 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectroscopy-Guided Discovery of Three-Dimensional Structures of Disordered Materials with Diffusion Models
Dec 09, 2023



The ability to rapidly develop materials with desired properties has a transformative impact on a broad range of emerging technologies. In this work, we introduce a new framework based on the diffusion model, a recent generative machine learning method to predict 3D structures of disordered materials from a target property. For demonstration, we apply the model to identify the atomic structures of amorphous carbons ($a$-C) as a representative material system from the target X-ray absorption near edge structure (XANES) spectra--a common experimental technique to probe atomic structures of materials. We show that conditional generation guided by XANES spectra reproduces key features of the target structures. Furthermore, we show that our model can steer the generative process to tailor atomic arrangements for a specific XANES spectrum. Finally, our generative model exhibits a remarkable scale-agnostic property, thereby enabling generation of realistic, large-scale structures through learning from a small-scale dataset (i.e., with small unit cells). Our work represents a significant stride in bridging the gap between materials characterization and atomic structure determination; in addition, it can be leveraged for materials discovery in exploring various material properties as targeted.
Razor SNN: Efficient Spiking Neural Network with Temporal Embeddings
Jun 30, 2023The event streams generated by dynamic vision sensors (DVS) are sparse and non-uniform in the spatial domain, while still dense and redundant in the temporal domain. Although spiking neural network (SNN), the event-driven neuromorphic model, has the potential to extract spatio-temporal features from the event streams, it is not effective and efficient. Based on the above, we propose an events sparsification spiking framework dubbed as Razor SNN, pruning pointless event frames progressively. Concretely, we extend the dynamic mechanism based on the global temporal embeddings, reconstruct the features, and emphasize the events effect adaptively at the training stage. During the inference stage, eliminate fruitless frames hierarchically according to a binary mask generated by the trained temporal embeddings. Comprehensive experiments demonstrate that our Razor SNN achieves competitive performance consistently on four events-based benchmarks: DVS 128 Gesture, N-Caltech 101, CIFAR10-DVS and SHD.
Masked Contrastive Pre-Training for Efficient Video-Text Retrieval
Dec 05, 2022



We present a simple yet effective end-to-end Video-language Pre-training (VidLP) framework, Masked Contrastive Video-language Pretraining (MAC), for video-text retrieval tasks. Our MAC aims to reduce video representation's spatial and temporal redundancy in the VidLP model by a mask sampling mechanism to improve pre-training efficiency. Comparing conventional temporal sparse sampling, we propose to randomly mask a high ratio of spatial regions and only feed visible regions into the encoder as sparse spatial sampling. Similarly, we adopt the mask sampling technique for text inputs for consistency. Instead of blindly applying the mask-then-prediction paradigm from MAE, we propose a masked-then-alignment paradigm for efficient video-text alignment. The motivation is that video-text retrieval tasks rely on high-level alignment rather than low-level reconstruction, and multimodal alignment with masked modeling encourages the model to learn a robust and general multimodal representation from incomplete and unstable inputs. Coupling these designs enables efficient end-to-end pre-training: reduce FLOPs (60% off), accelerate pre-training (by 3x), and improve performance. Our MAC achieves state-of-the-art results on various video-text retrieval datasets, including MSR-VTT, DiDeMo, and ActivityNet. Our approach is omnivorous to input modalities. With minimal modifications, we achieve competitive results on image-text retrieval tasks.
AdaPruner: Adaptive Channel Pruning and Effective Weights Inheritance
Sep 14, 2021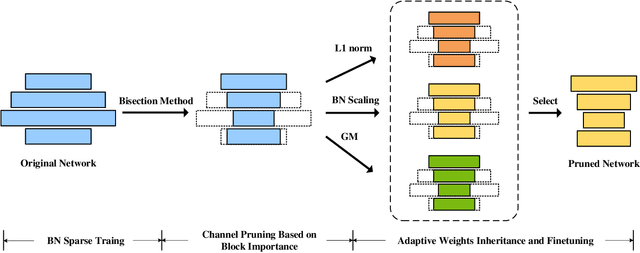
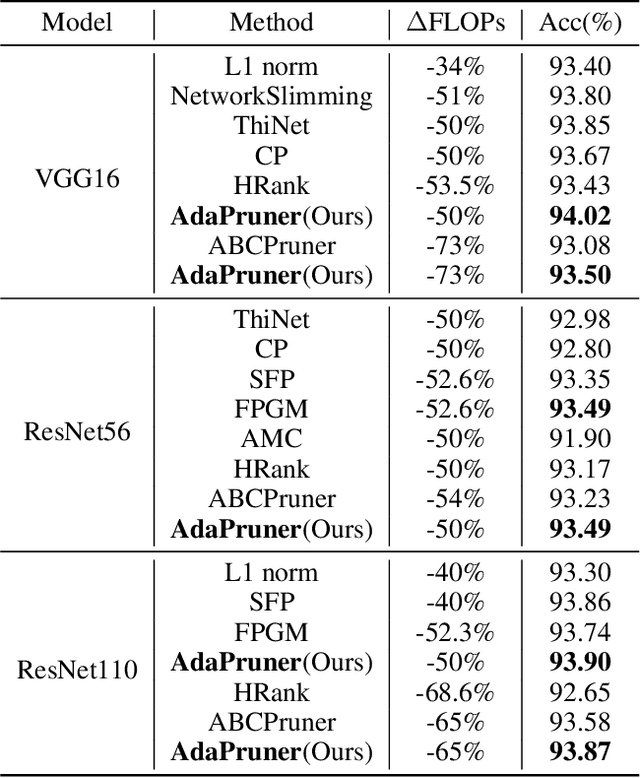
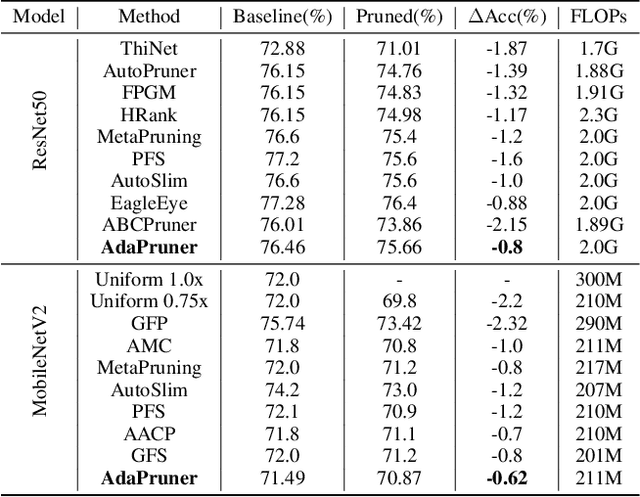
Channel pruning is one of the major compression approaches for deep neural networks. While previous pruning methods have mostly focused on identifying unimportant channels, channel pruning is considered as a special case of neural architecture search in recent years. However, existing methods are either complicated or prone to sub-optimal pruning. In this paper, we propose a pruning framework that adaptively determines the number of each layer's channels as well as the wights inheritance criteria for sub-network. Firstly, evaluate the importance of each block in the network based on the mean of the scaling parameters of the BN layers. Secondly, use the bisection method to quickly find the compact sub-network satisfying the budget. Finally, adaptively and efficiently choose the weight inheritance criterion that fits the current architecture and fine-tune the pruned network to recover performance. AdaPruner allows to obtain pruned network quickly, accurately and efficiently, taking into account both the structure and initialization weights. We prune the currently popular CNN models (VGG, ResNet, MobileNetV2) on different image classification datasets, and the experimental results demonstrate the effectiveness of our proposed method. On ImageNet, we reduce 32.8% FLOPs of MobileNetV2 with only 0.62% decrease for top-1 accuracy, which exceeds all previous state-of-the-art channel pruning methods. The code will be released.
An Once-for-All Budgeted Pruning Framework for ConvNets Considering Input Resolution
Dec 02, 2020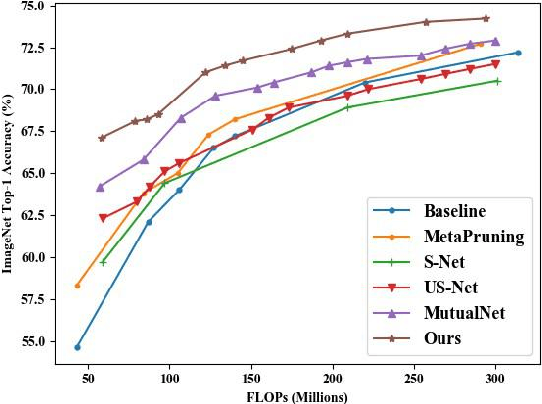

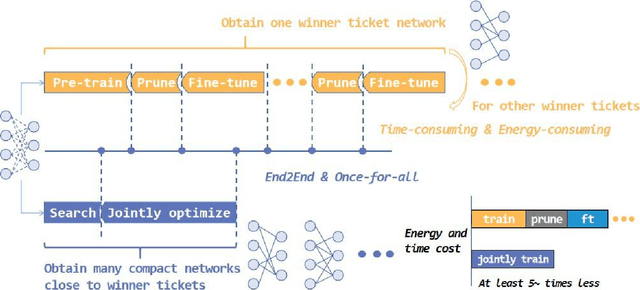
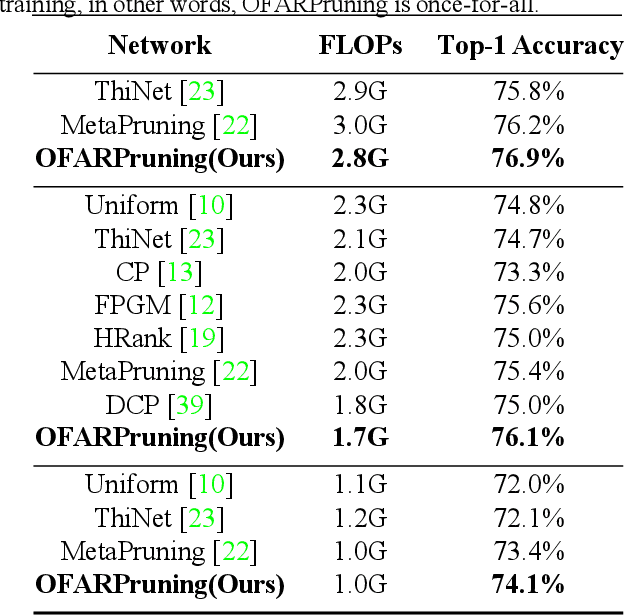
We propose an efficient once-for-all budgeted pruning framework (OFARPruning) to find many compact network structures close to winner tickets in the early training stage considering the effect of input resolution during the pruning process. In structure searching stage, we utilize cosine similarity to measure the similarity of the pruning mask to get high-quality network structures with low energy and time consumption. After structure searching stage, our proposed method randomly sample the compact structures with different pruning rates and input resolution to achieve joint optimization. Ultimately, we can obtain a cohort of compact networks adaptive to various resolution to meet dynamic FLOPs constraints on different edge devices with only once training. The experiments based on image classification and object detection show that OFARPruning has a higher accuracy than the once-for-all compression methods such as US-Net and MutualNet (1-2% better with less FLOPs), and achieve the same even higher accuracy as the conventional pruning methods (72.6% vs. 70.5% on MobileNetv2 under 170 MFLOPs) with much higher efficiency.
Layer Pruning via Fusible Residual Convolutional Block for Deep Neural Networks
Nov 29, 2020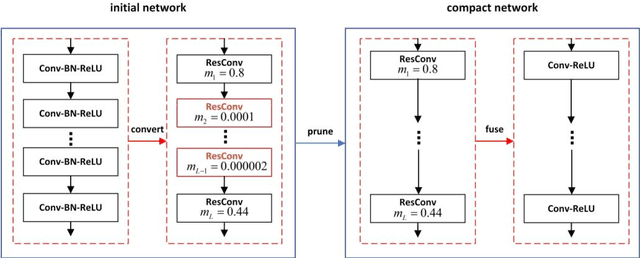
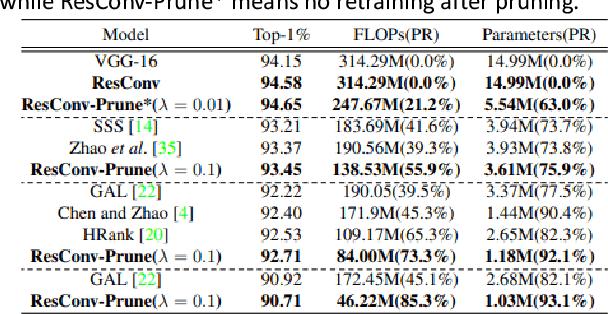
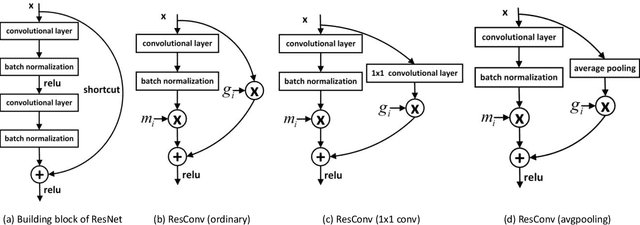
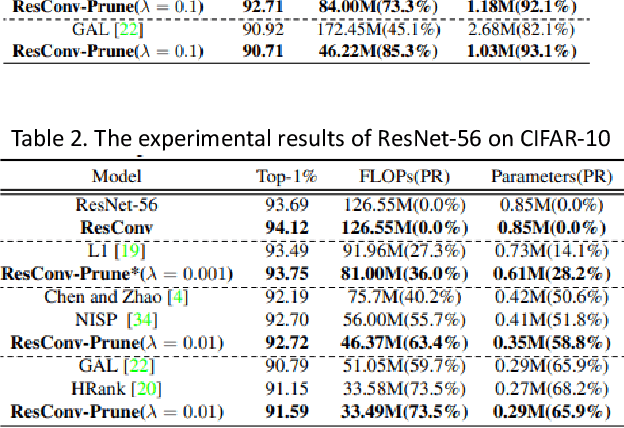
In order to deploy deep convolutional neural networks (CNNs) on resource-limited devices, many model pruning methods for filters and weights have been developed, while only a few to layer pruning. However, compared with filter pruning and weight pruning, the compact model obtained by layer pruning has less inference time and run-time memory usage when the same FLOPs and number of parameters are pruned because of less data moving in memory. In this paper, we propose a simple layer pruning method using fusible residual convolutional block (ResConv), which is implemented by inserting shortcut connection with a trainable information control parameter into a single convolutional layer. Using ResConv structures in training can improve network accuracy and train deep plain networks, and adds no additional computation during inference process because ResConv is fused to be an ordinary convolutional layer after training. For layer pruning, we convert convolutional layers of network into ResConv with a layer scaling factor. In the training process, the L1 regularization is adopted to make the scaling factors sparse, so that unimportant layers are automatically identified and then removed, resulting in a model of layer reduction. Our pruning method achieves excellent performance of compression and acceleration over the state-of-the-arts on different datasets, and needs no retraining in the case of low pruning rate. For example, with ResNet-110, we achieve a 65.5%-FLOPs reduction by removing 55.5% of the parameters, with only a small loss of 0.13% in top-1 accuracy on CIFAR-10.
Adaptive Structured Sparse Network for Efficient CNNs with Feature Regularization
Oct 21, 2020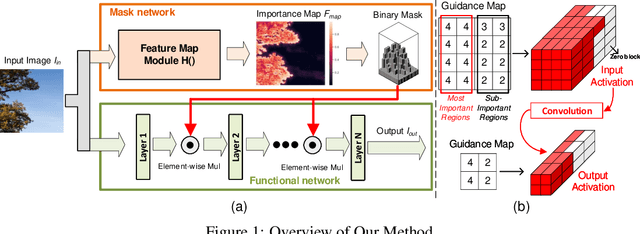
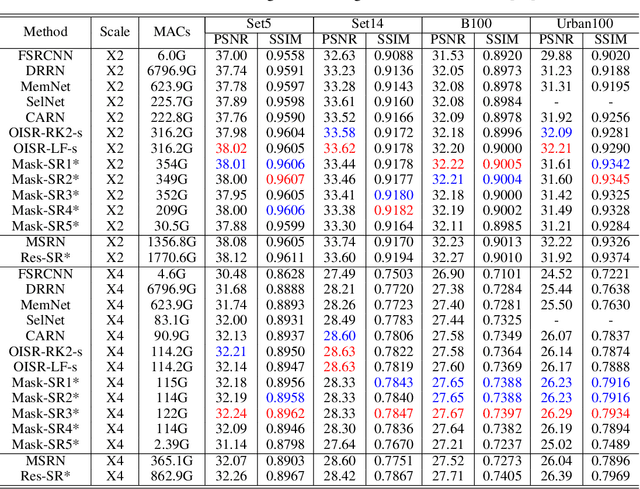
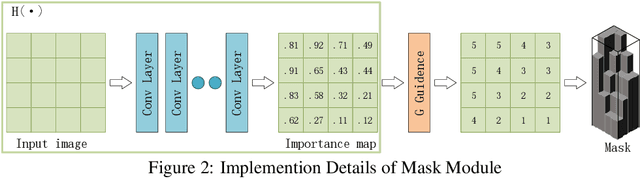
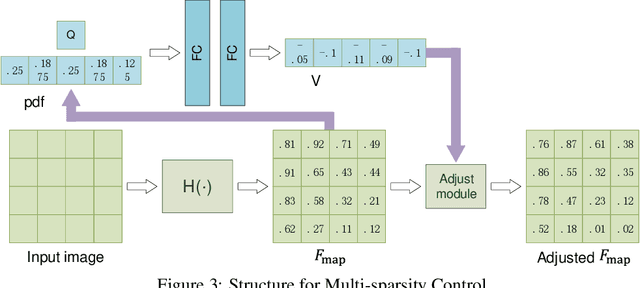
Neural networks have made great progress in pixel to pixel image processing tasks, e.g. super resolution, style transfer and image denoising. However, recent algorithms have a tendency to be too structurally complex to deploy on embedded systems. Traditional accelerating methods fix the options for pruning network weights to produce unstructured or structured sparsity. Many of them lack flexibility for different inputs. In this paper, we propose a Feature Regularization method that can generate input-dependent structured sparsity for hidden features. Our method can improve sparsity level in intermediate features by 60% to over 95% through pruning along the channel dimension for each pixel, thus relieving the computational and memory burden. On BSD100 dataset, the multiply-accumulate operations can be reduced by over 80% for super resolution tasks. In addition, we propose a method to quantitatively control the level of sparsity and design a way to train one model that supports multi-sparsity. We identify the effectiveness of our method for pixel to pixel tasks by qualitative theoretical analysis and experiments.
AIM 2019 Challenge on Constrained Super-Resolution: Methods and Results
Nov 04, 2019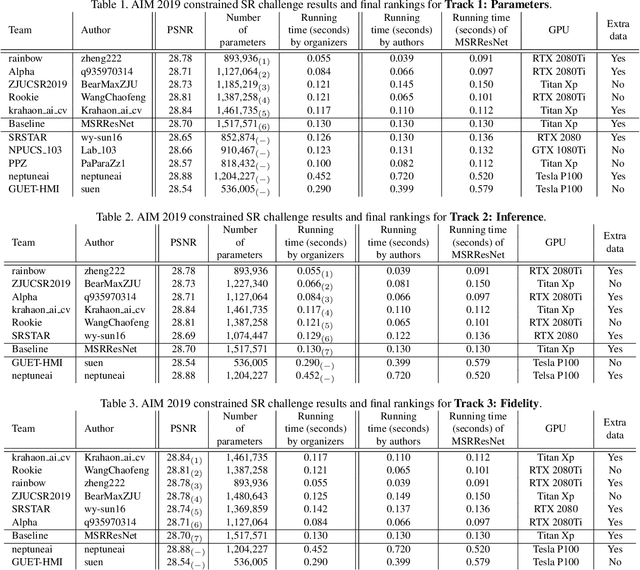
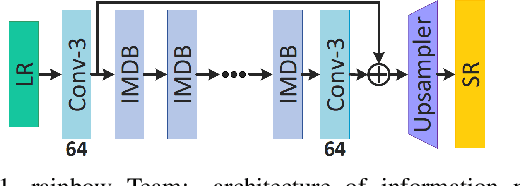
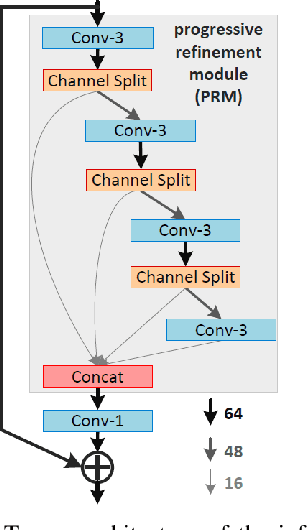
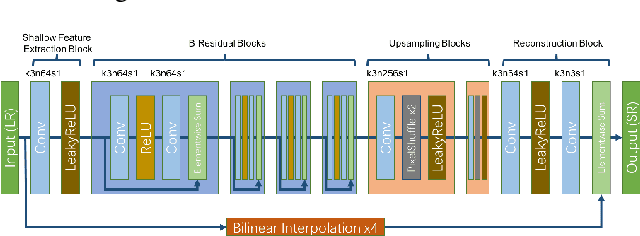
This paper reviews the AIM 2019 challenge on constrained example-based single image super-resolution with focus on proposed solutions and results. The challenge had 3 tracks. Taking the three main aspects (i.e., number of parameters, inference/running time, fidelity (PSNR)) of MSRResNet as the baseline, Track 1 aims to reduce the amount of parameters while being constrained to maintain or improve the running time and the PSNR result, Tracks 2 and 3 aim to optimize running time and PSNR result with constrain of the other two aspects, respectively. Each track had an average of 64 registered participants, and 12 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.