 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatureLM: Deciphering the Language of Nature for Scientific Discovery
Feb 11, 2025



Foundation models have revolutionized natural language processing and artificial intelligence, significantly enhancing how machines comprehend and generate human languages. Inspired by the success of these foundation models, researchers have developed foundation models for individual scientific domains, including small molecules, materials, proteins, DNA, and RNA. However, these models are typically trained in isolation, lacking the ability to integrate across different scientific domains. Recognizing that entities within these domains can all be represented as sequences, which together form the "language of nature", we introduce Nature Language Model (briefly, NatureLM), a sequence-based science foundation model designed for scientific discovery. Pre-trained with data from multiple scientific domains, NatureLM offers a unified, versatile model that enables various applications including: (i) generating and optimizing small molecules, proteins, RNA, and materials using text instructions; (ii) cross-domain generation/design, such as protein-to-molecule and protein-to-RNA generation; and (iii) achieving state-of-the-art performance in tasks like SMILES-to-IUPAC translation and retrosynthesis on USPTO-50k. NatureLM offers a promising generalist approach for various scientific tasks, including drug discovery (hit generation/optimization, ADMET optimization, synthesis), novel material design, and the development of therapeutic proteins or nucleotides. We have developed NatureLM models in different sizes (1 billion, 8 billion, and 46.7 billion parameters) and observed a clear improvement in performance as the model size increases.
PreMixer: MLP-Based Pre-training Enhanced MLP-Mixers for Large-scale Traffic Forecasting
Dec 18, 2024



In urban computing, precise and swift forecasting of multivariate time series data from traffic networks is crucial. This data incorporates additional spatial contexts such as sensor placements and road network layouts, and exhibits complex temporal patterns that amplify challenges for predictive learning in traffic management, smart mobility demand, and urban planning. Consequently, there is an increasing need to forecast traffic flow across broader geographic regions and for higher temporal coverage. However, current research encounters limitations because of the inherent inefficiency of model and their unsuitability for large-scale traffic network applications due to model complexity. This paper proposes a novel framework, named PreMixer, designed to bridge this gap. It features a predictive model and a pre-training mechanism, both based on the principles of Multi-Layer Perceptrons (MLP). The PreMixer comprehensively consider temporal dependencies of traffic patterns in different time windows and processes the spatial dynamics as well. Additionally, we integrate spatio-temporal positional encoding to manage spatiotemporal heterogeneity without relying on predefined graphs. Furthermore, our innovative pre-training model uses a simple patch-wise MLP to conduct masked time series modeling, learning from long-term historical data segmented into patches to generate enriched contextual representations. This approach enhances the downstream forecasting model without incurring significant time consumption or computational resource demands owing to improved learning efficiency and data handling flexibility. Our framework achieves comparable state-of-the-art performance while maintaining high computational efficiency, as verified by extensive experiments on large-scale traffic datasets.
HiMoE: Heterogeneity-Informed Mixture-of-Experts for Fair Spatial-Temporal Forecasting
Nov 30, 2024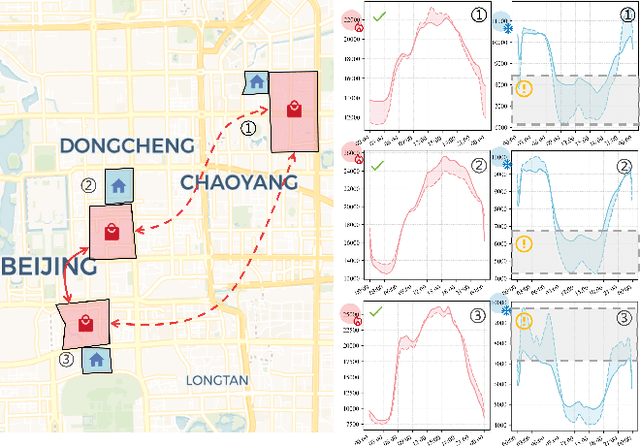

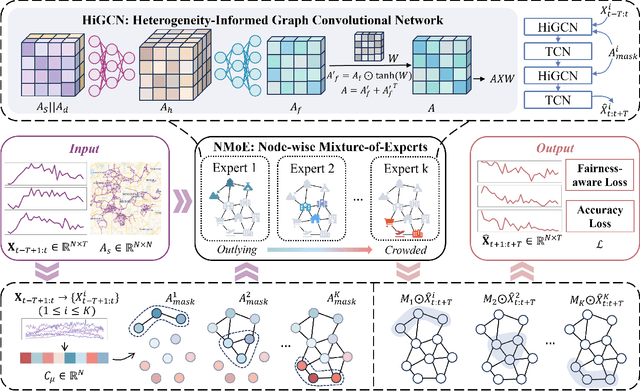
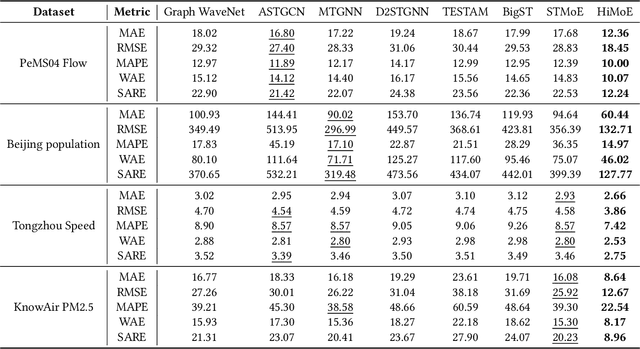
Spatial-temporal forecasting has various applications in transportation, climate, and human activity domains. Current spatial-temporal forecasting models primarily adopt a macro perspective, focusing on achieving strong overall prediction performance for the entire system. However, most of these models overlook the importance of enhancing the uniformity of prediction performance across different nodes, leading to poor prediction capabilities for certain nodes and rendering some results impractical. This task is particularly challenging due to the inherent heterogeneity of spatial-temporal data. To address this issue, in this paper, we propose a novel Heterogeneity-informed Mixture-of-Experts (HiMoE) for fair spatial-temporal forecasting. Specifically, we design a Heterogeneity-Informed Graph Convolutional Network (HiGCN), integrated into each expert model to enhance the flexibility of the experts. To adapt to the heterogeneity of spatial-temporal data, we design a Node-wise Mixture-of-Experts (NMoE). This model decouples the spatial-temporal prediction task into sub-tasks at the spatial scale, which are then assigned to different experts. To allocate these sub-tasks, we use a mean-based graph decoupling method to distinguish the graph structure for each expert. The results are then aggregated using an output gating mechanism based on a dense Mixture-of-Experts (dMoE). Additionally, fairness-aware loss and evaluation functions are proposed to train the model with uniformity and accuracy as objectives. Experiments conducted on four datasets, encompassing diverse data types and spatial scopes, validate HiMoE's ability to scale across various real-world scenarios. Furthermore, HiMoE consistently outperforms baseline models, achieving superior performance in both accuracy and uniformity.
Spatio-temporal neural structural causal models for bike flow prediction
Jan 19, 2023



As a representative of public transportation, the fundamental issue of managing bike-sharing systems is bike flow prediction. Recent methods overemphasize the spatio-temporal correlations in the data, ignoring the effects of contextual conditions on the transportation system and the inter-regional timevarying causality. In addition, due to the disturbance of incomplete observations in the data, random contextual conditions lead to spurious correlations between data and features, making the prediction of the model ineffective in special scenarios. To overcome this issue, we propose a Spatio-temporal Neural Structure Causal Model(STNSCM) from the perspective of causality. First, we build a causal graph to describe the traffic prediction, and further analyze the causal relationship between the input data, contextual conditions, spatiotemporal states, and prediction results. Second, we propose to apply the frontdoor criterion to eliminate confounding biases in the feature extraction process. Finally, we propose a counterfactual representation reasoning module to extrapolate the spatio-temporal state under the factual scenario to future counterfactual scenarios to improve the prediction performance. Experiments on real-world datasets demonstrate the superior performance of our model, especially its resistance to fluctuations caused by the external environment. The source code and data will be released.
Causal conditional hidden Markov model for multimodal traffic prediction
Jan 19, 2023



Multimodal traffic flow can reflect the health of the transportation system, and its prediction is crucial to urban traffic management. Recent works overemphasize spatio-temporal correlations of traffic flow, ignoring the physical concepts that lead to the generation of observations and their causal relationship. Spatio-temporal correlations are considered unstable under the influence of different conditions, and spurious correlations may exist in observations. In this paper, we analyze the physical concepts affecting the generation of multimode traffic flow from the perspective of the observation generation principle and propose a Causal Conditional Hidden Markov Model (CCHMM) to predict multimodal traffic flow. In the latent variables inference stage, a posterior network disentangles the causal representations of the concepts of interest from conditional information and observations, and a causal propagation module mines their causal relationship. In the data generation stage, a prior network samples the causal latent variables from the prior distribution and feeds them into the generator to generate multimodal traffic flow. We use a mutually supervised training method for the prior and posterior to enhance the identifiability of the model. Experiments on real-world datasets show that CCHMM can effectively disentangle causal representations of concepts of interest and identify causality, and accurately predict multimodal traffic flow.
Channel Self-Supervision for Online Knowledge Distillation
Mar 23, 2022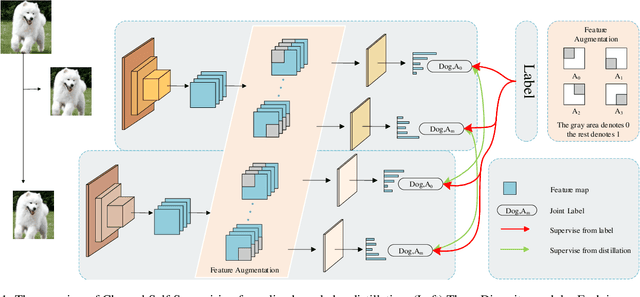
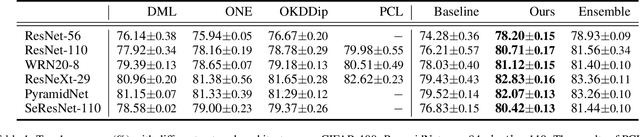
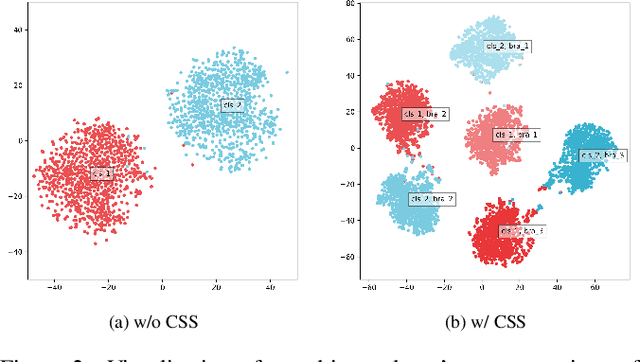
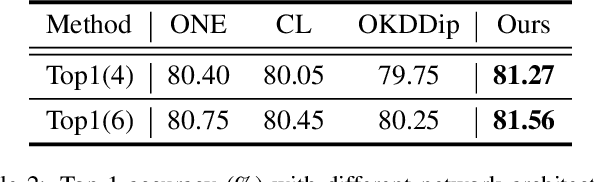
Recently, researchers have shown an increased interest in the online knowledge distillation. Adopting an one-stage and end-to-end training fashion, online knowledge distillation uses aggregated intermediated predictions of multiple peer models for training. However, the absence of a powerful teacher model may result in the homogeneity problem between group peers, affecting the effectiveness of group distillation adversely. In this paper, we propose a novel online knowledge distillation method, \textbf{C}hannel \textbf{S}elf-\textbf{S}upervision for Online Knowledge Distillation (CSS), which structures diversity in terms of input, target, and network to alleviate the homogenization problem. Specifically, we construct a dual-network multi-branch structure and enhance inter-branch diversity through self-supervised learning, adopting the feature-level transformation and augmenting the corresponding labels. Meanwhile, the dual network structure has a larger space of independent parameters to resist the homogenization problem during distillation. Extensive quantitative experiments on CIFAR-100 illustrate that our method provides greater diversity than OKDDip and we also give pretty performance improvement, even over the state-of-the-art such as PCL. The results on three fine-grained datasets (StanfordDogs, StanfordCars, CUB-200-211) also show the significant generalization capability of our approach.
Pre-training Co-evolutionary Protein Representation via A Pairwise Masked Language Model
Oct 29, 2021
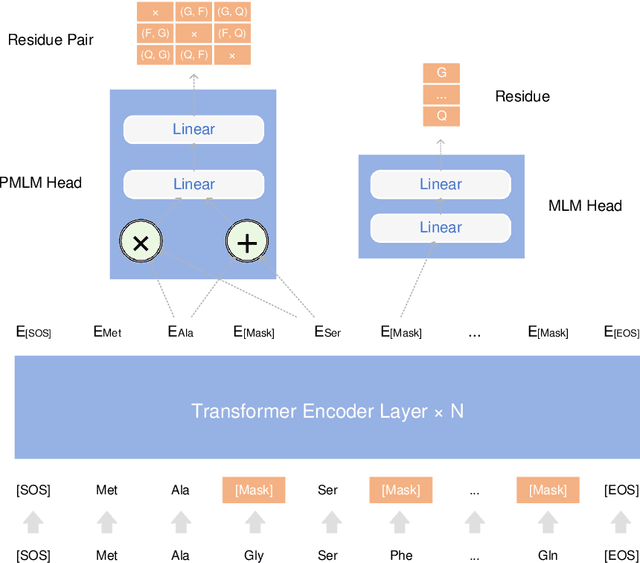
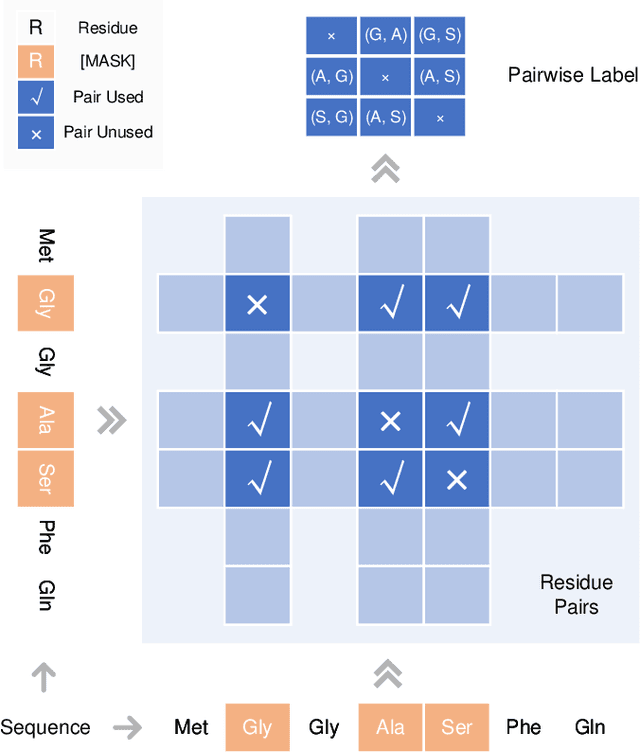

Understanding protein sequences is vital and urgent for biology, healthcare, and medicine. Labeling approaches are expensive yet time-consuming, while the amount of unlabeled data is increasing quite faster than that of the labeled data due to low-cost, high-throughput sequencing methods. In order to extract knowledge from these unlabeled data, representation learning is of significant value for protein-related tasks and has great potential for helping us learn more about protein functions and structures. The key problem in the protein sequence representation learning is to capture the co-evolutionary information reflected by the inter-residue co-variation in the sequences. Instead of leveraging multiple sequence alignment as is usually done, we propose a novel method to capture this information directly by pre-training via a dedicated language model, i.e., Pairwise Masked Language Model (PMLM). In a conventional masked language model, the masked tokens are modeled by conditioning on the unmasked tokens only, but processed independently to each other. However, our proposed PMLM takes the dependency among masked tokens into consideration, i.e., the probability of a token pair is not equal to the product of the probability of the two tokens. By applying this model, the pre-trained encoder is able to generate a better representation for protein sequences. Our result shows that the proposed method can effectively capture the inter-residue correlations and improves the performance of contact prediction by up to 9% compared to the MLM baseline under the same setting. The proposed model also significantly outperforms the MSA baseline by more than 7% on the TAPE contact prediction benchmark when pre-trained on a subset of the sequence database which the MSA is generated from, revealing the potential of the sequence pre-training method to surpass MSA based methods in general.
Assessing Attendance by Peer Information
Jun 06, 2021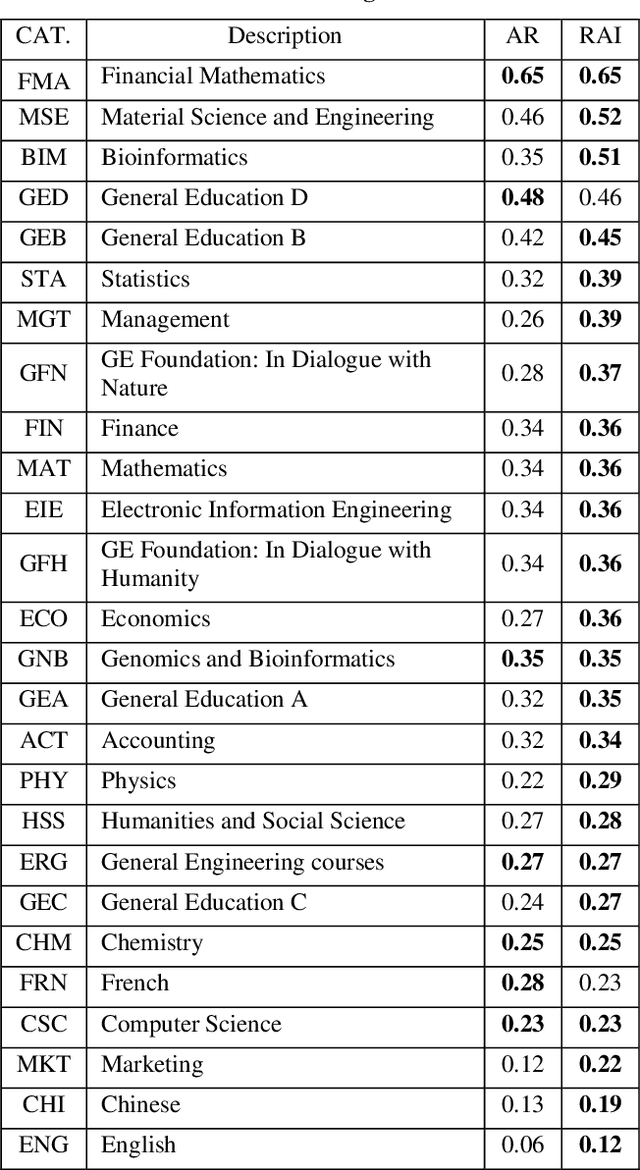
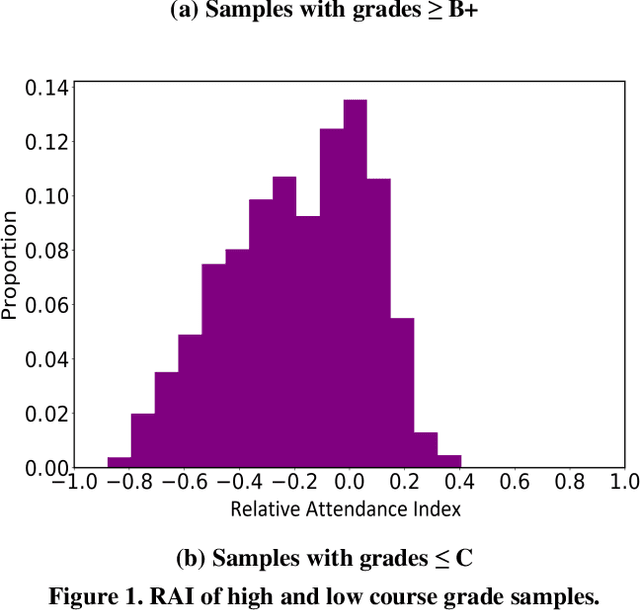
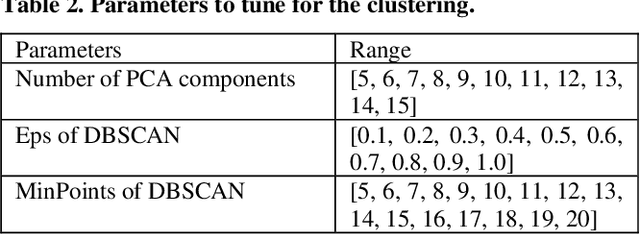
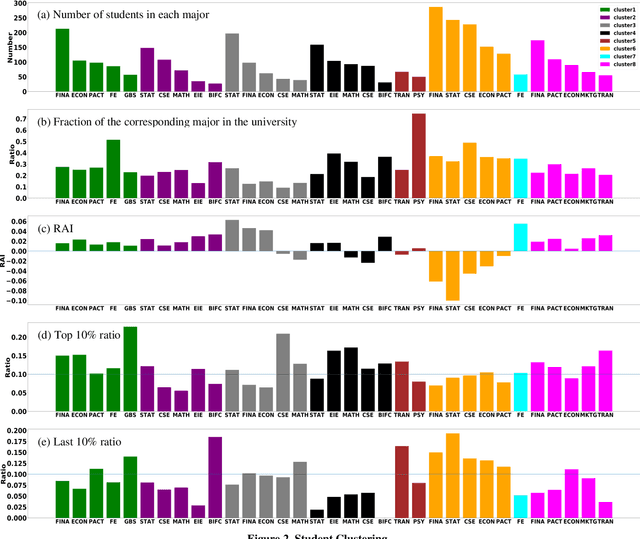
Attendance rate is an important indicator of students' study motivation, behavior and Psychological status; However, the heterogeneous nature of student attendance rates due to the course registration difference or the online/offline difference in a blended learning environment makes it challenging to compare attendance rates. In this paper, we propose a novel method called Relative Attendance Index (RAI) to measure attendance rates, which reflects students' efforts on attending courses. While traditional attendance focuses on the record of a single person or course, relative attendance emphasizes peer attendance information of relevant individuals or courses, making the comparisons of attendance more justified. Experimental results on real-life data show that RAI can indeed better reflect student engagement.
MLPerf Inference Benchmark
Nov 06, 2019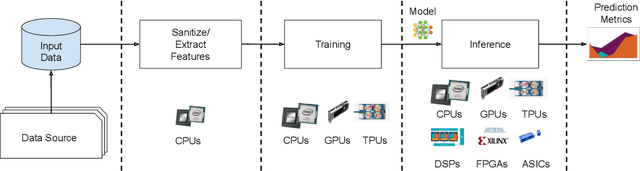
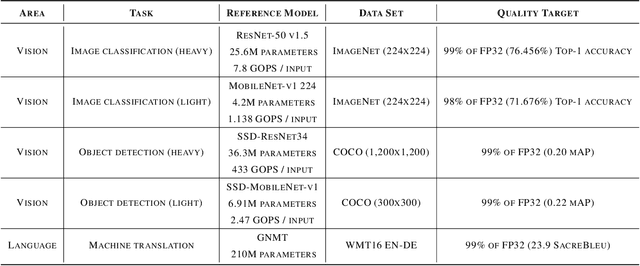
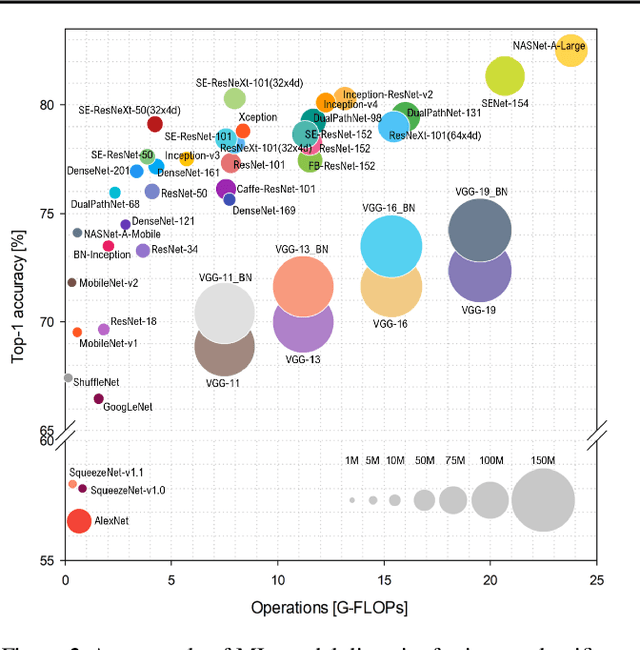
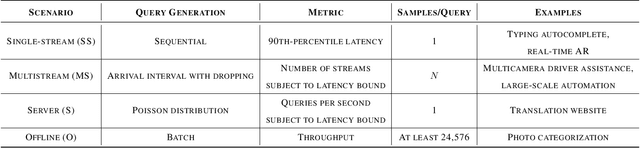
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.