 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Feature Warping for Video Shadow Detection
Paper and Code
Jul 29, 2021
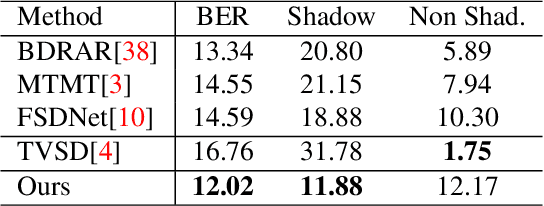
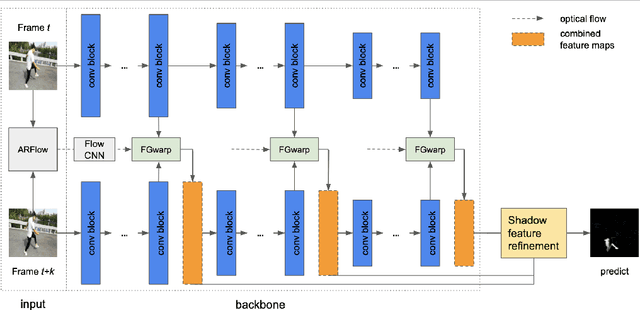

While single image shadow detection has been improving rapidly in recent years, video shadow detection remains a challenging task due to data scarcity and the difficulty in modelling temporal consistency. The current video shadow detection method achieves this goal via co-attention, which mostly exploits information that is temporally coherent but is not robust in detecting moving shadows and small shadow regions. In this paper, we propose a simple but powerful method to better aggregate information temporally. We use an optical flow based warping module to align and then combine features between frames. We apply this warping module across multiple deep-network layers to retrieve information from neighboring frames including both local details and high-level semantic information. We train and test our framework on the ViSha dataset. Experimental results show that our model outperforms the state-of-the-art video shadow detection method by 28%, reducing BER from 16.7 to 12.0.