 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Facts (Pix2Fact): Benchmarking Multi-Hop Reasoning for Fine-Grained Visual Fact Checking
Jan 31, 2026Despite progress on general tasks, VLMs struggle with challenges demanding both detailed visual grounding and deliberate knowledge-based reasoning, a synergy not captured by existing benchmarks that evaluate these skills separately. To close this gap, we introduce Pix2Fact, a new visual question-answering benchmark designed to evaluate expert-level perception and knowledge-intensive multi-hop reasoning. Pix2Fact contains 1,000 high-resolution (4K+) images spanning 8 daily-life scenarios and situations, with questions and answers meticulously crafted by annotators holding PhDs from top global universities working in partnership with a professional data annotation firm. Each question requires detailed visual grounding, multi-hop reasoning, and the integration of external knowledge to answer. Our evaluation of 9 state-of-the-art VLMs, including proprietary models like Gemini-3-Pro and GPT-5, reveals the substantial challenge posed by Pix2Fact: the most advanced model achieves only 24.0% average accuracy, in stark contrast to human performance of 56%. This significant gap underscores the limitations of current models in replicating human-level visual comprehension. We believe Pix2Fact will serve as a critical benchmark to drive the development of next-generation multimodal agents that combine fine-grained perception with robust, knowledge-based reasoning.
Collaborative-Distilled Diffusion Models (CDDM) for Accelerated and Lightweight Trajectory Prediction
Oct 01, 2025Trajectory prediction is a fundamental task in Autonomous Vehicles (AVs) and Intelligent Transportation Systems (ITS), supporting efficient motion planning and real-time traffic safety management. Diffusion models have recently demonstrated strong performance in probabilistic trajectory prediction, but their large model size and slow sampling process hinder real-world deployment. This paper proposes Collaborative-Distilled Diffusion Models (CDDM), a novel method for real-time and lightweight trajectory prediction. Built upon Collaborative Progressive Distillation (CPD), CDDM progressively transfers knowledge from a high-capacity teacher diffusion model to a lightweight student model, jointly reducing both the number of sampling steps and the model size across distillation iterations. A dual-signal regularized distillation loss is further introduced to incorporate guidance from both the teacher and ground-truth data, mitigating potential overfitting and ensuring robust performance. Extensive experiments on the ETH-UCY pedestrian benchmark and the nuScenes vehicle benchmark demonstrate that CDDM achieves state-of-the-art prediction accuracy. The well-distilled CDDM retains 96.2% and 95.5% of the baseline model's ADE and FDE performance on pedestrian trajectories, while requiring only 231K parameters and 4 or 2 sampling steps, corresponding to 161x compression, 31x acceleration, and 9 ms latency. Qualitative results further show that CDDM generates diverse and accurate trajectories under dynamic agent behaviors and complex social interactions. By bridging high-performing generative models with practical deployment constraints, CDDM enables resource-efficient probabilistic prediction for AVs and ITS. Code is available at https://github.com/bingzhangw/CDDM.
Independent Mobility GPT (IDM-GPT): A Self-Supervised Multi-Agent Large Language Model Framework for Customized Traffic Mobility Analysis Using Machine Learning Models
Feb 25, 2025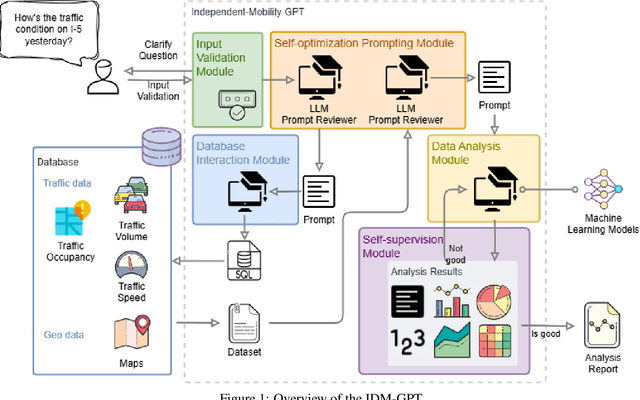



With the urbanization process, an increasing number of sensors are being deployed in transportation systems, leading to an explosion of big data. To harness the power of this vast transportation data, various machine learning (ML) and artificial intelligence (AI) methods have been introduced to address numerous transportation challenges. However, these methods often require significant investment in data collection, processing, storage, and the employment of professionals with expertise in transportation and ML. Additionally, privacy issues are a major concern when processing data for real-world traffic control and management. To address these challenges, the research team proposes an innovative Multi-agent framework named Independent Mobility GPT (IDM-GPT) based on large language models (LLMs) for customized traffic analysis, management suggestions, and privacy preservation. IDM-GPT efficiently connects users, transportation databases, and ML models economically. IDM-GPT trains, customizes, and applies various LLM-based AI agents for multiple functions, including user query comprehension, prompts optimization, data analysis, model selection, and performance evaluation and enhancement. With IDM-GPT, users without any background in transportation or ML can efficiently and intuitively obtain data analysis and customized suggestions in near real-time based on their questions. Experimental results demonstrate that IDM-GPT delivers satisfactory performance across multiple traffic-related tasks, providing comprehensive and actionable insights that support effective traffic management and urban mobility improvement.
PreMixer: MLP-Based Pre-training Enhanced MLP-Mixers for Large-scale Traffic Forecasting
Dec 18, 2024



In urban computing, precise and swift forecasting of multivariate time series data from traffic networks is crucial. This data incorporates additional spatial contexts such as sensor placements and road network layouts, and exhibits complex temporal patterns that amplify challenges for predictive learning in traffic management, smart mobility demand, and urban planning. Consequently, there is an increasing need to forecast traffic flow across broader geographic regions and for higher temporal coverage. However, current research encounters limitations because of the inherent inefficiency of model and their unsuitability for large-scale traffic network applications due to model complexity. This paper proposes a novel framework, named PreMixer, designed to bridge this gap. It features a predictive model and a pre-training mechanism, both based on the principles of Multi-Layer Perceptrons (MLP). The PreMixer comprehensively consider temporal dependencies of traffic patterns in different time windows and processes the spatial dynamics as well. Additionally, we integrate spatio-temporal positional encoding to manage spatiotemporal heterogeneity without relying on predefined graphs. Furthermore, our innovative pre-training model uses a simple patch-wise MLP to conduct masked time series modeling, learning from long-term historical data segmented into patches to generate enriched contextual representations. This approach enhances the downstream forecasting model without incurring significant time consumption or computational resource demands owing to improved learning efficiency and data handling flexibility. Our framework achieves comparable state-of-the-art performance while maintaining high computational efficiency, as verified by extensive experiments on large-scale traffic datasets.
RAPQ: Rescuing Accuracy for Power-of-Two Low-bit Post-training Quantization
Apr 26, 2022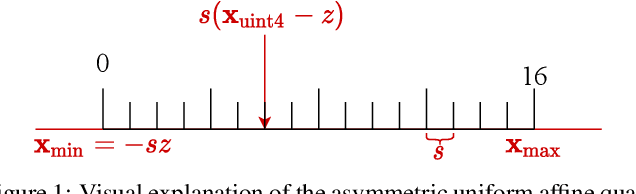
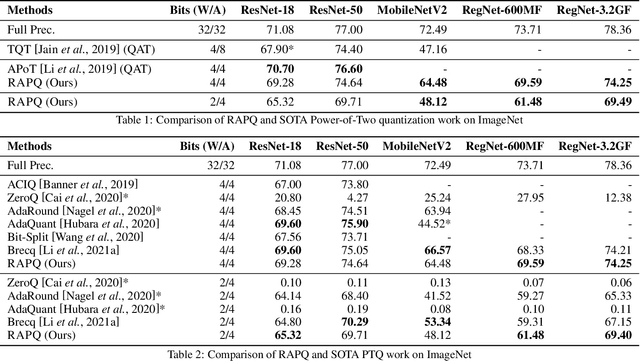
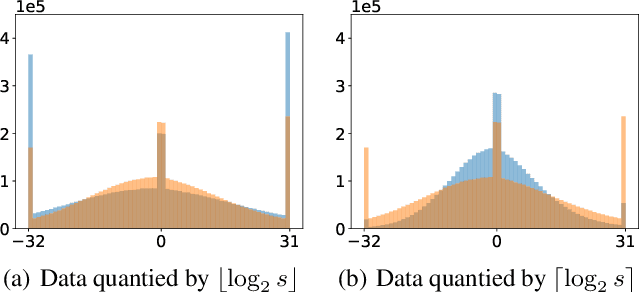
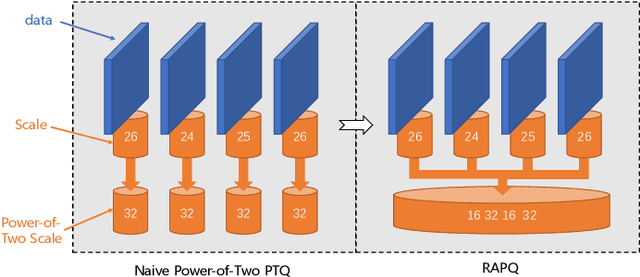
We introduce a Power-of-Two post-training quantization( PTQ) method for deep neural network that meets hardware requirements and does not call for long-time retraining. PTQ requires a small set of calibration data and is easier for deployment, but results in lower accuracy than Quantization-Aware Training( QAT). Power-of-Two quantization can convert the multiplication introduced by quantization and dequantization to bit-shift that is adopted by many efficient accelerators. However, the Power-of-Two scale has fewer candidate values, which leads to more rounding or clipping errors. We propose a novel Power-of-Two PTQ framework, dubbed RAPQ, which dynamically adjusts the Power-of-Two scales of the whole network instead of statically determining them layer by layer. It can theoretically trade off the rounding error and clipping error of the whole network. Meanwhile, the reconstruction method in RAPQ is based on the BN information of every unit. Extensive experiments on ImageNet prove the excellent performance of our proposed method. Without bells and whistles, RAPQ can reach accuracy of 65% and 48% on ResNet-18 and MobileNetV2 respectively with weight INT2 activation INT4. We are the first to propose PTQ for the more constrained but hardware-friendly Power-of-Two quantization and prove that it can achieve nearly the same accuracy as SOTA PTQ method. The code will be released.