 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoESD: Unveil Speculative Decoding's Potential for Accelerating Sparse MoE
May 26, 2025Large Language Models (LLMs) have achieved remarkable success across many applications, with Mixture of Experts (MoE) models demonstrating great potential. Compared to traditional dense models, MoEs achieve better performance with less computation. Speculative decoding (SD) is a widely used technique to accelerate LLM inference without accuracy loss, but it has been considered efficient only for dense models. In this work, we first demonstrate that, under medium batch sizes, MoE surprisingly benefits more from SD than dense models. Furthermore, as MoE becomes sparser -- the prevailing trend in MoE designs -- the batch size range where SD acceleration is expected to be effective becomes broader. To quantitatively understand tradeoffs involved in SD, we develop a reliable modeling based on theoretical analyses. While current SD research primarily focuses on improving acceptance rates of algorithms, changes in workload and model architecture can still lead to degraded SD acceleration even with high acceptance rates. To address this limitation, we introduce a new metric 'target efficiency' that characterizes these effects, thus helping researchers identify system bottlenecks and understand SD acceleration more comprehensively. For scenarios like private serving, this work unveils a new perspective to speed up MoE inference, where existing solutions struggle. Experiments on different GPUs show up to 2.29x speedup for Qwen2-57B-A14B at medium batch sizes and validate our theoretical predictions.
A 65nm 8b-Activation 8b-Weight SRAM-Based Charge-Domain Computing-in-Memory Macro Using A Fully-Parallel Analog Adder Network and A Single-ADC Interface
Nov 23, 2022



Performing data-intensive tasks in the von Neumann architecture is challenging to achieve both high performance and power efficiency due to the memory wall bottleneck. Computing-in-memory (CiM) is a promising mitigation approach by enabling parallel in-situ multiply-accumulate (MAC) operations within the memory with support from the peripheral interface and datapath. SRAM-based charge-domain CiM (CD-CiM) has shown its potential of enhanced power efficiency and computing accuracy. However, existing SRAM-based CD-CiM faces scaling challenges to meet the throughput requirement of high-performance multi-bit-quantization applications. This paper presents an SRAM-based high-throughput ReLU-optimized CD-CiM macro. It is capable of completing MAC and ReLU of two signed 8b vectors in one CiM cycle with only one A/D conversion. Along with non-linearity compensation for the analog computing and A/D conversion interfaces, this work achieves 51.2GOPS throughput and 10.3TOPS/W energy efficiency, while showing 88.6% accuracy in the CIFAR-10 dataset.
Block-Wise Dynamic-Precision Neural Network Training Acceleration via Online Quantization Sensitivity Analytics
Oct 31, 2022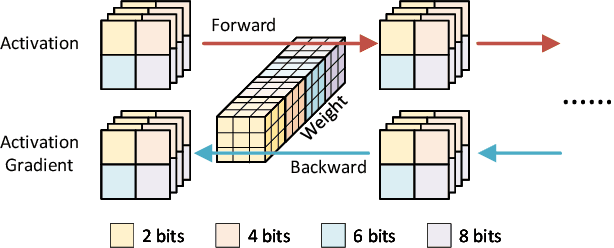
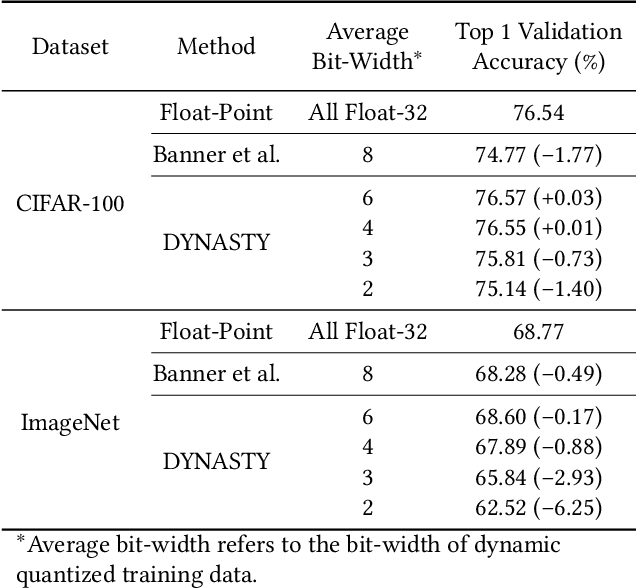
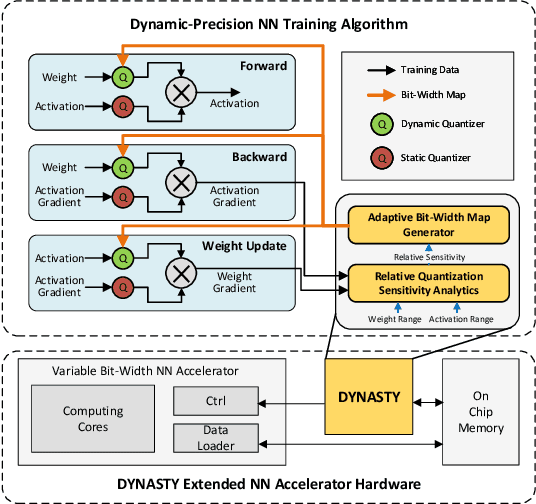
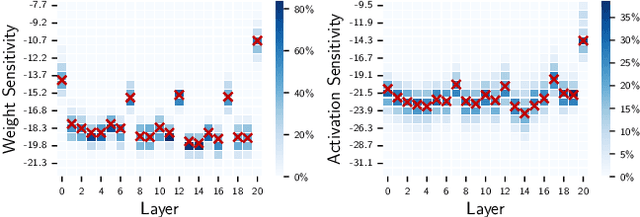
Data quantization is an effective method to accelerate neural network training and reduce power consumption. However, it is challenging to perform low-bit quantized training: the conventional equal-precision quantization will lead to either high accuracy loss or limited bit-width reduction, while existing mixed-precision methods offer high compression potential but failed to perform accurate and efficient bit-width assignment. In this work, we propose DYNASTY, a block-wise dynamic-precision neural network training framework. DYNASTY provides accurate data sensitivity information through fast online analytics, and maintains stable training convergence with an adaptive bit-width map generator. Network training experiments on CIFAR-100 and ImageNet dataset are carried out, and compared to 8-bit quantization baseline, DYNASTY brings up to $5.1\times$ speedup and $4.7\times$ energy consumption reduction with no accuracy drop and negligible hardware overhead.
SEFormer: Structure Embedding Transformer for 3D Object Detection
Sep 05, 2022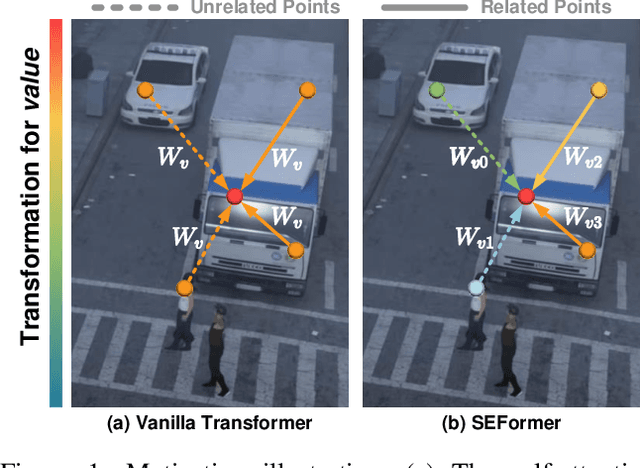
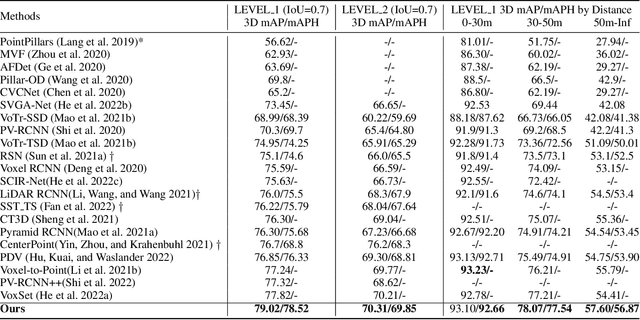
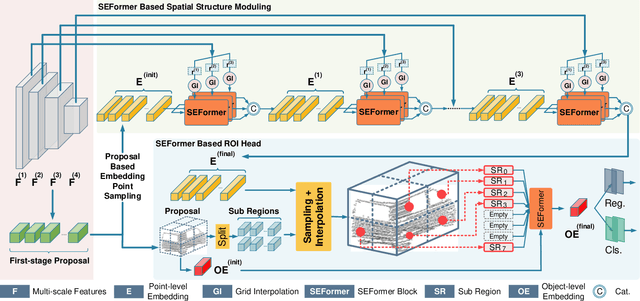
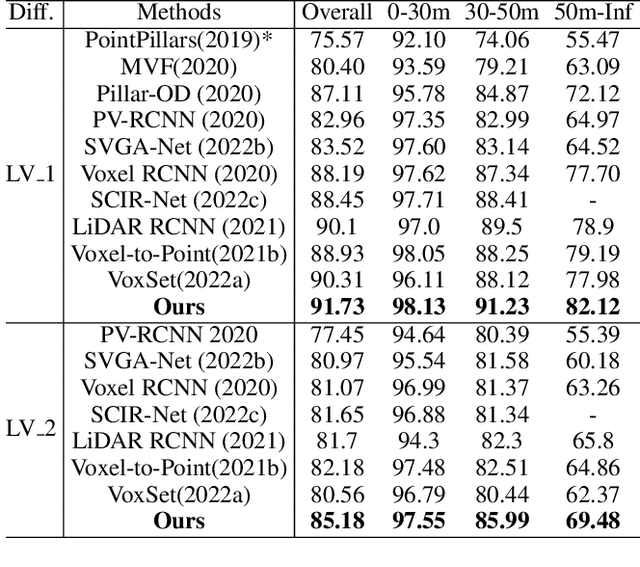
Effectively preserving and encoding structure features from objects in irregular and sparse LiDAR points is a key challenge to 3D object detection on point cloud. Recently, Transformer has demonstrated promising performance on many 2D and even 3D vision tasks. Compared with the fixed and rigid convolution kernels, the self-attention mechanism in Transformer can adaptively exclude the unrelated or noisy points and thus suitable for preserving the local spatial structure in irregular LiDAR point cloud. However, Transformer only performs a simple sum on the point features, based on the self-attention mechanism, and all the points share the same transformation for value. Such isotropic operation lacks the ability to capture the direction-distance-oriented local structure which is important for 3D object detection. In this work, we propose a Structure-Embedding transFormer (SEFormer), which can not only preserve local structure as traditional Transformer but also have the ability to encode the local structure. Compared to the self-attention mechanism in traditional Transformer, SEFormer learns different feature transformations for value points based on the relative directions and distances to the query point. Then we propose a SEFormer based network for high-performance 3D object detection. Extensive experiments show that the proposed architecture can achieve SOTA results on Waymo Open Dataset, the largest 3D detection benchmark for autonomous driving. Specifically, SEFormer achieves 79.02% mAP, which is 1.2% higher than existing works. We will release the codes.
Adaptive Structured Sparse Network for Efficient CNNs with Feature Regularization
Oct 21, 2020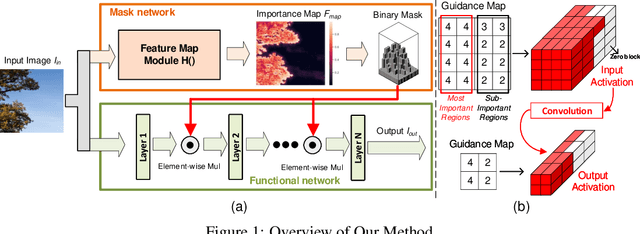
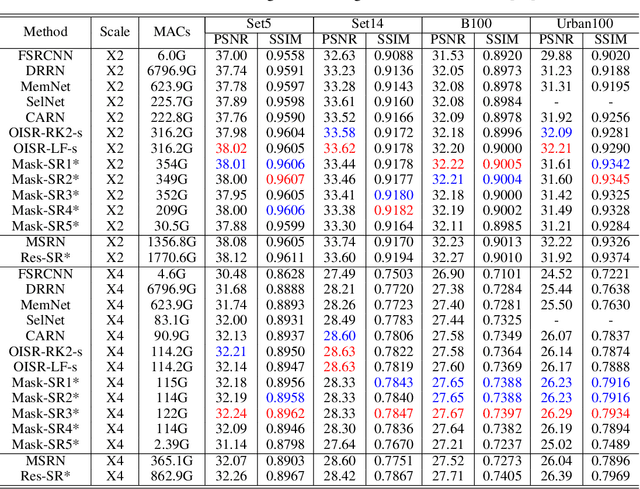
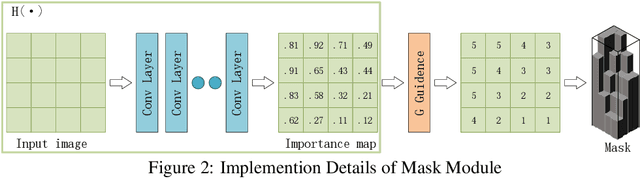
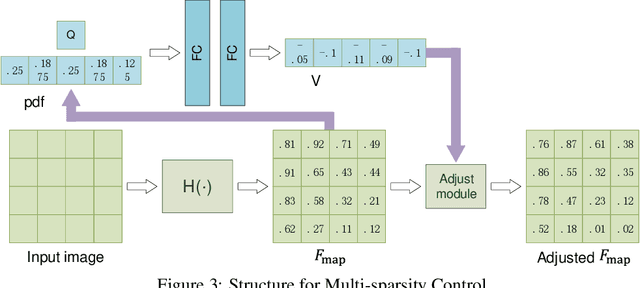
Neural networks have made great progress in pixel to pixel image processing tasks, e.g. super resolution, style transfer and image denoising. However, recent algorithms have a tendency to be too structurally complex to deploy on embedded systems. Traditional accelerating methods fix the options for pruning network weights to produce unstructured or structured sparsity. Many of them lack flexibility for different inputs. In this paper, we propose a Feature Regularization method that can generate input-dependent structured sparsity for hidden features. Our method can improve sparsity level in intermediate features by 60% to over 95% through pruning along the channel dimension for each pixel, thus relieving the computational and memory burden. On BSD100 dataset, the multiply-accumulate operations can be reduced by over 80% for super resolution tasks. In addition, we propose a method to quantitatively control the level of sparsity and design a way to train one model that supports multi-sparsity. We identify the effectiveness of our method for pixel to pixel tasks by qualitative theoretical analysis and experiments.
ADMP: An Adversarial Double Masks Based Pruning Framework For Unsupervised Cross-Domain Compression
Jun 07, 2020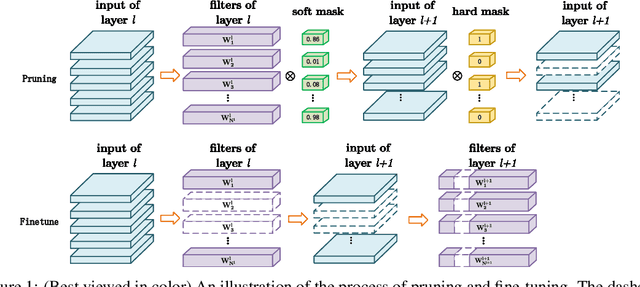
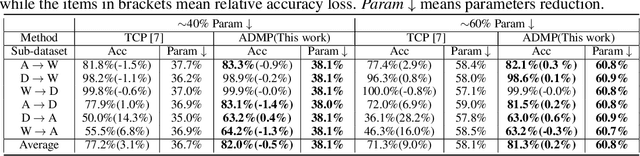
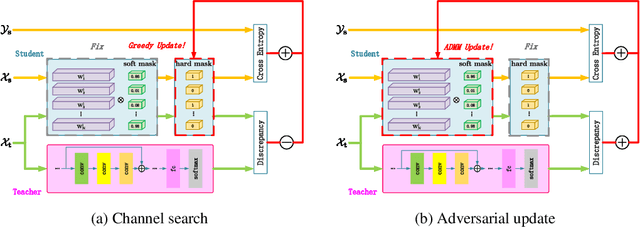
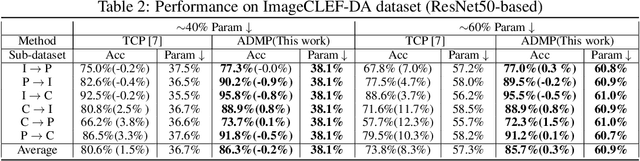
Despite the recent progress of network pruning, directly applying it to the Internet of Things (IoT) applications still faces two challenges, i.e. the distribution divergence between end and cloud data and the missing of data label on end devices. One straightforward solution is to combine the unsupervised domain adaptation (UDA) technique and pruning. For example, the model is first pruned on the cloud and then transferred from cloud to end by UDA. However, such a naive combination faces high performance degradation. Hence this work proposes an Adversarial Double Masks based Pruning (ADMP) for such cross-domain compression. In ADMP, we construct a Knowledge Distillation framework not only to produce pseudo labels but also to provide a measurement of domain divergence as the output difference between the full-size teacher and the pruned student. Unlike existing mask-based pruning works, two adversarial masks, i.e. soft and hard masks, are adopted in ADMP. So ADMP can prune the model effectively while still allowing the model to extract strong domain-invariant features and robust classification boundaries. During training, the Alternating Direction Multiplier Method is used to overcome the binary constraint of {0,1}-masks. On Office31 and ImageCLEF-DA datasets, the proposed ADMP can prune 60% channels with only 0.2% and 0.3% average accuracy loss respectively. Compared with the state of art, we can achieve about 1.63x parameters reduction and 4.1% and 5.1% accuracy improvement.
Progressive DNN Compression: A Key to Achieve Ultra-High Weight Pruning and Quantization Rates using ADMM
Mar 30, 2019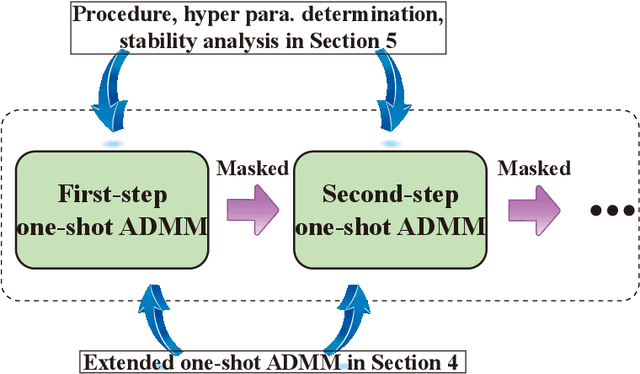
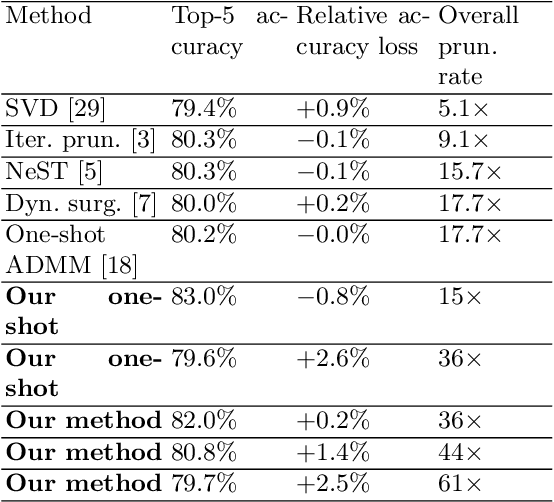

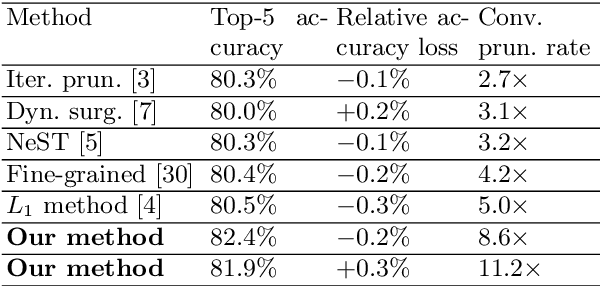
Weight pruning and weight quantization are two important categories of DNN model compression. Prior work on these techniques are mainly based on heuristics. A recent work developed a systematic frame-work of DNN weight pruning using the advanced optimization technique ADMM (Alternating Direction Methods of Multipliers), achieving one of state-of-art in weight pruning results. In this work, we first extend such one-shot ADMM-based framework to guarantee solution feasibility and provide fast convergence rate, and generalize to weight quantization as well. We have further developed a multi-step, progressive DNN weight pruning and quantization framework, with dual benefits of (i) achieving further weight pruning/quantization thanks to the special property of ADMM regularization, and (ii) reducing the search space within each step. Extensive experimental results demonstrate the superior performance compared with prior work. Some highlights: (i) we achieve 246x,36x, and 8x weight pruning on LeNet-5, AlexNet, and ResNet-50 models, respectively, with (almost) zero accuracy loss; (ii) even a significant 61x weight pruning in AlexNet (ImageNet) results in only minor degradation in actual accuracy compared with prior work; (iii) we are among the first to derive notable weight pruning results for ResNet and MobileNet models; (iv) we derive the first lossless, fully binarized (for all layers) LeNet-5 for MNIST and VGG-16 for CIFAR-10; and (v) we derive the first fully binarized (for all layers) ResNet for ImageNet with reasonable accuracy loss.