 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoDistill: Bidirectional Concept Distillation for One-Step Diffusion Personalization
Oct 23, 2025Recent advances in accelerating text-to-image (T2I) diffusion models have enabled the synthesis of high-fidelity images even in a single step. However, personalizing these models to incorporate novel concepts remains a challenge due to the limited capacity of one-step models to capture new concept distributions effectively. We propose a bidirectional concept distillation framework, EchoDistill, to enable one-step diffusion personalization (1-SDP). Our approach involves an end-to-end training process where a multi-step diffusion model (teacher) and a one-step diffusion model (student) are trained simultaneously. The concept is first distilled from the teacher model to the student, and then echoed back from the student to the teacher. During the EchoDistill, we share the text encoder between the two models to ensure consistent semantic understanding. Following this, the student model is optimized with adversarial losses to align with the real image distribution and with alignment losses to maintain consistency with the teacher's output. Furthermore, we introduce the bidirectional echoing refinement strategy, wherein the student model leverages its faster generation capability to feedback to the teacher model. This bidirectional concept distillation mechanism not only enhances the student ability to personalize novel concepts but also improves the generative quality of the teacher model. Our experiments demonstrate that this collaborative framework significantly outperforms existing personalization methods over the 1-SDP setup, establishing a novel paradigm for rapid and effective personalization in T2I diffusion models.
MLI-NeRF: Multi-Light Intrinsic-Aware Neural Radiance Fields
Nov 26, 2024



Current methods for extracting intrinsic image components, such as reflectance and shading, primarily rely on statistical priors. These methods focus mainly on simple synthetic scenes and isolated objects and struggle to perform well on challenging real-world data. To address this issue, we propose MLI-NeRF, which integrates \textbf{M}ultiple \textbf{L}ight information in \textbf{I}ntrinsic-aware \textbf{Ne}ural \textbf{R}adiance \textbf{F}ields. By leveraging scene information provided by different light source positions complementing the multi-view information, we generate pseudo-label images for reflectance and shading to guide intrinsic image decomposition without the need for ground truth data. Our method introduces straightforward supervision for intrinsic component separation and ensures robustness across diverse scene types. We validate our approach on both synthetic and real-world datasets, outperforming existing state-of-the-art methods. Additionally, we demonstrate its applicability to various image editing tasks. The code and data are publicly available.
Relighting from a Single Image: Datasets and Deep Intrinsic-based Architecture
Sep 27, 2024Single image scene relighting aims to generate a realistic new version of an input image so that it appears to be illuminated by a new target light condition. Although existing works have explored this problem from various perspectives, generating relit images under arbitrary light conditions remains highly challenging, and related datasets are scarce. Our work addresses this problem from both the dataset and methodological perspectives. We propose two new datasets: a synthetic dataset with the ground truth of intrinsic components and a real dataset collected under laboratory conditions. These datasets alleviate the scarcity of existing datasets. To incorporate physical consistency in the relighting pipeline, we establish a two-stage network based on intrinsic decomposition, giving outputs at intermediate steps, thereby introducing physical constraints. When the training set lacks ground truth for intrinsic decomposition, we introduce an unsupervised module to ensure that the intrinsic outputs are satisfactory. Our method outperforms the state-of-the-art methods in performance, as tested on both existing datasets and our newly developed datasets. Furthermore, pretraining our method or other prior methods using our synthetic dataset can enhance their performance on other datasets. Since our method can accommodate any light conditions, it is capable of producing animated results. The dataset, method, and videos are publicly available.
Learning Relighting and Intrinsic Decomposition in Neural Radiance Fields
Jun 16, 2024The task of extracting intrinsic components, such as reflectance and shading, from neural radiance fields is of growing interest. However, current methods largely focus on synthetic scenes and isolated objects, overlooking the complexities of real scenes with backgrounds. To address this gap, our research introduces a method that combines relighting with intrinsic decomposition. By leveraging light variations in scenes to generate pseudo labels, our method provides guidance for intrinsic decomposition without requiring ground truth data. Our method, grounded in physical constraints, ensures robustness across diverse scene types and reduces the reliance on pre-trained models or hand-crafted priors. We validate our method on both synthetic and real-world datasets, achieving convincing results. Furthermore, the applicability of our method to image editing tasks demonstrates promising outcomes.
Block-Wise Dynamic-Precision Neural Network Training Acceleration via Online Quantization Sensitivity Analytics
Oct 31, 2022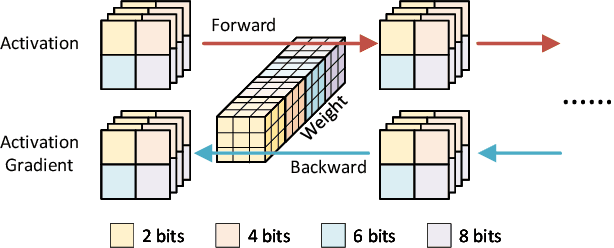
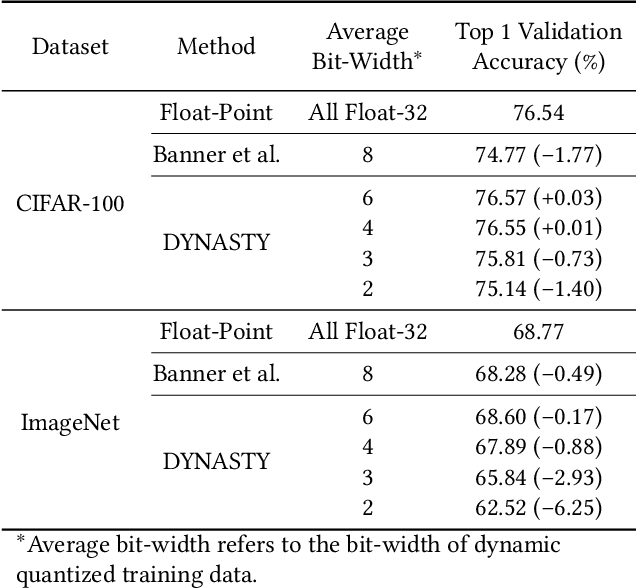
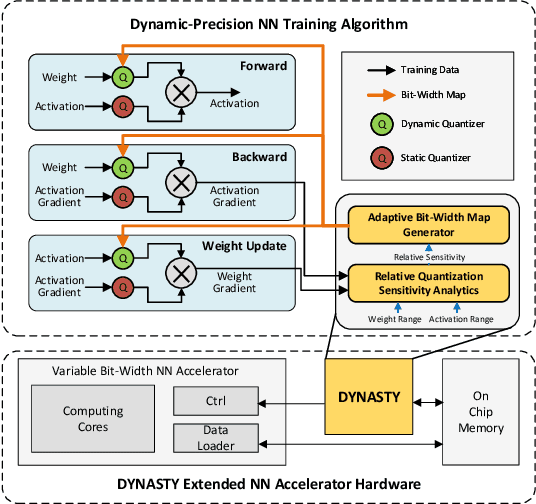
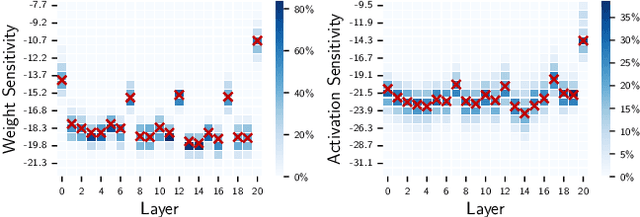
Data quantization is an effective method to accelerate neural network training and reduce power consumption. However, it is challenging to perform low-bit quantized training: the conventional equal-precision quantization will lead to either high accuracy loss or limited bit-width reduction, while existing mixed-precision methods offer high compression potential but failed to perform accurate and efficient bit-width assignment. In this work, we propose DYNASTY, a block-wise dynamic-precision neural network training framework. DYNASTY provides accurate data sensitivity information through fast online analytics, and maintains stable training convergence with an adaptive bit-width map generator. Network training experiments on CIFAR-100 and ImageNet dataset are carried out, and compared to 8-bit quantization baseline, DYNASTY brings up to $5.1\times$ speedup and $4.7\times$ energy consumption reduction with no accuracy drop and negligible hardware overhead.