair. In the experiment, we construct EMEF from four state-of-the-art MEF methods and then make comparisons with the individuals and several other competitive methods on the latest released MEF benchmark dataset. The promising experimental results demonstrate that our ensemble framework can "get the best of all worlds". The code is available at https://github.com/medalwill/EMEF.
I^2R-Net: Intra- and Inter-Human Relation Network for Multi-Person Pose Estimation
Jun 27, 2022
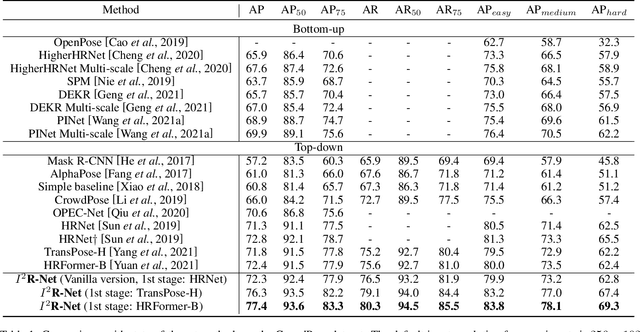
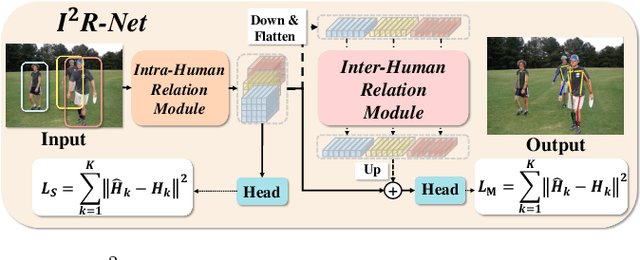
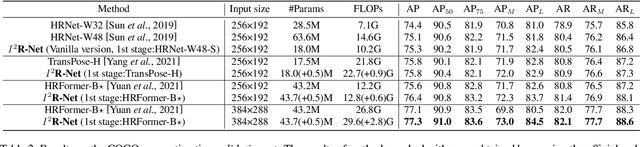
In this paper, we present the Intra- and Inter-Human Relation Networks (I^2R-Net) for Multi-Person Pose Estimation. It involves two basic modules. First, the Intra-Human Relation Module operates on a single person and aims to capture Intra-Human dependencies. Second, the Inter-Human Relation Module considers the relation between multiple instances and focuses on capturing Inter-Human interactions. The Inter-Human Relation Module can be designed very lightweight by reducing the resolution of feature map, yet learn useful relation information to significantly boost the performance of the Intra-Human Relation Module. Even without bells and whistles, our method can compete or outperform current competition winners. We conduct extensive experiments on COCO, CrowdPose, and OCHuman datasets. The results demonstrate that the proposed model surpasses all the state-of-the-art methods. Concretely, the proposed method achieves 77.4% AP on CrowPose dataset and 67.8% AP on OCHuman dataset respectively, outperforming existing methods by a large margin. Additionally, the ablation study and visualization analysis also prove the effectiveness of our model.
Channel Self-Supervision for Online Knowledge Distillation
Mar 23, 2022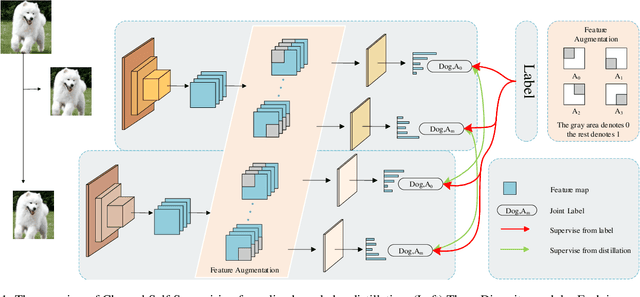
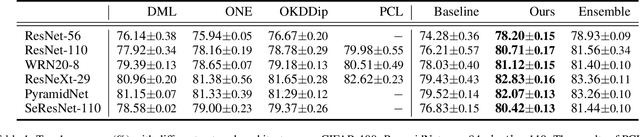
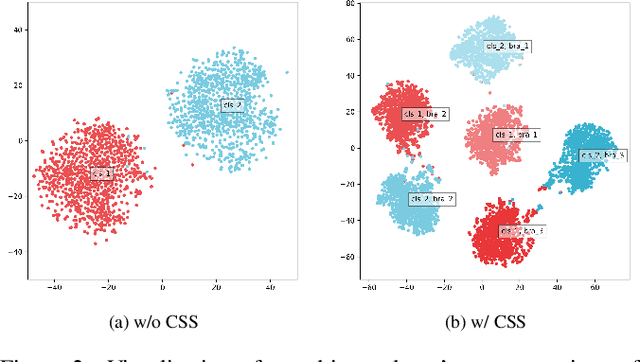
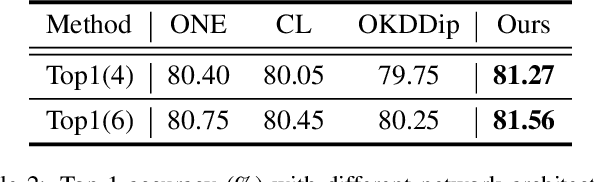
Recently, researchers have shown an increased interest in the online knowledge distillation. Adopting an one-stage and end-to-end training fashion, online knowledge distillation uses aggregated intermediated predictions of multiple peer models for training. However, the absence of a powerful teacher model may result in the homogeneity problem between group peers, affecting the effectiveness of group distillation adversely. In this paper, we propose a novel online knowledge distillation method, \textbf{C}hannel \textbf{S}elf-\textbf{S}upervision for Online Knowledge Distillation (CSS), which structures diversity in terms of input, target, and network to alleviate the homogenization problem. Specifically, we construct a dual-network multi-branch structure and enhance inter-branch diversity through self-supervised learning, adopting the feature-level transformation and augmenting the corresponding labels. Meanwhile, the dual network structure has a larger space of independent parameters to resist the homogenization problem during distillation. Extensive quantitative experiments on CIFAR-100 illustrate that our method provides greater diversity than OKDDip and we also give pretty performance improvement, even over the state-of-the-art such as PCL. The results on three fine-grained datasets (StanfordDogs, StanfordCars, CUB-200-211) also show the significant generalization capability of our approach.
Temporally Resolution Decrement: Utilizing the Shape Consistency for Higher Computational Efficiency
Dec 02, 2021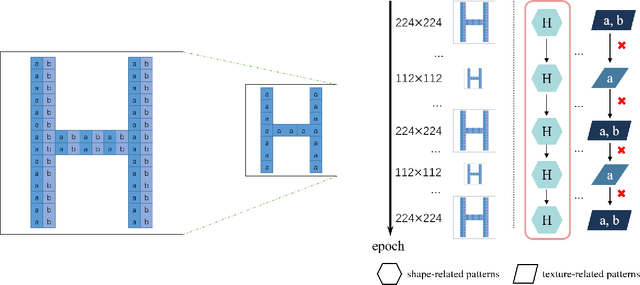
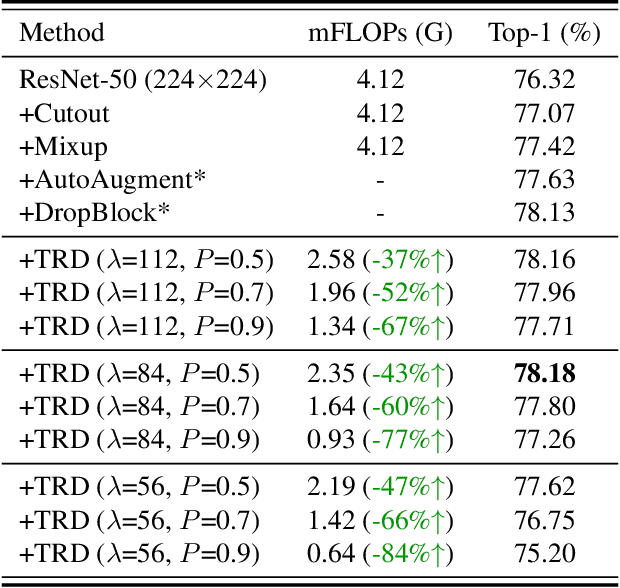
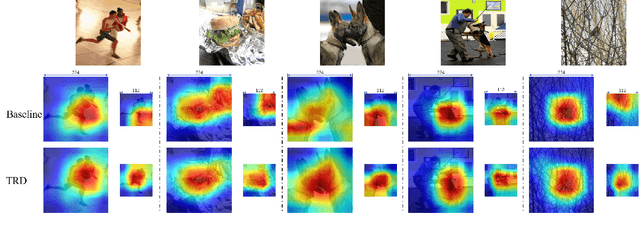
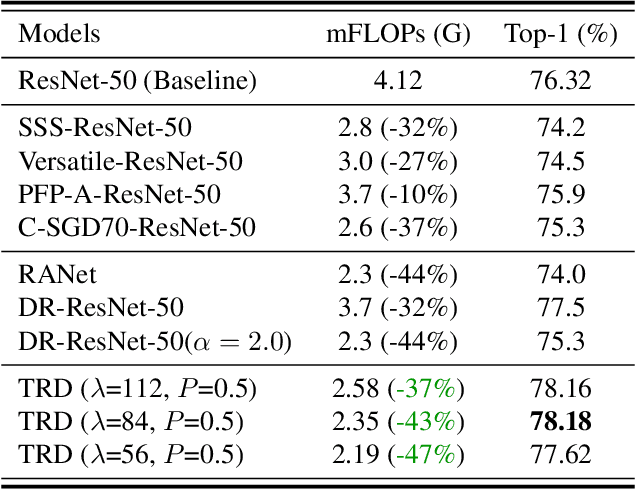
Image resolution that has close relations with accuracy and computational cost plays a pivotal role in network training. In this paper, we observe that the reduced image retains relatively complete shape semantics but loses extensive texture information. Inspired by the consistency of the shape semantics as well as the fragility of the texture information, we propose a novel training strategy named Temporally Resolution Decrement. Wherein, we randomly reduce the training images to a smaller resolution in the time domain. During the alternate training with the reduced images and the original images, the unstable texture information in the images results in a weaker correlation between the texture-related patterns and the correct label, naturally enforcing the model to rely more on shape properties that are robust and conform to the human decision rule. Surprisingly, our approach greatly improves the computational efficiency of convolutional neural networks. On ImageNet classification, using only 33% calculation quantity (randomly reducing the training image to 112$\times$112 within 90% epochs) can still improve ResNet-50 from 76.32% to 77.71%, and using 63% calculation quantity (randomly reducing the training image to 112 x 112 within 50% epochs) can improve ResNet-50 to 78.18%.
Feature Mining: A Novel Training Strategy for Convolutional Neural Network
Jul 18, 2021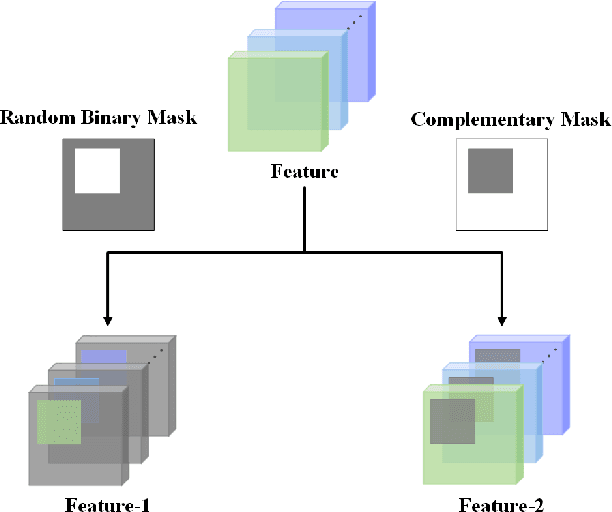
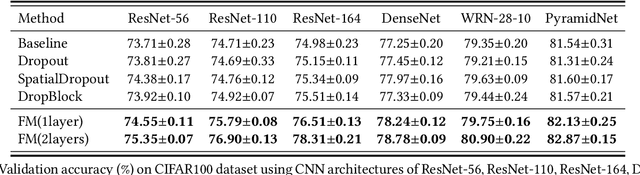


In this paper, we propose a novel training strategy for convolutional neural network(CNN) named Feature Mining, that aims to strengthen the network's learning of the local feature. Through experiments, we find that semantic contained in different parts of the feature is different, while the network will inevitably lose the local information during feedforward propagation. In order to enhance the learning of local feature, Feature Mining divides the complete feature into two complementary parts and reuse these divided feature to make the network learn more local information, we call the two steps as feature segmentation and feature reusing. Feature Mining is a parameter-free method and has plug-and-play nature, and can be applied to any CNN models. Extensive experiments demonstrate the wide applicability, versatility, and compatibility of our method.
Go Small and Similar: A Simple Output Decay Brings Better Performance
Jun 12, 2021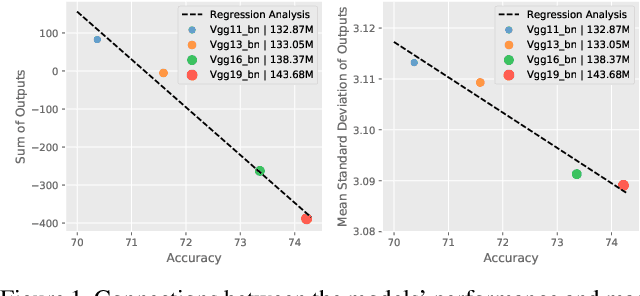
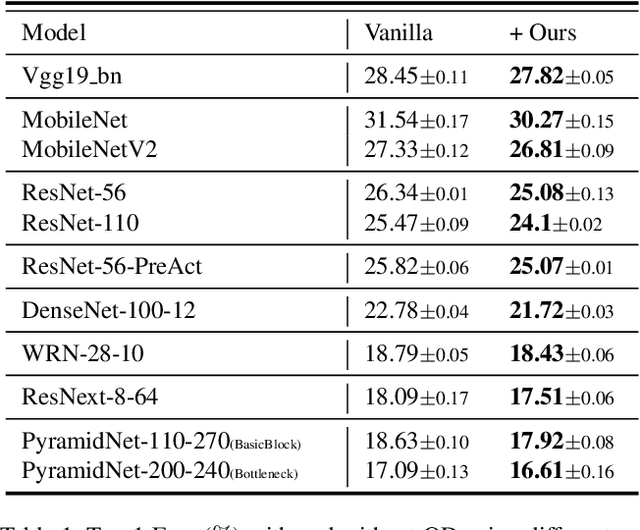
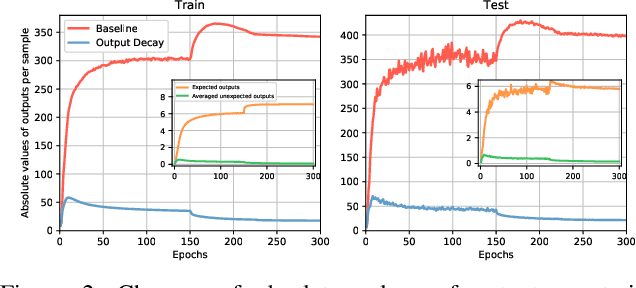

Regularization and data augmentation methods have been widely used and become increasingly indispensable in deep learning training. Researchers who devote themselves to this have considered various possibilities. But so far, there has been little discussion about regularizing outputs of the model. This paper begins with empirical observations that better performances are significantly associated with output distributions, that have smaller average values and variances. By audaciously assuming there is causality involved, we propose a novel regularization term, called Output Decay, that enforces the model to assign smaller and similar output values on each class. Though being counter-intuitive, such a small modification result in a remarkable improvement on performance. Extensive experiments demonstrate the wide applicability, versatility, and compatibility of Output Decay.