 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Voices: Generating A-Roll Video from Audio with Mirage
Jun 09, 2025



From professional filmmaking to user-generated content, creators and consumers have long recognized that the power of video depends on the harmonious integration of what we hear (the video's audio track) with what we see (the video's image sequence). Current approaches to video generation either ignore sound to focus on general-purpose but silent image sequence generation or address both visual and audio elements but focus on restricted application domains such as re-dubbing. We introduce Mirage, an audio-to-video foundation model that excels at generating realistic, expressive output imagery from scratch given an audio input. When integrated with existing methods for speech synthesis (text-to-speech, or TTS), Mirage results in compelling multimodal video. When trained on audio-video footage of people talking (A-roll) and conditioned on audio containing speech, Mirage generates video of people delivering a believable interpretation of the performance implicit in input audio. Our central technical contribution is a unified method for training self-attention-based audio-to-video generation models, either from scratch or given existing weights. This methodology allows Mirage to retain generality as an approach to audio-to-video generation while producing outputs of superior subjective quality to methods that incorporate audio-specific architectures or loss components specific to people, speech, or details of how images or audio are captured. We encourage readers to watch and listen to the results of Mirage for themselves (see paper and comments for links).
Shadow Removal Refinement via Material-Consistent Shadow Edges
Sep 10, 2024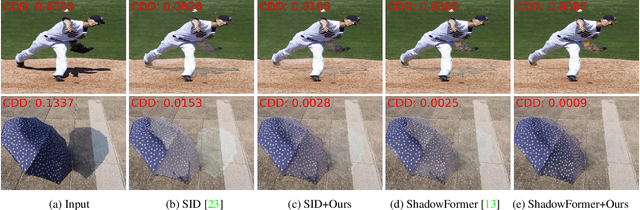
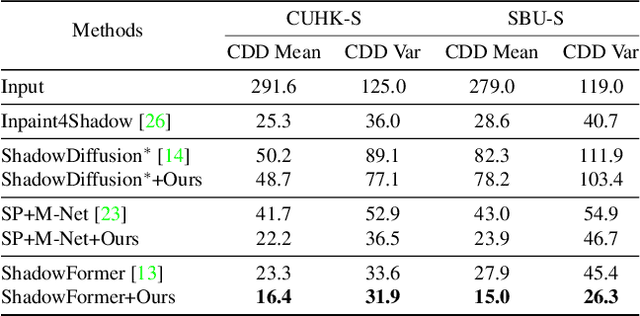
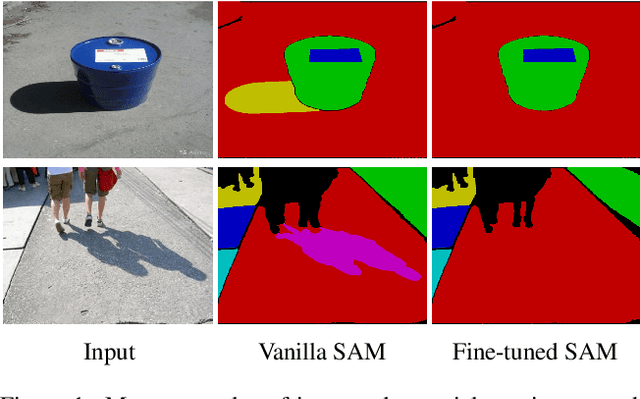

Shadow boundaries can be confused with material boundaries as both exhibit sharp changes in luminance or contrast within a scene. However, shadows do not modify the intrinsic color or texture of surfaces. Therefore, on both sides of shadow edges traversing regions with the same material, the original color and textures should be the same if the shadow is removed properly. These shadow/shadow-free pairs are very useful but hard-to-collect supervision signals. The crucial contribution of this paper is to learn how to identify those shadow edges that traverse material-consistent regions and how to use them as self-supervision for shadow removal refinement during test time. To achieve this, we fine-tune SAM, an image segmentation foundation model, to produce a shadow-invariant segmentation and then extract material-consistent shadow edges by comparing the SAM segmentation with the shadow mask. Utilizing these shadow edges, we introduce color and texture-consistency losses to enhance the shadow removal process. We demonstrate the effectiveness of our method in improving shadow removal results on more challenging, in-the-wild images, outperforming the state-of-the-art shadow removal methods. Additionally, we propose a new metric and an annotated dataset for evaluating the performance of shadow removal methods without the need for paired shadow/shadow-free data.
Bridging the Gap: Studio-like Avatar Creation from a Monocular Phone Capture
Jul 28, 2024Creating photorealistic avatars for individuals traditionally involves extensive capture sessions with complex and expensive studio devices like the LightStage system. While recent strides in neural representations have enabled the generation of photorealistic and animatable 3D avatars from quick phone scans, they have the capture-time lighting baked-in, lack facial details and have missing regions in areas such as the back of the ears. Thus, they lag in quality compared to studio-captured avatars. In this paper, we propose a method that bridges this gap by generating studio-like illuminated texture maps from short, monocular phone captures. We do this by parameterizing the phone texture maps using the $W^+$ space of a StyleGAN2, enabling near-perfect reconstruction. Then, we finetune a StyleGAN2 by sampling in the $W^+$ parameterized space using a very small set of studio-captured textures as an adversarial training signal. To further enhance the realism and accuracy of facial details, we super-resolve the output of the StyleGAN2 using carefully designed diffusion model that is guided by image gradients of the phone-captured texture map. Once trained, our method excels at producing studio-like facial texture maps from casual monocular smartphone videos. Demonstrating its capabilities, we showcase the generation of photorealistic, uniformly lit, complete avatars from monocular phone captures. \href{http://shahrukhathar.github.io/2024/07/22/Bridging.html}{The project page can be found here.}
Rig3DGS: Creating Controllable Portraits from Casual Monocular Videos
Feb 06, 2024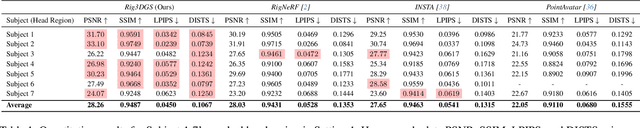
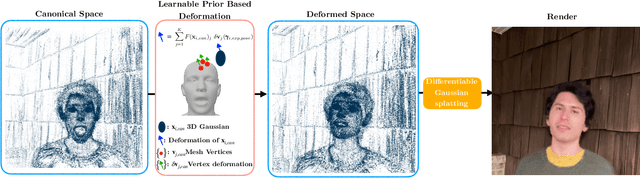
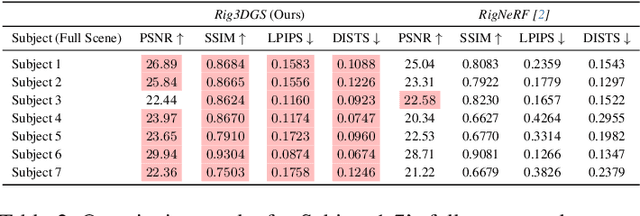

Creating controllable 3D human portraits from casual smartphone videos is highly desirable due to their immense value in AR/VR applications. The recent development of 3D Gaussian Splatting (3DGS) has shown improvements in rendering quality and training efficiency. However, it still remains a challenge to accurately model and disentangle head movements and facial expressions from a single-view capture to achieve high-quality renderings. In this paper, we introduce Rig3DGS to address this challenge. We represent the entire scene, including the dynamic subject, using a set of 3D Gaussians in a canonical space. Using a set of control signals, such as head pose and expressions, we transform them to the 3D space with learned deformations to generate the desired rendering. Our key innovation is a carefully designed deformation method which is guided by a learnable prior derived from a 3D morphable model. This approach is highly efficient in training and effective in controlling facial expressions, head positions, and view synthesis across various captures. We demonstrate the effectiveness of our learned deformation through extensive quantitative and qualitative experiments. The project page can be found at http://shahrukhathar.github.io/2024/02/05/Rig3DGS.html
HeadCraft: Modeling High-Detail Shape Variations for Animated 3DMMs
Dec 21, 2023Current advances in human head modeling allow to generate plausible-looking 3D head models via neural representations. Nevertheless, constructing complete high-fidelity head models with explicitly controlled animation remains an issue. Furthermore, completing the head geometry based on a partial observation, e.g. coming from a depth sensor, while preserving details is often problematic for the existing methods. We introduce a generative model for detailed 3D head meshes on top of an articulated 3DMM which allows explicit animation and high-detail preservation at the same time. Our method is trained in two stages. First, we register a parametric head model with vertex displacements to each mesh of the recently introduced NPHM dataset of accurate 3D head scans. The estimated displacements are baked into a hand-crafted UV layout. Second, we train a StyleGAN model in order to generalize over the UV maps of displacements. The decomposition of the parametric model and high-quality vertex displacements allows us to animate the model and modify it semantically. We demonstrate the results of unconditional generation and fitting to the full or partial observation. The project page is available at https://seva100.github.io/headcraft.
Controllable Dynamic Appearance for Neural 3D Portraits
Sep 21, 2023Recent advances in Neural Radiance Fields (NeRFs) have made it possible to reconstruct and reanimate dynamic portrait scenes with control over head-pose, facial expressions and viewing direction. However, training such models assumes photometric consistency over the deformed region e.g. the face must be evenly lit as it deforms with changing head-pose and facial expression. Such photometric consistency across frames of a video is hard to maintain, even in studio environments, thus making the created reanimatable neural portraits prone to artifacts during reanimation. In this work, we propose CoDyNeRF, a system that enables the creation of fully controllable 3D portraits in real-world capture conditions. CoDyNeRF learns to approximate illumination dependent effects via a dynamic appearance model in the canonical space that is conditioned on predicted surface normals and the facial expressions and head-pose deformations. The surface normals prediction is guided using 3DMM normals that act as a coarse prior for the normals of the human head, where direct prediction of normals is hard due to rigid and non-rigid deformations induced by head-pose and facial expression changes. Using only a smartphone-captured short video of a subject for training, we demonstrate the effectiveness of our method on free view synthesis of a portrait scene with explicit head pose and expression controls, and realistic lighting effects. The project page can be found here: http://shahrukhathar.github.io/2023/08/22/CoDyNeRF.html
RigNeRF: Fully Controllable Neural 3D Portraits
Jun 13, 2022
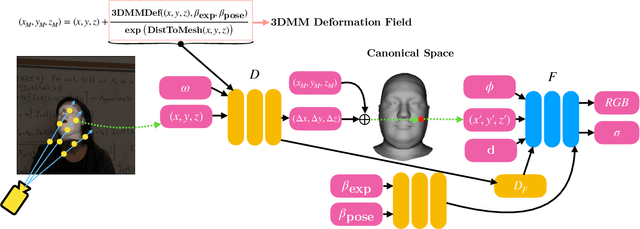

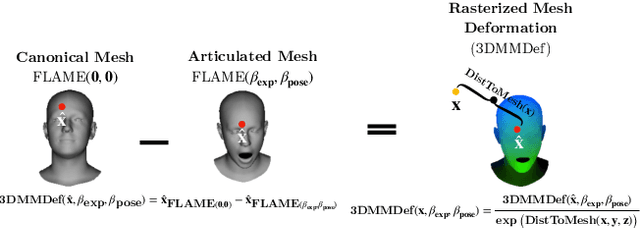
Volumetric neural rendering methods, such as neural radiance fields (NeRFs), have enabled photo-realistic novel view synthesis. However, in their standard form, NeRFs do not support the editing of objects, such as a human head, within a scene. In this work, we propose RigNeRF, a system that goes beyond just novel view synthesis and enables full control of head pose and facial expressions learned from a single portrait video. We model changes in head pose and facial expressions using a deformation field that is guided by a 3D morphable face model (3DMM). The 3DMM effectively acts as a prior for RigNeRF that learns to predict only residuals to the 3DMM deformations and allows us to render novel (rigid) poses and (non-rigid) expressions that were not present in the input sequence. Using only a smartphone-captured short video of a subject for training, we demonstrate the effectiveness of our method on free view synthesis of a portrait scene with explicit head pose and expression controls. The project page can be found here: http://shahrukhathar.github.io/2022/06/06/RigNeRF.html
SIDER: Single-Image Neural Optimization for Facial Geometric Detail Recovery
Aug 11, 2021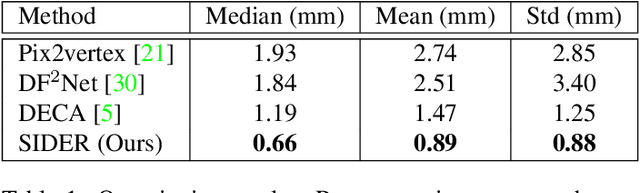
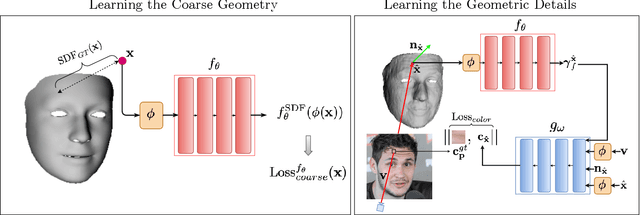


We present SIDER(Single-Image neural optimization for facial geometric DEtail Recovery), a novel photometric optimization method that recovers detailed facial geometry from a single image in an unsupervised manner. Inspired by classical techniques of coarse-to-fine optimization and recent advances in implicit neural representations of 3D shape, SIDER combines a geometry prior based on statistical models and Signed Distance Functions (SDFs) to recover facial details from single images. First, it estimates a coarse geometry using a morphable model represented as an SDF. Next, it reconstructs facial geometry details by optimizing a photometric loss with respect to the ground truth image. In contrast to prior work, SIDER does not rely on any dataset priors and does not require additional supervision from multiple views, lighting changes or ground truth 3D shape. Extensive qualitative and quantitative evaluation demonstrates that our method achieves state-of-the-art on facial geometric detail recovery, using only a single in-the-wild image.
FLAME-in-NeRF : Neural control of Radiance Fields for Free View Face Animation
Aug 10, 2021
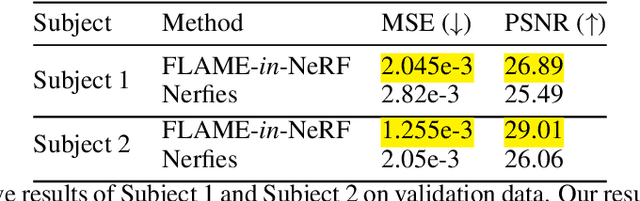
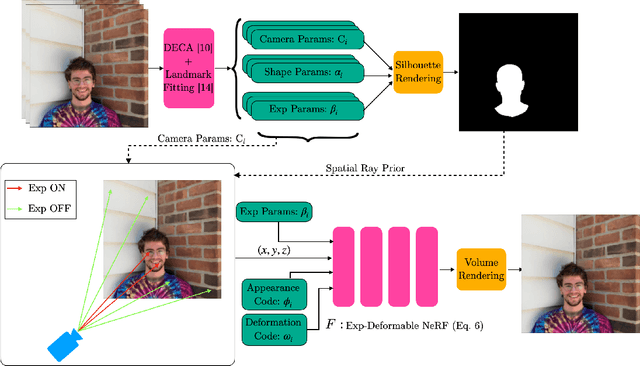
This paper presents a neural rendering method for controllable portrait video synthesis. Recent advances in volumetric neural rendering, such as neural radiance fields (NeRF), has enabled the photorealistic novel view synthesis of static scenes with impressive results. However, modeling dynamic and controllable objects as part of a scene with such scene representations is still challenging. In this work, we design a system that enables both novel view synthesis for portrait video, including the human subject and the scene background, and explicit control of the facial expressions through a low-dimensional expression representation. We leverage the expression space of a 3D morphable face model (3DMM) to represent the distribution of human facial expressions, and use it to condition the NeRF volumetric function. Furthermore, we impose a spatial prior brought by 3DMM fitting to guide the network to learn disentangled control for scene appearance and facial actions. We demonstrate the effectiveness of our method on free view synthesis of portrait videos with expression controls. To train a scene, our method only requires a short video of a subject captured by a mobile device.
FaceDet3D: Facial Expressions with 3D Geometric Detail Prediction
Dec 23, 2020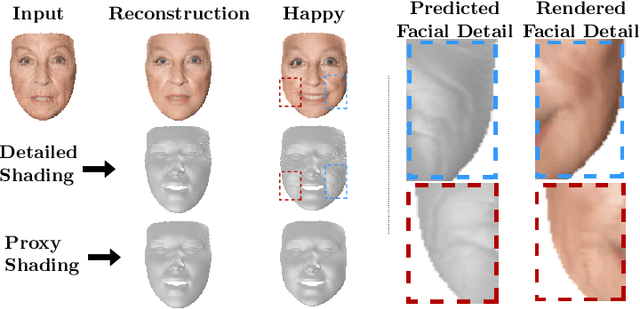
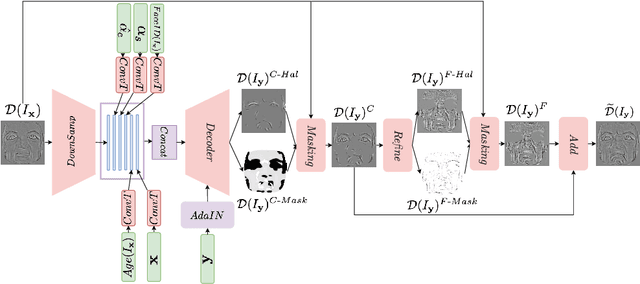
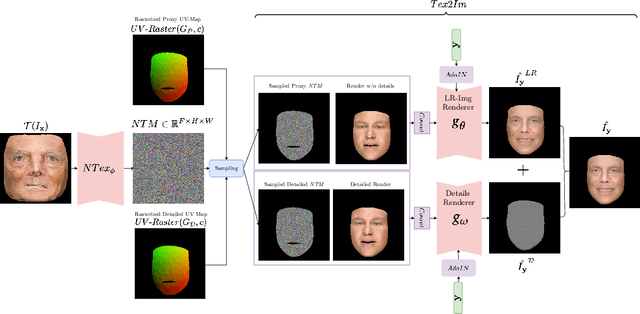

Facial Expressions induce a variety of high-level details on the 3D face geometry. For example, a smile causes the wrinkling of cheeks or the formation of dimples, while being angry often causes wrinkling of the forehead. Morphable Models (3DMMs) of the human face fail to capture such fine details in their PCA-based representations and consequently cannot generate such details when used to edit expressions. In this work, we introduce FaceDet3D, a first-of-its-kind method that generates - from a single image - geometric facial details that are consistent with any desired target expression. The facial details are represented as a vertex displacement map and used then by a Neural Renderer to photo-realistically render novel images of any single image in any desired expression and view. The project website is: http://shahrukhathar.github.io/2020/12/14/FaceDet3D.html