 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Poisoning Attacks on EEG Signal-based Risk Assessment Systems
Feb 08, 2023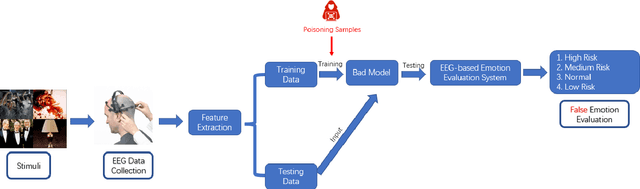
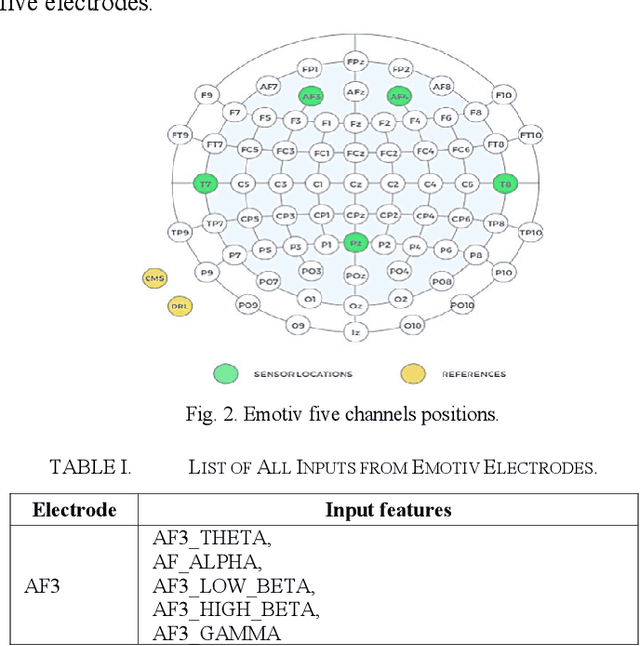
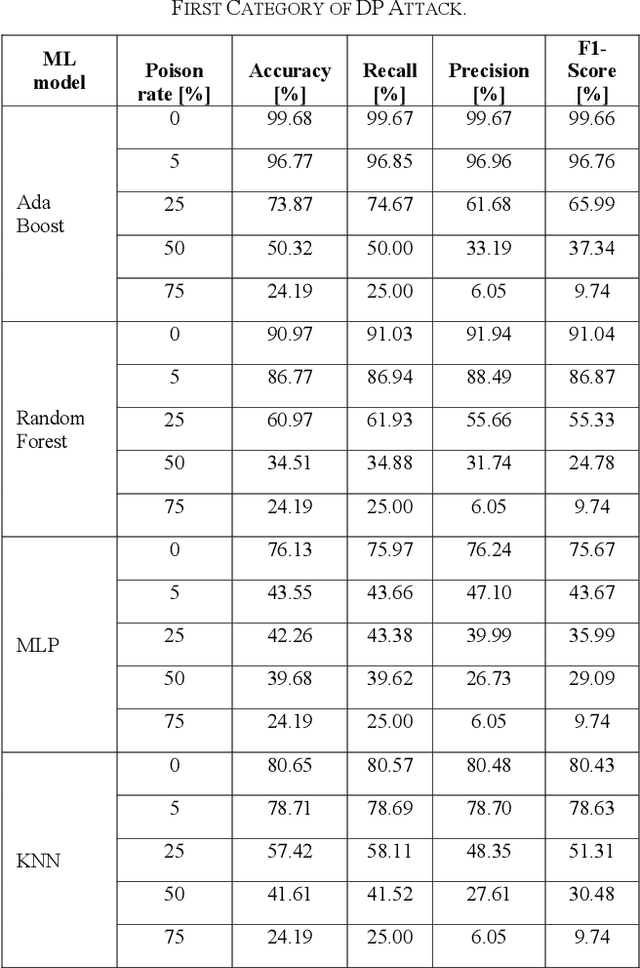
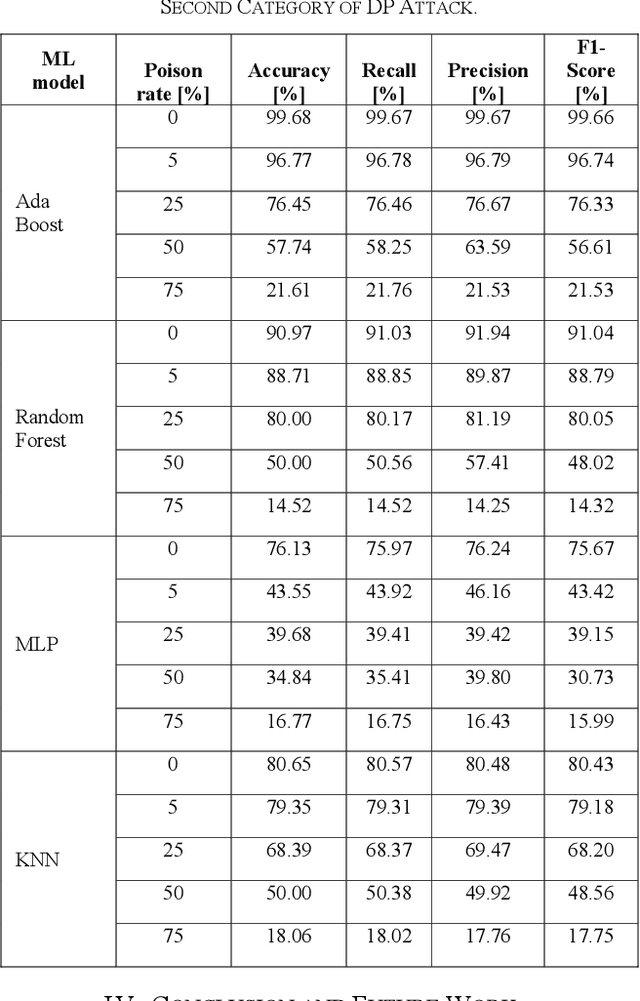
Industrial insider risk assessment using electroencephalogram (EEG) signals has consistently attracted a lot of research attention. However, EEG signal-based risk assessment systems, which could evaluate the emotional states of humans, have shown several vulnerabilities to data poison attacks. In this paper, from the attackers' perspective, data poison attacks involving label-flipping occurring in the training stages of different machine learning models intrude on the EEG signal-based risk assessment systems using these machine learning models. This paper aims to propose two categories of label-flipping methods to attack different machine learning classifiers including Adaptive Boosting (AdaBoost), Multilayer Perceptron (MLP), Random Forest, and K-Nearest Neighbors (KNN) dedicated to the classification of 4 different human emotions using EEG signals. This aims to degrade the performance of the aforementioned machine learning models concerning the classification task. The experimental results show that the proposed data poison attacks are model-agnostically effective whereas different models have different resilience to the data poison attacks.
Explainable Label-flipping Attacks on Human Emotion Assessment System
Feb 08, 2023This paper's main goal is to provide an attacker's point of view on data poisoning assaults that use label-flipping during the training phase of systems that use electroencephalogram (EEG) signals to evaluate human emotion. To attack different machine learning classifiers such as Adaptive Boosting (AdaBoost) and Random Forest dedicated to the classification of 4 different human emotions using EEG signals, this paper proposes two scenarios of label-flipping methods. The results of the studies show that the proposed data poison attacksm based on label-flipping are successful regardless of the model, but different models show different degrees of resistance to the assaults. In addition, numerous Explainable Artificial Intelligence (XAI) techniques are used to explain the data poison attacks on EEG signal-based human emotion evaluation systems.
Explainable Data Poison Attacks on Human Emotion Evaluation Systems based on EEG Signals
Jan 17, 2023



The major aim of this paper is to explain the data poisoning attacks using label-flipping during the training stage of the electroencephalogram (EEG) signal-based human emotion evaluation systems deploying Machine Learning models from the attackers' perspective. Human emotion evaluation using EEG signals has consistently attracted a lot of research attention. The identification of human emotional states based on EEG signals is effective to detect potential internal threats caused by insider individuals. Nevertheless, EEG signal-based human emotion evaluation systems have shown several vulnerabilities to data poison attacks. The findings of the experiments demonstrate that the suggested data poison assaults are model-independently successful, although various models exhibit varying levels of resilience to the attacks. In addition, the data poison attacks on the EEG signal-based human emotion evaluation systems are explained with several Explainable Artificial Intelligence (XAI) methods, including Shapley Additive Explanation (SHAP) values, Local Interpretable Model-agnostic Explanations (LIME), and Generated Decision Trees. And the codes of this paper are publicly available on GitHub.
A Late Multi-Modal Fusion Model for Detecting Hybrid Spam E-mail
Oct 26, 2022In recent years, spammers are now trying to obfuscate their intents by introducing hybrid spam e-mail combining both image and text parts, which is more challenging to detect in comparison to e-mails containing text or image only. The motivation behind this research is to design an effective approach filtering out hybrid spam e-mails to avoid situations where traditional text-based or image-baesd only filters fail to detect hybrid spam e-mails. To the best of our knowledge, a few studies have been conducted with the goal of detecting hybrid spam e-mails. Ordinarily, Optical Character Recognition (OCR) technology is used to eliminate the image parts of spam by transforming images into text. However, the research questions are that although OCR scanning is a very successful technique in processing text-and-image hybrid spam, it is not an effective solution for dealing with huge quantities due to the CPU power required and the execution time it takes to scan e-mail files. And the OCR techniques are not always reliable in the transformation processes. To address such problems, we propose new late multi-modal fusion training frameworks for a text-and-image hybrid spam e-mail filtering system compared to the classical early fusion detection frameworks based on the OCR method. Convolutional Neural Network (CNN) and Continuous Bag of Words were implemented to extract features from image and text parts of hybrid spam respectively, whereas generated features were fed to sigmoid layer and Machine Learning based classifiers including Random Forest (RF), Decision Tree (DT), Naive Bayes (NB) and Support Vector Machine (SVM) to determine the e-mail ham or spam.
On the Robustness of Ensemble-Based Machine Learning Against Data Poisoning
Sep 28, 2022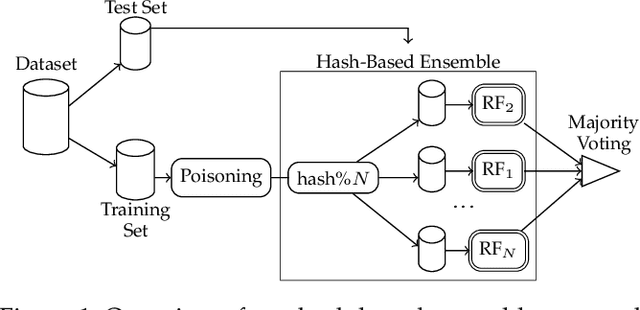


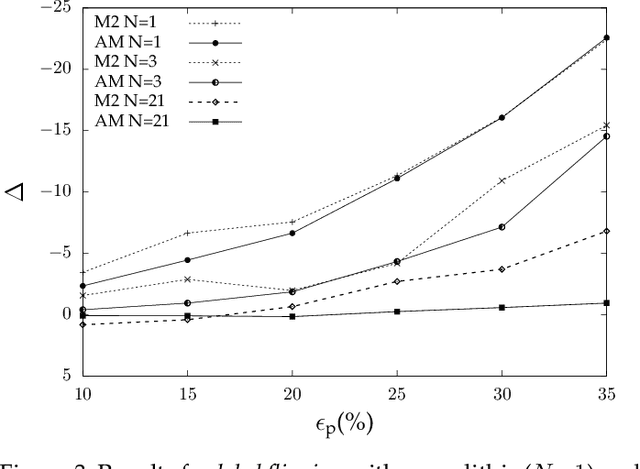
Machine learning is becoming ubiquitous. From financial to medicine, machine learning models are boosting decision-making processes and even outperforming humans in some tasks. This huge progress in terms of prediction quality does not however find a counterpart in the security of such models and corresponding predictions, where perturbations of fractions of the training set (poisoning) can seriously undermine the model accuracy. Research on poisoning attacks and defenses even predates the introduction of deep neural networks, leading to several promising solutions. Among them, ensemble-based defenses, where different models are trained on portions of the training set and their predictions are then aggregated, are getting significant attention, due to their relative simplicity and theoretical and practical guarantees. The work in this paper designs and implements a hash-based ensemble approach for ML robustness and evaluates its applicability and performance on random forests, a machine learning model proved to be more resistant to poisoning attempts on tabular datasets. An extensive experimental evaluation is carried out to evaluate the robustness of our approach against a variety of attacks, and compare it with a traditional monolithic model based on random forests.
Explainable Artificial Intelligence to Detect Image Spam Using Convolutional Neural Network
Sep 07, 2022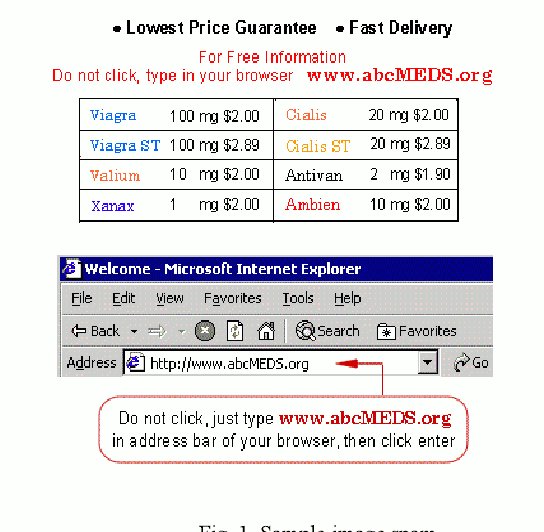
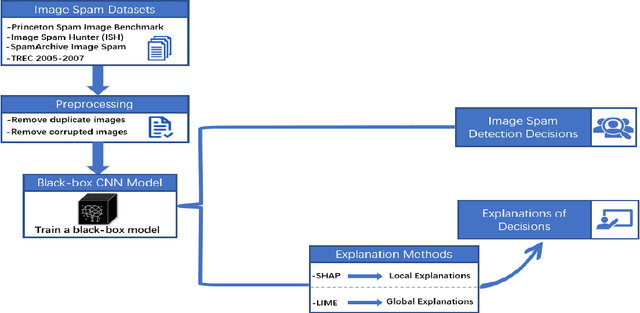
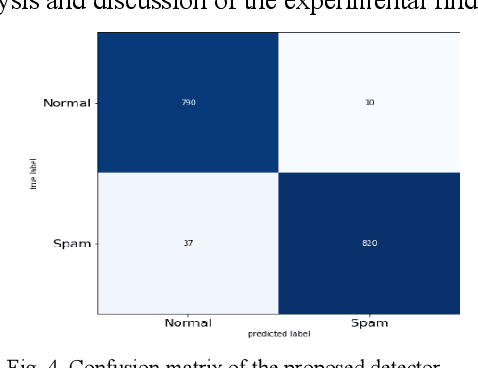

Image spam threat detection has continually been a popular area of research with the internet's phenomenal expansion. This research presents an explainable framework for detecting spam images using Convolutional Neural Network(CNN) algorithms and Explainable Artificial Intelligence (XAI) algorithms. In this work, we use CNN model to classify image spam respectively whereas the post-hoc XAI methods including Local Interpretable Model Agnostic Explanation (LIME) and Shapley Additive Explanations (SHAP) were deployed to provide explanations for the decisions that the black-box CNN models made about spam image detection. We train and then evaluate the performance of the proposed approach on a 6636 image dataset including spam images and normal images collected from three different publicly available email corpora. The experimental results show that the proposed framework achieved satisfactory detection results in terms of different performance metrics whereas the model-independent XAI algorithms could provide explanations for the decisions of different models which could be utilized for comparison for the future study.
Poisoning Attacks and Defenses on Artificial Intelligence: A Survey
Feb 22, 2022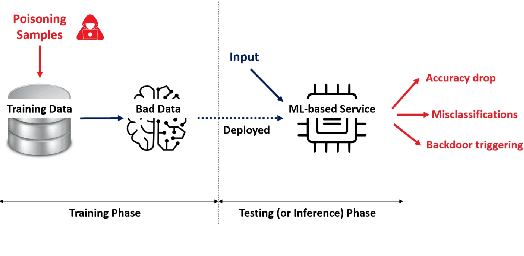
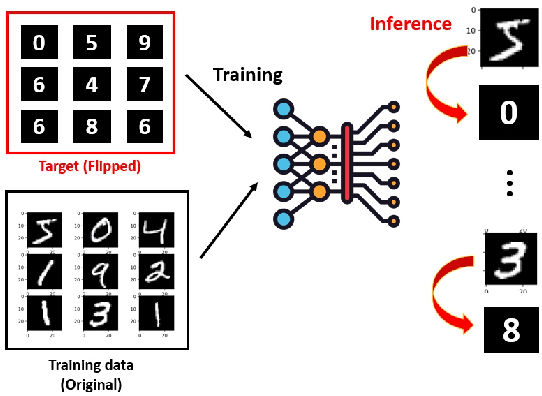
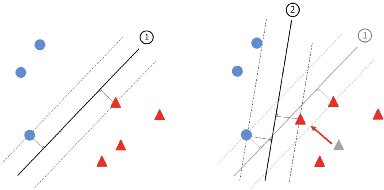
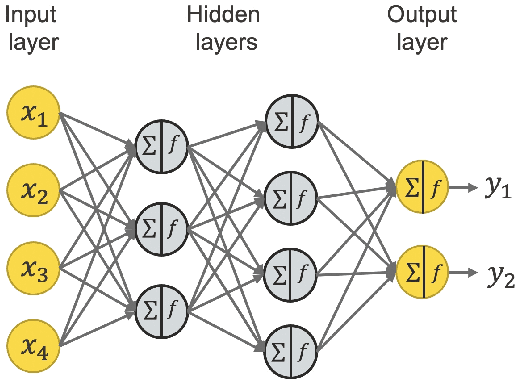
Machine learning models have been widely adopted in several fields. However, most recent studies have shown several vulnerabilities from attacks with a potential to jeopardize the integrity of the model, presenting a new window of research opportunity in terms of cyber-security. This survey is conducted with a main intention of highlighting the most relevant information related to security vulnerabilities in the context of machine learning (ML) classifiers; more specifically, directed towards training procedures against data poisoning attacks, representing a type of attack that consists of tampering the data samples fed to the model during the training phase, leading to a degradation in the models accuracy during the inference phase. This work compiles the most relevant insights and findings found in the latest existing literatures addressing this type of attacks. Moreover, this paper also covers several defense techniques that promise feasible detection and mitigation mechanisms, capable of conferring a certain level of robustness to a target model against an attacker. A thorough assessment is performed on the reviewed works, comparing the effects of data poisoning on a wide range of ML models in real-world conditions, performing quantitative and qualitative analyses. This paper analyzes the main characteristics for each approach including performance success metrics, required hyperparameters, and deployment complexity. Moreover, this paper emphasizes the underlying assumptions and limitations considered by both attackers and defenders along with their intrinsic properties such as: availability, reliability, privacy, accountability, interpretability, etc. Finally, this paper concludes by making references of some of main existing research trends that provide pathways towards future research directions in the field of cyber-security.
Deep Learning-Based Arrhythmia Detection Using RR-Interval Framed Electrocardiograms
Dec 01, 2020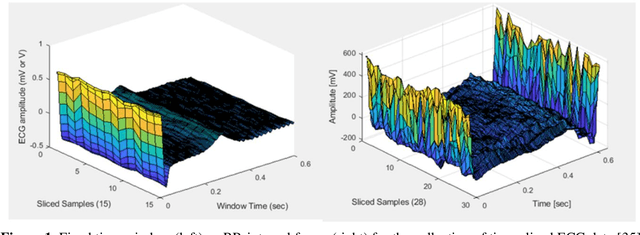
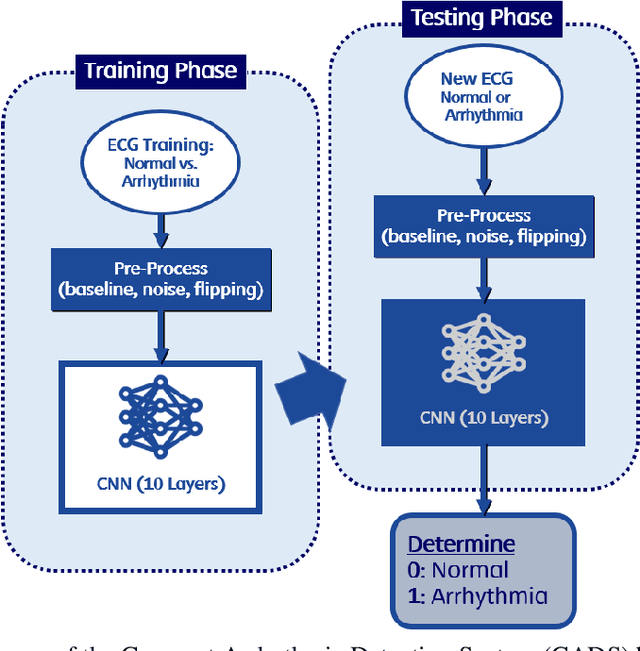
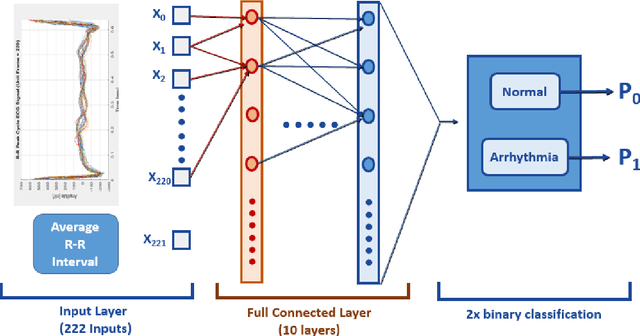
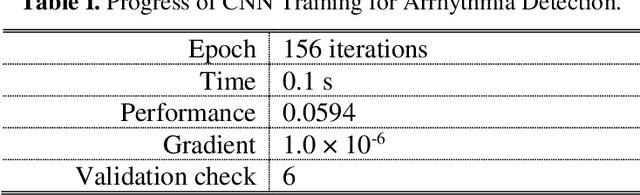
Deep learning applied to electrocardiogram (ECG) data can be used to achieve personal authentication in biometric security applications, but it has not been widely used to diagnose cardiovascular disorders. We developed a deep learning model for the detection of arrhythmia in which time-sliced ECG data representing the distance between successive R-peaks are used as the input for a convolutional neural network (CNN). The main objective is developing the compact deep learning based detect system which minimally uses the dataset but delivers the confident accuracy rate of the Arrhythmia detection. This compact system can be implemented in wearable devices or real-time monitoring equipment because the feature extraction step is not required for complex ECG waveforms, only the R-peak data is needed. The results of both tests indicated that the Compact Arrhythmia Detection System (CADS) matched the performance of conventional systems for the detection of arrhythmia in two consecutive test runs. All features of the CADS are fully implemented and publicly available in MATLAB.
Deep User Identification Model with Multiple Biometrics
Sep 03, 2019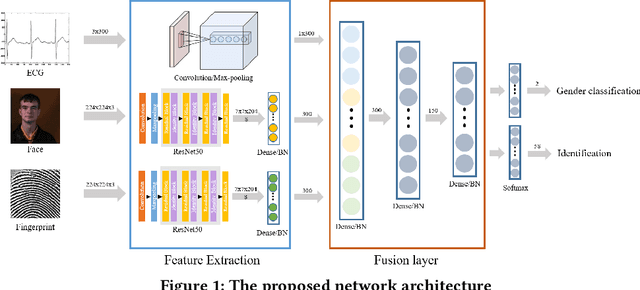
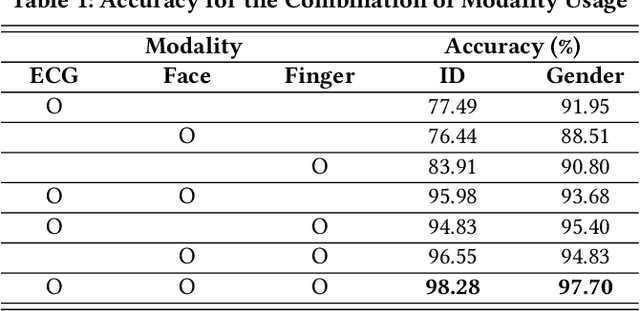
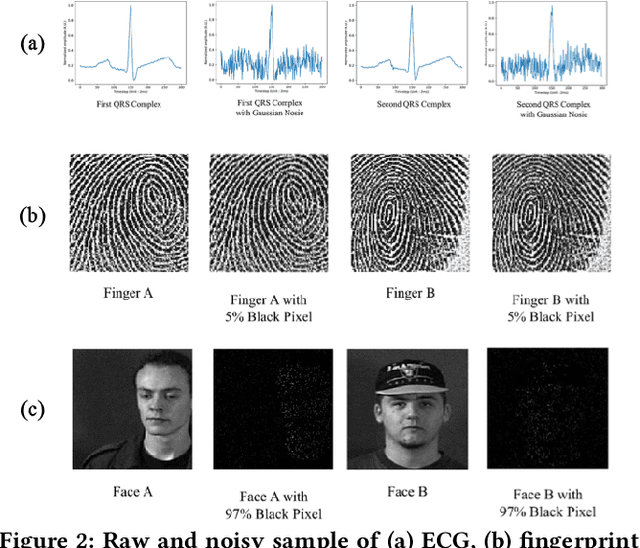

Identification using biometrics is an important yet challenging task. Abundant research has been conducted on identifying personal identity or gender using given signals. Various types of biometrics such as electrocardiogram (ECG), electroencephalogram (EEG), face, fingerprint, and voice have been used for these tasks. Most research has only focused on single modality or a single task, while the combination of input modality or tasks is yet to be investigated. In this paper, we propose deep identification and gender classification using multimodal biometrics. Our model uses ECG, fingerprint, and facial data. It then performs two tasks: gender identification and classification. By engaging multi-modality, a single model can handle various input domains without training each modality independently, and the correlation between domains can increase its generalization performance on the tasks.
An Enhanced Machine Learning-based Biometric Authentication System Using RR-Interval Framed Electrocardiograms
Aug 07, 2019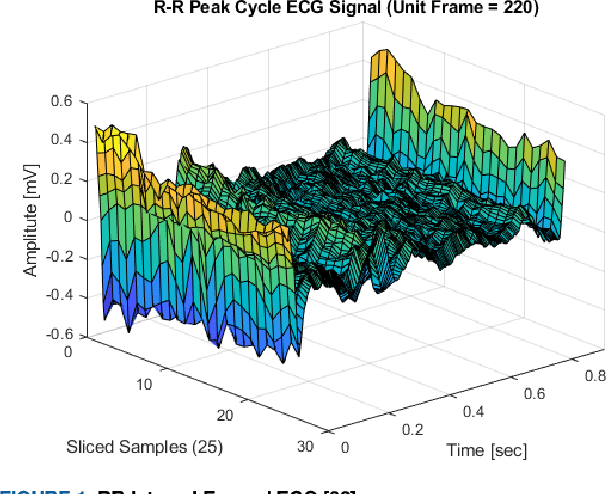
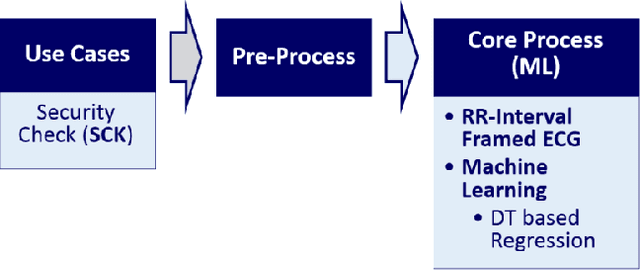
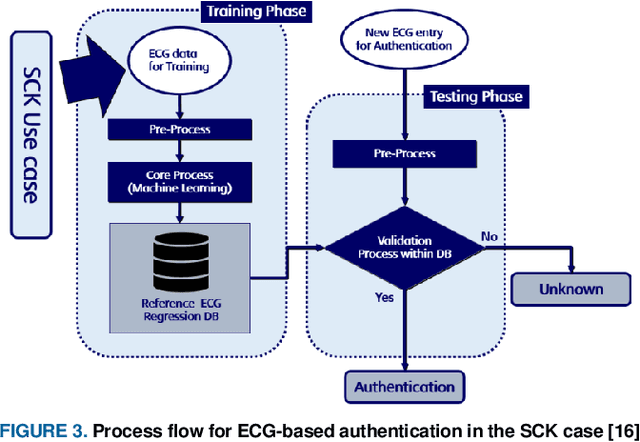
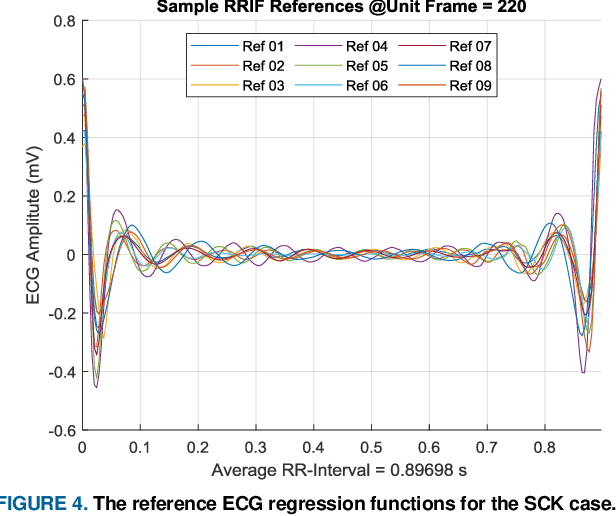
This paper is targeted in the area of biometric data enabled security system based on the machine learning for the digital health. The disadvantages of traditional authentication systems include the risks of forgetfulness, loss, and theft. Biometric authentication is therefore rapidly replacing traditional authentication methods and is becoming an everyday part of life. The electrocardiogram (ECG) was recently introduced as a biometric authentication system suitable for security checks. The proposed authentication system helps investigators studying ECG-based biometric authentication techniques to reshape input data by slicing based on the RR-interval, and defines the Overall Performance (OP), which is the combined performance metric of multiple authentication measures. We evaluated the performance of the proposed system using a confusion matrix and achieved up to 95% accuracy by compact data analysis. We also used the Amang ECG (amgecg) toolbox in MATLAB to investigate the upper-range control limit (UCL) based on the mean square error, which directly affects three authentication performance metrics: the accuracy, the number of accepted samples, and the OP. Using this approach, we found that the OP can be optimized by using a UCL of 0.0028, which indicates 61 accepted samples out of 70 and ensures that the proposed authentication system achieves an accuracy of 95%.