 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniGF: A Dual-Branch Vision-Language Framework for Unified Gaze Following
May 26, 2026Understanding human gaze behavior is essential for complex scene comprehension and human-computer interaction. Traditional gaze following models are typically restricted to pure spatial localization, lacking the high-level capacity to reason about semantic targets or complex social contexts. Furthermore, these models often process individuals sequentially, requiring redundant computations over the same scene image for multi-person inference. While recent Vision-Language Models (VLMs) offer the exceptional semantic reasoning needed to address gaze-related semantic tasks, their reliance on discrete text generation inherently limits precision in continuous spatial tasks like gaze localization. To bridge this gap, we propose OmniGF, a unified vision-language framework that adapts foundational VLMs for highly scalable multi-person gaze reasoning. The model adopts a dual-branch decoding strategy: a structured language branch generates discrete reasoning states, while a continuous spatial branch directly taps into the VLM's dense hidden states. Supervising these extracted representations with high-resolution gaze target heatmaps effectively overcomes the spatial bottleneck of text-only coordinate generation. Furthermore, to explicitly ground the model in multi-person scenes, we augment the input with head embeddings encoded from cropped head images, providing fine-grained appearance and orientation cues for all individuals simultaneously. By modeling all individuals and leveraging the strong semantic capability of VLMs, OmniGF seamlessly integrates precise spatial gaze target estimation, semantic gaze prediction, and complex social gaze reasoning. Extensive experiments demonstrate that our framework establishes new state-of-the-art performance across multiple standard benchmarks. Code is available at https://github.com/cvlab-stonybrook/omnigf.
ForeSplat: Optimization-Aware Foresight for Feed-Forward 3D Gaussian Splatting
May 21, 2026Feed-forward 3D Gaussian Splatting (3DGS) models offer fast single-pass reconstruction,but scaling them to match per-scene optimization quality is fundamentally hindered by the scarcity of large-scale 3D annotations.A practical compromise is predict-then-refine,where post-prediction optimization compensates for the limited capacity of the feed-forward network.However,standard feed-forward 3DGS is trained solely for zero-step rendering error,ignoring whether its output constitutes a good initialization for the downstream optimizer.We present ForeSplat,an optimization-aware training framework that equips feed-forward 3DGS models to produce initializations explicitly designed for rapid,effective refinement.By offloading part of the scene-modeling burden to the optimizer,ForeSplat substantially reduces the capacity pressure on the feed-forward model,making high-quality reconstruction feasible even with compact networks.At its core is MetaGrad,a lightweight multi-anchor meta-gradient training rule that bypasses costly higher-order differentiation through the 3DGS optimizer.MetaGrad unrolls a short inner-loop refinement trajectory,samples anchor states,and back-propagates aggregated first-order gradients to the prediction head as a surrogate optimization-aware signal.This fine-tuning adds no inference cost and enables high-quality reconstruction within seconds after a few refinement steps.We instantiate ForeSplat on diverse backbones,including AnySplat,Pi3X,and a distilled variant tailored for edge deployment.Across all tested architectures,a ForeSplat-trained initialization converges in fewer refinement steps and reaches a higher peak reconstruction quality than its vanilla counterpart,even fully converged.The framework consistently bridges the gap between amortized prediction and per-scene optimization,establishing a practical path toward lightweight,high-fidelity 3D reconstruction.
MultiWorld: Scalable Multi-Agent Multi-View Video World Models
Apr 21, 2026Video world models have achieved remarkable success in simulating environmental dynamics in response to actions by users or agents. They are modeled as action-conditioned video generation models that take historical frames and current actions as input to predict future frames. Yet, most existing approaches are limited to single-agent scenarios and fail to capture the complex interactions inherent in real-world multi-agent systems. We present \textbf{MultiWorld}, a unified framework for multi-agent multi-view world modeling that enables accurate control of multiple agents while maintaining multi-view consistency. We introduce the Multi-Agent Condition Module to achieve precise multi-agent controllability, and the Global State Encoder to ensure coherent observations across different views. MultiWorld supports flexible scaling of agent and view counts, and synthesizes different views in parallel for high efficiency. Experiments on multi-player game environments and multi-robot manipulation tasks demonstrate that MultiWorld outperforms baselines in video fidelity, action-following ability, and multi-view consistency. Project page: https://multi-world.github.io/
Learning 3D Reconstruction with Priors in Test Time
Apr 04, 2026We introduce a test-time framework for multiview Transformers (MVTs) that incorporates priors (e.g., camera poses, intrinsics, and depth) to improve 3D tasks without retraining or modifying pre-trained image-only networks. Rather than feeding priors into the architecture, we cast them as constraints on the predictions and optimize the network at inference time. The optimization loss consists of a self-supervised objective and prior penalty terms. The self-supervised objective captures the compatibility among multi-view predictions and is implemented using photometric or geometric loss between renderings from other views and each view itself. Any available priors are converted into penalty terms on the corresponding output modalities. Across a series of 3D vision benchmarks, including point map estimation and camera pose estimation, our method consistently improves performance over base MVTs by a large margin. On the ETH3D, 7-Scenes, and NRGBD datasets, our method reduces the point-map distance error by more than half compared with the base image-only models. Our method also outperforms retrained prior-aware feed-forward methods, demonstrating the effectiveness of our test-time constrained optimization (TCO) framework for incorporating priors into 3D vision tasks.
Oedipus and the Sphinx: Benchmarking and Improving Visual Language Models for Complex Graphic Reasoning
Aug 01, 2025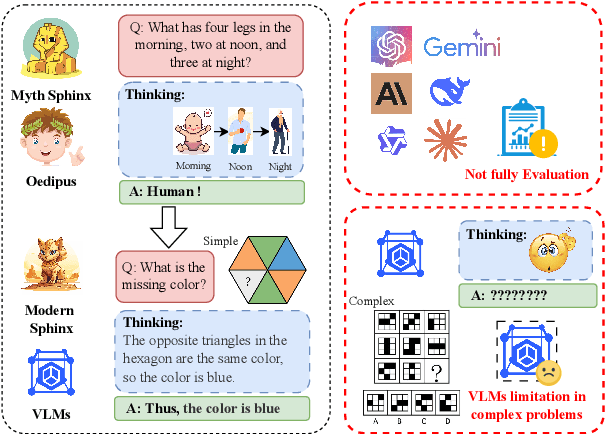
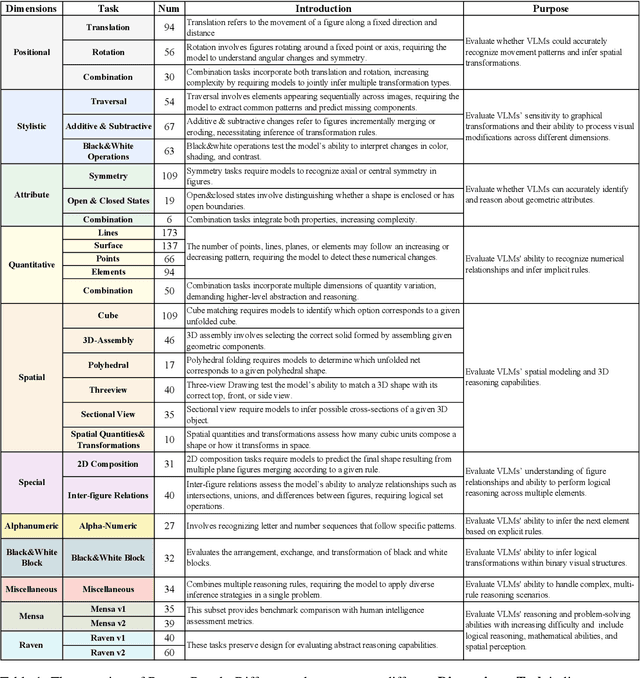
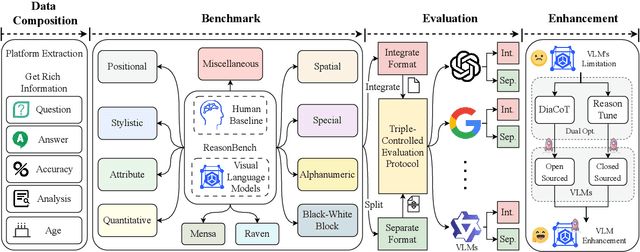
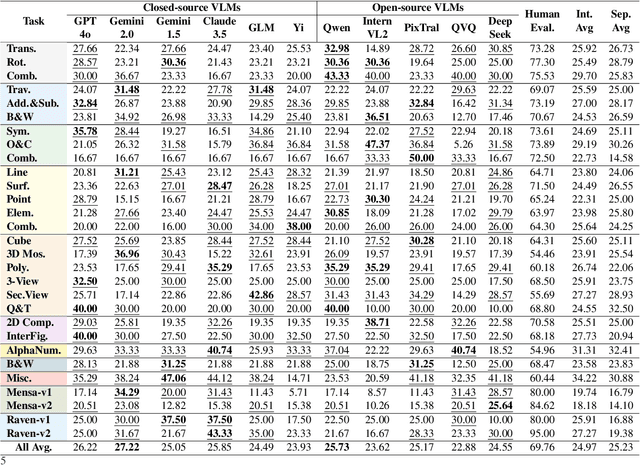
Evaluating the performance of visual language models (VLMs) in graphic reasoning tasks has become an important research topic. However, VLMs still show obvious deficiencies in simulating human-level graphic reasoning capabilities, especially in complex graphic reasoning and abstract problem solving, which are less studied and existing studies only focus on simple graphics. To evaluate the performance of VLMs in complex graphic reasoning, we propose ReasonBench, the first evaluation benchmark focused on structured graphic reasoning tasks, which includes 1,613 questions from real-world intelligence tests. ReasonBench covers reasoning dimensions related to location, attribute, quantity, and multi-element tasks, providing a comprehensive evaluation of the performance of VLMs in spatial, relational, and abstract reasoning capabilities. We benchmark 11 mainstream VLMs (including closed-source and open-source models) and reveal significant limitations of current models. Based on these findings, we propose a dual optimization strategy: Diagrammatic Reasoning Chain (DiaCoT) enhances the interpretability of reasoning by decomposing layers, and ReasonTune enhances the task adaptability of model reasoning through training, all of which improves VLM performance by 33.5\%. All experimental data and code are in the repository: https://huggingface.co/datasets/cistine/ReasonBench.
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Jul 10, 2025Videos inherently represent 2D projections of a dynamic 3D world. However, our analysis suggests that video diffusion models trained solely on raw video data often fail to capture meaningful geometric-aware structure in their learned representations. To bridge this gap between video diffusion models and the underlying 3D nature of the physical world, we propose Geometry Forcing, a simple yet effective method that encourages video diffusion models to internalize latent 3D representations. Our key insight is to guide the model's intermediate representations toward geometry-aware structure by aligning them with features from a pretrained geometric foundation model. To this end, we introduce two complementary alignment objectives: Angular Alignment, which enforces directional consistency via cosine similarity, and Scale Alignment, which preserves scale-related information by regressing unnormalized geometric features from normalized diffusion representation. We evaluate Geometry Forcing on both camera view-conditioned and action-conditioned video generation tasks. Experimental results demonstrate that our method substantially improves visual quality and 3D consistency over the baseline methods. Project page: https://GeometryForcing.github.io.
DualTalk: Dual-Speaker Interaction for 3D Talking Head Conversations
May 26, 2025In face-to-face conversations, individuals need to switch between speaking and listening roles seamlessly. Existing 3D talking head generation models focus solely on speaking or listening, neglecting the natural dynamics of interactive conversation, which leads to unnatural interactions and awkward transitions. To address this issue, we propose a new task -- multi-round dual-speaker interaction for 3D talking head generation -- which requires models to handle and generate both speaking and listening behaviors in continuous conversation. To solve this task, we introduce DualTalk, a novel unified framework that integrates the dynamic behaviors of speakers and listeners to simulate realistic and coherent dialogue interactions. This framework not only synthesizes lifelike talking heads when speaking but also generates continuous and vivid non-verbal feedback when listening, effectively capturing the interplay between the roles. We also create a new dataset featuring 50 hours of multi-round conversations with over 1,000 characters, where participants continuously switch between speaking and listening roles. Extensive experiments demonstrate that our method significantly enhances the naturalness and expressiveness of 3D talking heads in dual-speaker conversations. We recommend watching the supplementary video: https://ziqiaopeng.github.io/dualtalk.
MineWorld: a Real-Time and Open-Source Interactive World Model on Minecraft
Apr 11, 2025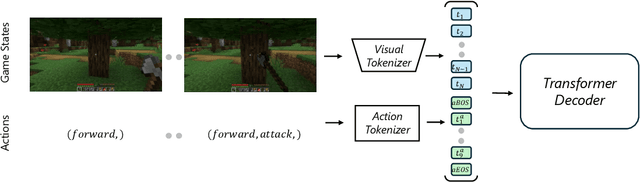

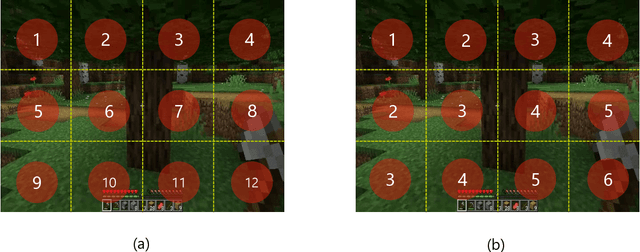
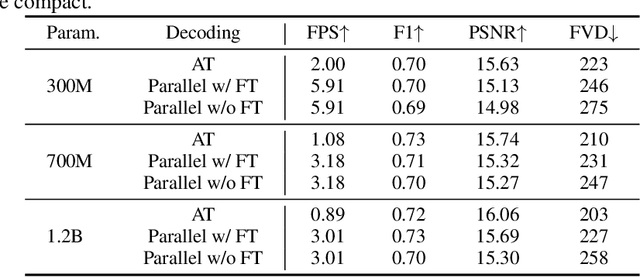
World modeling is a crucial task for enabling intelligent agents to effectively interact with humans and operate in dynamic environments. In this work, we propose MineWorld, a real-time interactive world model on Minecraft, an open-ended sandbox game which has been utilized as a common testbed for world modeling. MineWorld is driven by a visual-action autoregressive Transformer, which takes paired game scenes and corresponding actions as input, and generates consequent new scenes following the actions. Specifically, by transforming visual game scenes and actions into discrete token ids with an image tokenizer and an action tokenizer correspondingly, we consist the model input with the concatenation of the two kinds of ids interleaved. The model is then trained with next token prediction to learn rich representations of game states as well as the conditions between states and actions simultaneously. In inference, we develop a novel parallel decoding algorithm that predicts the spatial redundant tokens in each frame at the same time, letting models in different scales generate $4$ to $7$ frames per second and enabling real-time interactions with game players. In evaluation, we propose new metrics to assess not only visual quality but also the action following capacity when generating new scenes, which is crucial for a world model. Our comprehensive evaluation shows the efficacy of MineWorld, outperforming SoTA open-sourced diffusion based world models significantly. The code and model have been released.
Fast Autoregressive Video Generation with Diagonal Decoding
Mar 18, 2025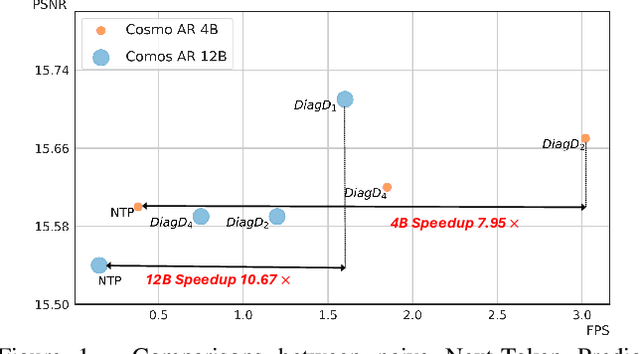
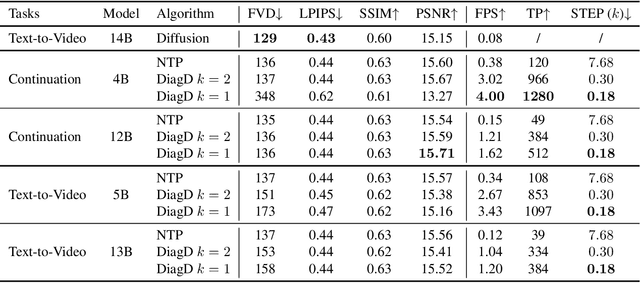
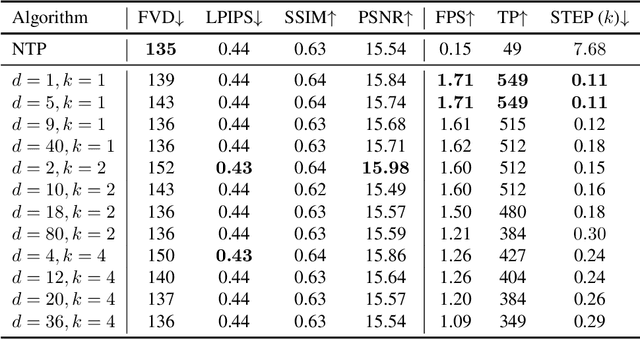
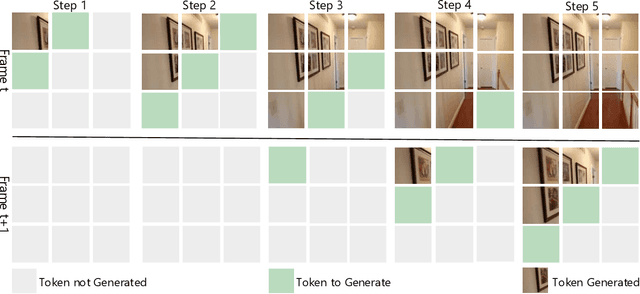
Autoregressive Transformer models have demonstrated impressive performance in video generation, but their sequential token-by-token decoding process poses a major bottleneck, particularly for long videos represented by tens of thousands of tokens. In this paper, we propose Diagonal Decoding (DiagD), a training-free inference acceleration algorithm for autoregressively pre-trained models that exploits spatial and temporal correlations in videos. Our method generates tokens along diagonal paths in the spatial-temporal token grid, enabling parallel decoding within each frame as well as partially overlapping across consecutive frames. The proposed algorithm is versatile and adaptive to various generative models and tasks, while providing flexible control over the trade-off between inference speed and visual quality. Furthermore, we propose a cost-effective finetuning strategy that aligns the attention patterns of the model with our decoding order, further mitigating the training-inference gap on small-scale models. Experiments on multiple autoregressive video generation models and datasets demonstrate that DiagD achieves up to $10\times$ speedup compared to naive sequential decoding, while maintaining comparable visual fidelity.
CoheDancers: Enhancing Interactive Group Dance Generation through Music-Driven Coherence Decomposition
Dec 26, 2024



Dance generation is crucial and challenging, particularly in domains like dance performance and virtual gaming. In the current body of literature, most methodologies focus on Solo Music2Dance. While there are efforts directed towards Group Music2Dance, these often suffer from a lack of coherence, resulting in aesthetically poor dance performances. Thus, we introduce CoheDancers, a novel framework for Music-Driven Interactive Group Dance Generation. CoheDancers aims to enhance group dance generation coherence by decomposing it into three key aspects: synchronization, naturalness, and fluidity. Correspondingly, we develop a Cycle Consistency based Dance Synchronization strategy to foster music-dance correspondences, an Auto-Regressive-based Exposure Bias Correction strategy to enhance the fluidity of the generated dances, and an Adversarial Training Strategy to augment the naturalness of the group dance output. Collectively, these strategies enable CohdeDancers to produce highly coherent group dances with superior quality. Furthermore, to establish better benchmarks for Group Music2Dance, we construct the most diverse and comprehensive open-source dataset to date, I-Dancers, featuring rich dancer interactions, and create comprehensive evaluation metrics. Experimental evaluations on I-Dancers and other extant datasets substantiate that CoheDancers achieves unprecedented state-of-the-art performance. Code will be released.