 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAPQ: Rescuing Accuracy for Power-of-Two Low-bit Post-training Quantization
Apr 26, 2022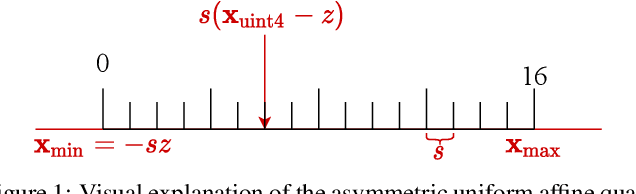
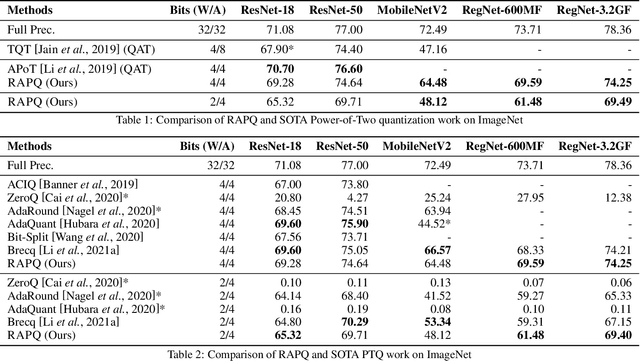
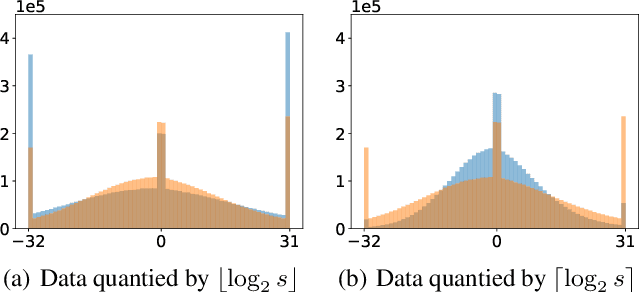
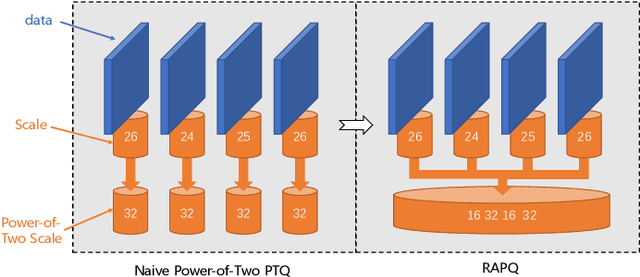
We introduce a Power-of-Two post-training quantization( PTQ) method for deep neural network that meets hardware requirements and does not call for long-time retraining. PTQ requires a small set of calibration data and is easier for deployment, but results in lower accuracy than Quantization-Aware Training( QAT). Power-of-Two quantization can convert the multiplication introduced by quantization and dequantization to bit-shift that is adopted by many efficient accelerators. However, the Power-of-Two scale has fewer candidate values, which leads to more rounding or clipping errors. We propose a novel Power-of-Two PTQ framework, dubbed RAPQ, which dynamically adjusts the Power-of-Two scales of the whole network instead of statically determining them layer by layer. It can theoretically trade off the rounding error and clipping error of the whole network. Meanwhile, the reconstruction method in RAPQ is based on the BN information of every unit. Extensive experiments on ImageNet prove the excellent performance of our proposed method. Without bells and whistles, RAPQ can reach accuracy of 65% and 48% on ResNet-18 and MobileNetV2 respectively with weight INT2 activation INT4. We are the first to propose PTQ for the more constrained but hardware-friendly Power-of-Two quantization and prove that it can achieve nearly the same accuracy as SOTA PTQ method. The code will be released.
AdaPruner: Adaptive Channel Pruning and Effective Weights Inheritance
Sep 14, 2021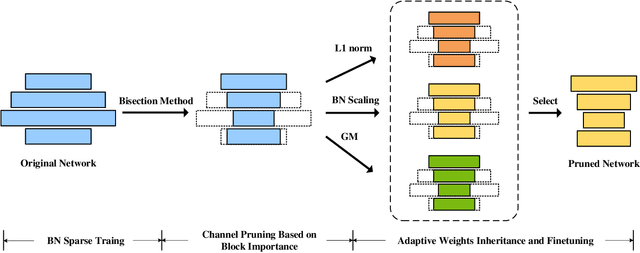
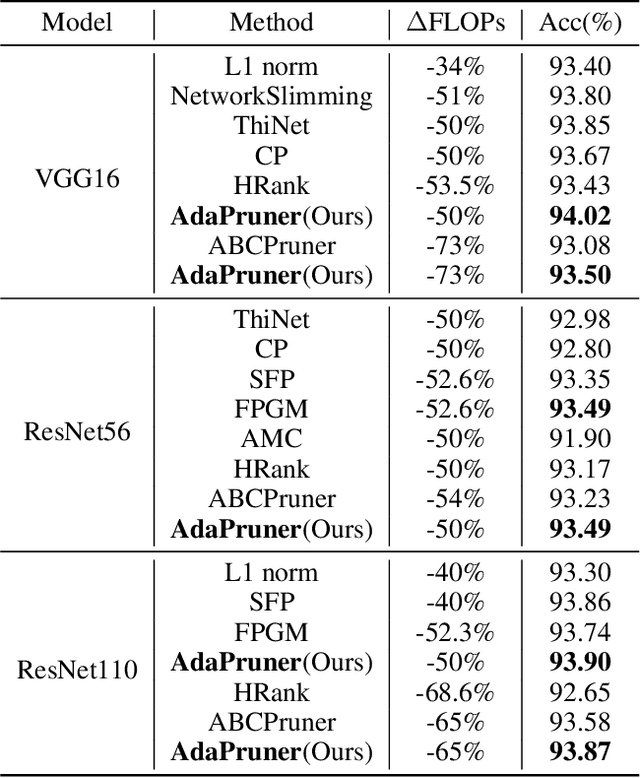
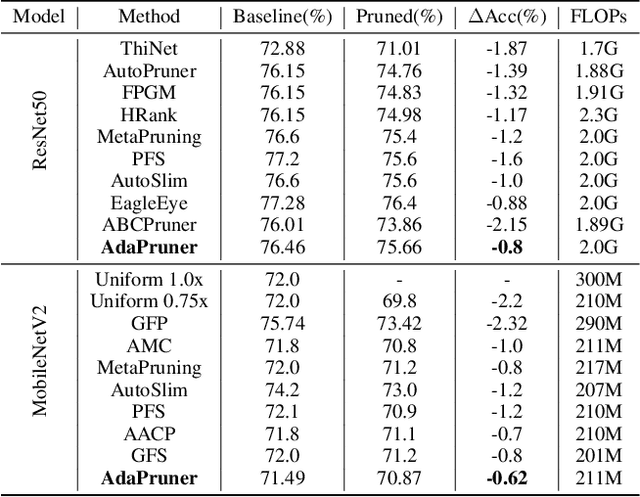
Channel pruning is one of the major compression approaches for deep neural networks. While previous pruning methods have mostly focused on identifying unimportant channels, channel pruning is considered as a special case of neural architecture search in recent years. However, existing methods are either complicated or prone to sub-optimal pruning. In this paper, we propose a pruning framework that adaptively determines the number of each layer's channels as well as the wights inheritance criteria for sub-network. Firstly, evaluate the importance of each block in the network based on the mean of the scaling parameters of the BN layers. Secondly, use the bisection method to quickly find the compact sub-network satisfying the budget. Finally, adaptively and efficiently choose the weight inheritance criterion that fits the current architecture and fine-tune the pruned network to recover performance. AdaPruner allows to obtain pruned network quickly, accurately and efficiently, taking into account both the structure and initialization weights. We prune the currently popular CNN models (VGG, ResNet, MobileNetV2) on different image classification datasets, and the experimental results demonstrate the effectiveness of our proposed method. On ImageNet, we reduce 32.8% FLOPs of MobileNetV2 with only 0.62% decrease for top-1 accuracy, which exceeds all previous state-of-the-art channel pruning methods. The code will be released.