 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLI-NeRF: Multi-Light Intrinsic-Aware Neural Radiance Fields
Nov 26, 2024



Current methods for extracting intrinsic image components, such as reflectance and shading, primarily rely on statistical priors. These methods focus mainly on simple synthetic scenes and isolated objects and struggle to perform well on challenging real-world data. To address this issue, we propose MLI-NeRF, which integrates \textbf{M}ultiple \textbf{L}ight information in \textbf{I}ntrinsic-aware \textbf{Ne}ural \textbf{R}adiance \textbf{F}ields. By leveraging scene information provided by different light source positions complementing the multi-view information, we generate pseudo-label images for reflectance and shading to guide intrinsic image decomposition without the need for ground truth data. Our method introduces straightforward supervision for intrinsic component separation and ensures robustness across diverse scene types. We validate our approach on both synthetic and real-world datasets, outperforming existing state-of-the-art methods. Additionally, we demonstrate its applicability to various image editing tasks. The code and data are publicly available.
Shadow Removal Refinement via Material-Consistent Shadow Edges
Sep 10, 2024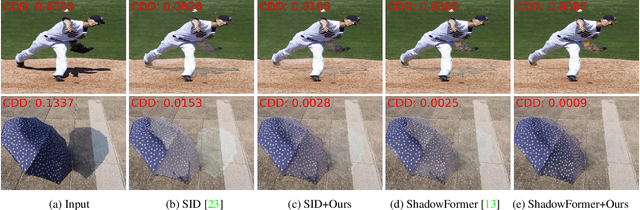
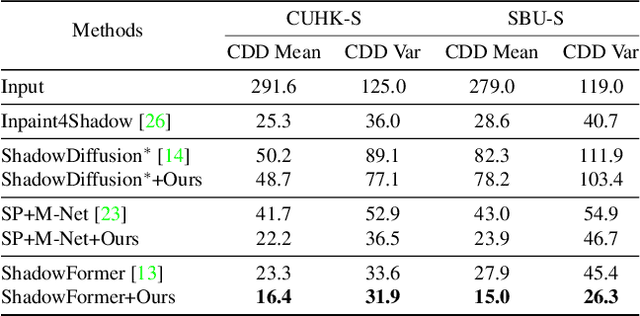
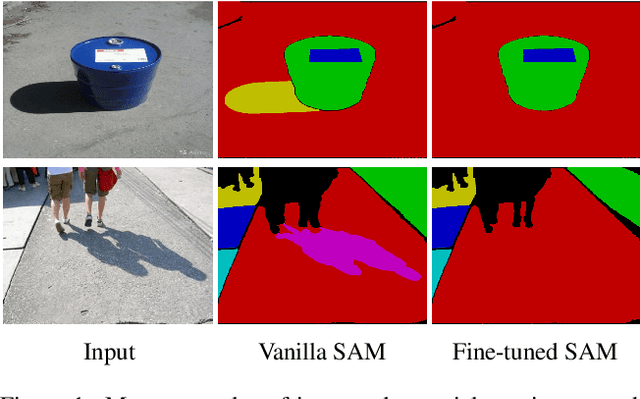

Shadow boundaries can be confused with material boundaries as both exhibit sharp changes in luminance or contrast within a scene. However, shadows do not modify the intrinsic color or texture of surfaces. Therefore, on both sides of shadow edges traversing regions with the same material, the original color and textures should be the same if the shadow is removed properly. These shadow/shadow-free pairs are very useful but hard-to-collect supervision signals. The crucial contribution of this paper is to learn how to identify those shadow edges that traverse material-consistent regions and how to use them as self-supervision for shadow removal refinement during test time. To achieve this, we fine-tune SAM, an image segmentation foundation model, to produce a shadow-invariant segmentation and then extract material-consistent shadow edges by comparing the SAM segmentation with the shadow mask. Utilizing these shadow edges, we introduce color and texture-consistency losses to enhance the shadow removal process. We demonstrate the effectiveness of our method in improving shadow removal results on more challenging, in-the-wild images, outperforming the state-of-the-art shadow removal methods. Additionally, we propose a new metric and an annotated dataset for evaluating the performance of shadow removal methods without the need for paired shadow/shadow-free data.
Learning Relighting and Intrinsic Decomposition in Neural Radiance Fields
Jun 16, 2024The task of extracting intrinsic components, such as reflectance and shading, from neural radiance fields is of growing interest. However, current methods largely focus on synthetic scenes and isolated objects, overlooking the complexities of real scenes with backgrounds. To address this gap, our research introduces a method that combines relighting with intrinsic decomposition. By leveraging light variations in scenes to generate pseudo labels, our method provides guidance for intrinsic decomposition without requiring ground truth data. Our method, grounded in physical constraints, ensures robustness across diverse scene types and reduces the reliance on pre-trained models or hand-crafted priors. We validate our method on both synthetic and real-world datasets, achieving convincing results. Furthermore, the applicability of our method to image editing tasks demonstrates promising outcomes.
Temporal Feature Warping for Video Shadow Detection
Jul 29, 2021
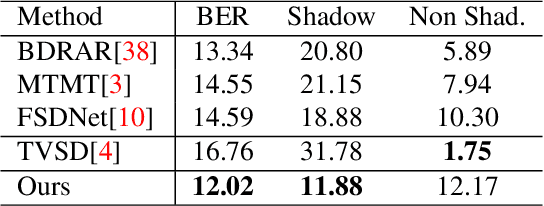
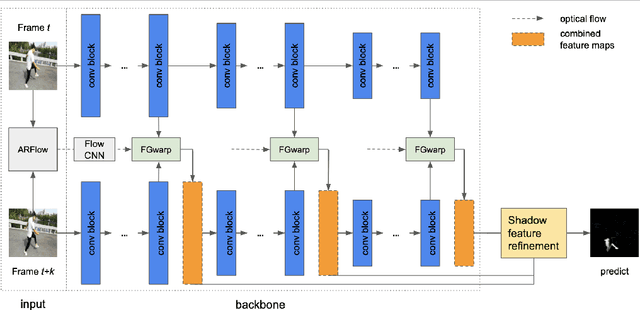

While single image shadow detection has been improving rapidly in recent years, video shadow detection remains a challenging task due to data scarcity and the difficulty in modelling temporal consistency. The current video shadow detection method achieves this goal via co-attention, which mostly exploits information that is temporally coherent but is not robust in detecting moving shadows and small shadow regions. In this paper, we propose a simple but powerful method to better aggregate information temporally. We use an optical flow based warping module to align and then combine features between frames. We apply this warping module across multiple deep-network layers to retrieve information from neighboring frames including both local details and high-level semantic information. We train and test our framework on the ViSha dataset. Experimental results show that our model outperforms the state-of-the-art video shadow detection method by 28%, reducing BER from 16.7 to 12.0.