 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Voices: Generating A-Roll Video from Audio with Mirage
Jun 09, 2025



From professional filmmaking to user-generated content, creators and consumers have long recognized that the power of video depends on the harmonious integration of what we hear (the video's audio track) with what we see (the video's image sequence). Current approaches to video generation either ignore sound to focus on general-purpose but silent image sequence generation or address both visual and audio elements but focus on restricted application domains such as re-dubbing. We introduce Mirage, an audio-to-video foundation model that excels at generating realistic, expressive output imagery from scratch given an audio input. When integrated with existing methods for speech synthesis (text-to-speech, or TTS), Mirage results in compelling multimodal video. When trained on audio-video footage of people talking (A-roll) and conditioned on audio containing speech, Mirage generates video of people delivering a believable interpretation of the performance implicit in input audio. Our central technical contribution is a unified method for training self-attention-based audio-to-video generation models, either from scratch or given existing weights. This methodology allows Mirage to retain generality as an approach to audio-to-video generation while producing outputs of superior subjective quality to methods that incorporate audio-specific architectures or loss components specific to people, speech, or details of how images or audio are captured. We encourage readers to watch and listen to the results of Mirage for themselves (see paper and comments for links).
LD-Pruner: Efficient Pruning of Latent Diffusion Models using Task-Agnostic Insights
Apr 18, 2024
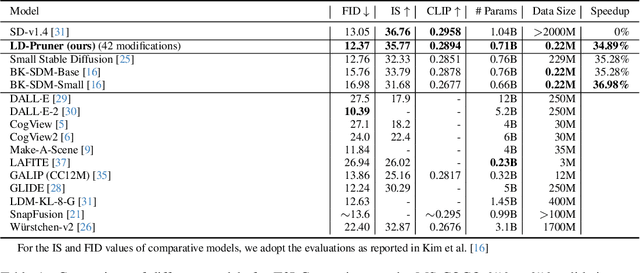
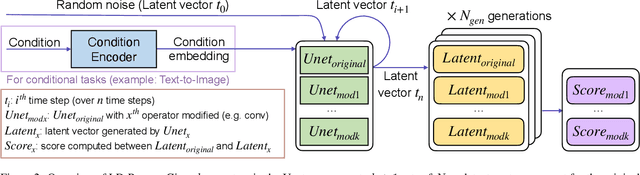
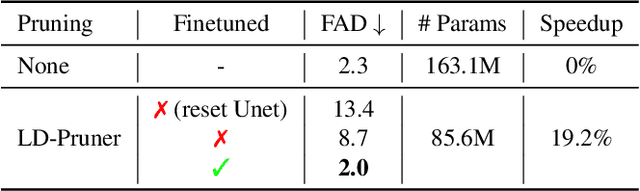
Latent Diffusion Models (LDMs) have emerged as powerful generative models, known for delivering remarkable results under constrained computational resources. However, deploying LDMs on resource-limited devices remains a complex issue, presenting challenges such as memory consumption and inference speed. To address this issue, we introduce LD-Pruner, a novel performance-preserving structured pruning method for compressing LDMs. Traditional pruning methods for deep neural networks are not tailored to the unique characteristics of LDMs, such as the high computational cost of training and the absence of a fast, straightforward and task-agnostic method for evaluating model performance. Our method tackles these challenges by leveraging the latent space during the pruning process, enabling us to effectively quantify the impact of pruning on model performance, independently of the task at hand. This targeted pruning of components with minimal impact on the output allows for faster convergence during training, as the model has less information to re-learn, thereby addressing the high computational cost of training. Consequently, our approach achieves a compressed model that offers improved inference speed and reduced parameter count, while maintaining minimal performance degradation. We demonstrate the effectiveness of our approach on three different tasks: text-to-image (T2I) generation, Unconditional Image Generation (UIG) and Unconditional Audio Generation (UAG). Notably, we reduce the inference time of Stable Diffusion (SD) by 34.9% while simultaneously improving its FID by 5.2% on MS-COCO T2I benchmark. This work paves the way for more efficient pruning methods for LDMs, enhancing their applicability.
EdgeFusion: On-Device Text-to-Image Generation
Apr 18, 2024The intensive computational burden of Stable Diffusion (SD) for text-to-image generation poses a significant hurdle for its practical application. To tackle this challenge, recent research focuses on methods to reduce sampling steps, such as Latent Consistency Model (LCM), and on employing architectural optimizations, including pruning and knowledge distillation. Diverging from existing approaches, we uniquely start with a compact SD variant, BK-SDM. We observe that directly applying LCM to BK-SDM with commonly used crawled datasets yields unsatisfactory results. It leads us to develop two strategies: (1) leveraging high-quality image-text pairs from leading generative models and (2) designing an advanced distillation process tailored for LCM. Through our thorough exploration of quantization, profiling, and on-device deployment, we achieve rapid generation of photo-realistic, text-aligned images in just two steps, with latency under one second on resource-limited edge devices.
LatentSwap: An Efficient Latent Code Mapping Framework for Face Swapping
Mar 02, 2024



We propose LatentSwap, a simple face swapping framework generating a face swap latent code of a given generator. Utilizing randomly sampled latent codes, our framework is light and does not require datasets besides employing the pre-trained models, with the training procedure also being fast and straightforward. The loss objective consists of only three terms, and can effectively control the face swap results between source and target images. By attaching a pre-trained GAN inversion model independent to the model and using the StyleGAN2 generator, our model produces photorealistic and high-resolution images comparable to other competitive face swap models. We show that our framework is applicable to other generators such as StyleNeRF, paving a way to 3D-aware face swapping and is also compatible with other downstream StyleGAN2 generator tasks. The source code and models can be found at \url{https://github.com/usingcolor/LatentSwap}.
Shortened LLaMA: A Simple Depth Pruning for Large Language Models
Feb 05, 2024Structured pruning of modern large language models (LLMs) has emerged as a way of decreasing their high computational needs. Width pruning reduces the size of projection weight matrices (e.g., by removing attention heads) while maintaining the number of layers. Depth pruning, in contrast, removes entire layers or blocks, while keeping the size of the remaining weights unchanged. Most current research focuses on either width-only or a blend of width and depth pruning, with little comparative analysis between the two units (width vs. depth) concerning their impact on LLM inference efficiency. In this work, we show that a simple depth pruning approach can compete with recent width pruning methods in terms of zero-shot task performance. Our pruning method boosts inference speeds, especially under memory-constrained conditions that require limited batch sizes for running LLMs, where width pruning is ineffective. We hope this work can help deploy LLMs on local and edge devices.
On Architectural Compression of Text-to-Image Diffusion Models
May 25, 2023Exceptional text-to-image (T2I) generation results of Stable Diffusion models (SDMs) come with substantial computational demands. To resolve this issue, recent research on efficient SDMs has prioritized reducing the number of sampling steps and utilizing network quantization. Orthogonal to these directions, this study highlights the power of classical architectural compression for general-purpose T2I synthesis by introducing block-removed knowledge-distilled SDMs (BK-SDMs). We eliminate several residual and attention blocks from the U-Net of SDMs, obtaining over a 30% reduction in the number of parameters, MACs per sampling step, and latency. We conduct distillation-based pretraining with only 0.22M LAION pairs (fewer than 0.1% of the full training pairs) on a single A100 GPU. Despite being trained with limited resources, our compact models can imitate the original SDM by benefiting from transferred knowledge and achieve competitive results against larger multi-billion parameter models on the zero-shot MS-COCO benchmark. Moreover, we demonstrate the applicability of our lightweight pretrained models in personalized generation with DreamBooth finetuning.
Talking Face Generation with Multilingual TTS
May 13, 2022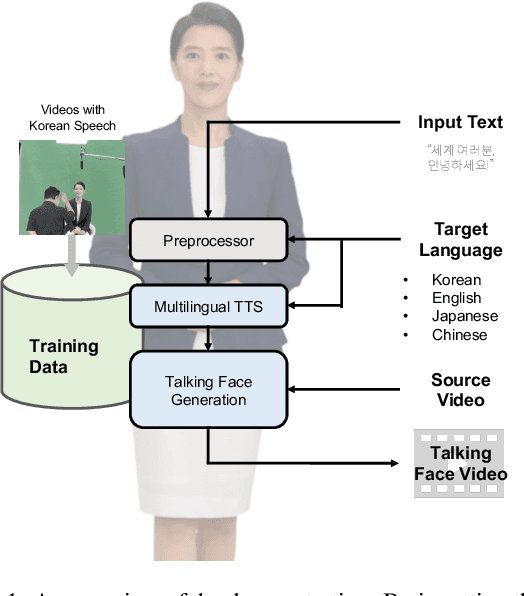
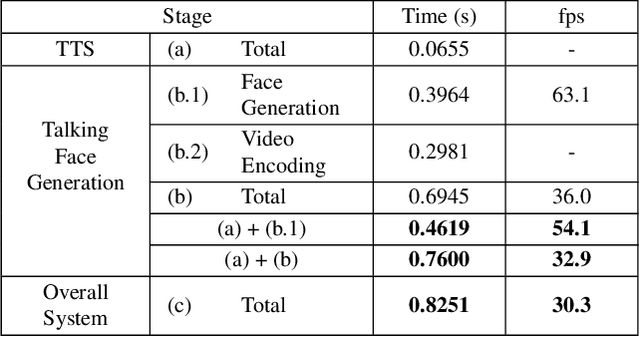


In this work, we propose a joint system combining a talking face generation system with a text-to-speech system that can generate multilingual talking face videos from only the text input. Our system can synthesize natural multilingual speeches while maintaining the vocal identity of the speaker, as well as lip movements synchronized to the synthesized speech. We demonstrate the generalization capabilities of our system by selecting four languages (Korean, English, Japanese, and Chinese) each from a different language family. We also compare the outputs of our talking face generation model to outputs of a prior work that claims multilingual support. For our demo, we add a translation API to the preprocessing stage and present it in the form of a neural dubber so that users can utilize the multilingual property of our system more easily.
Deep User Identification Model with Multiple Biometrics
Sep 03, 2019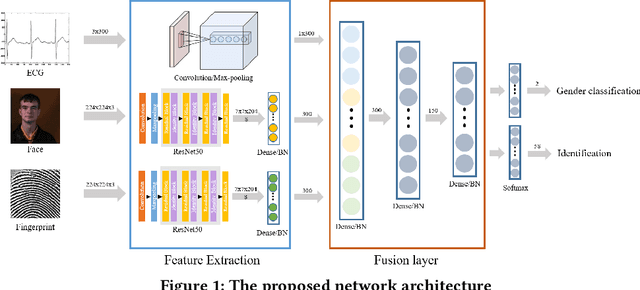
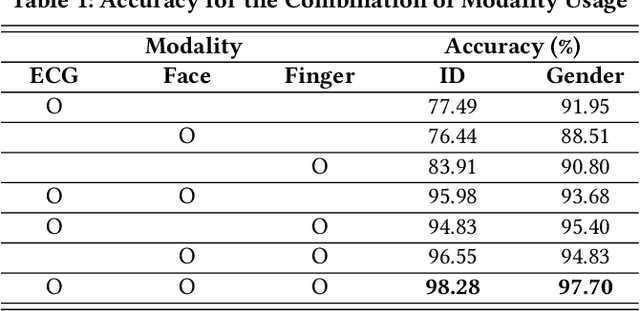
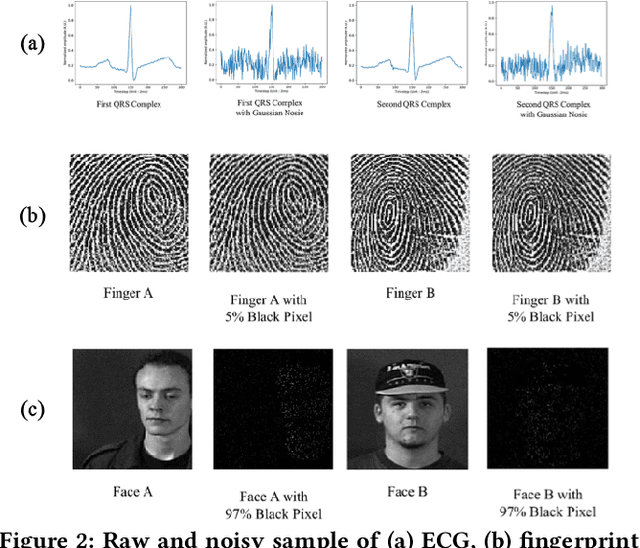

Identification using biometrics is an important yet challenging task. Abundant research has been conducted on identifying personal identity or gender using given signals. Various types of biometrics such as electrocardiogram (ECG), electroencephalogram (EEG), face, fingerprint, and voice have been used for these tasks. Most research has only focused on single modality or a single task, while the combination of input modality or tasks is yet to be investigated. In this paper, we propose deep identification and gender classification using multimodal biometrics. Our model uses ECG, fingerprint, and facial data. It then performs two tasks: gender identification and classification. By engaging multi-modality, a single model can handle various input domains without training each modality independently, and the correlation between domains can increase its generalization performance on the tasks.