 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoisoning Attacks and Defenses on Artificial Intelligence: A Survey
Feb 22, 2022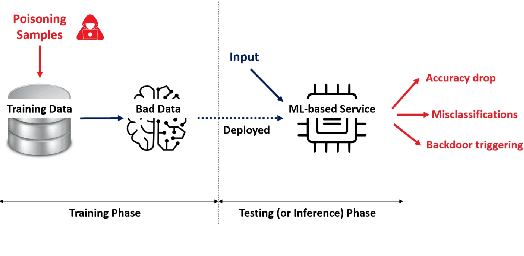
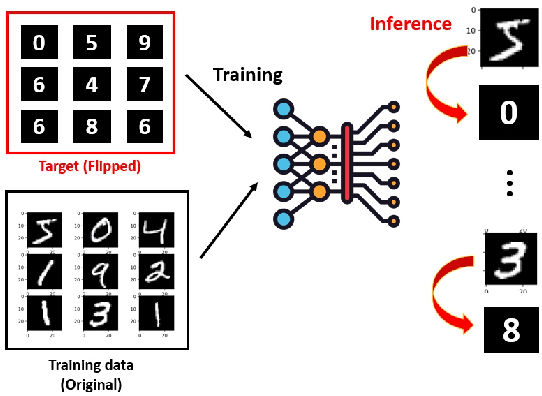
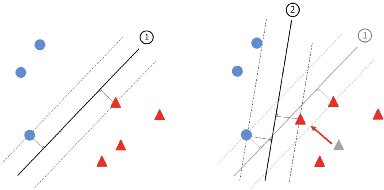
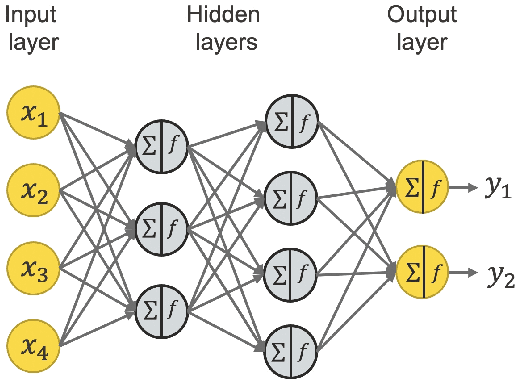
Machine learning models have been widely adopted in several fields. However, most recent studies have shown several vulnerabilities from attacks with a potential to jeopardize the integrity of the model, presenting a new window of research opportunity in terms of cyber-security. This survey is conducted with a main intention of highlighting the most relevant information related to security vulnerabilities in the context of machine learning (ML) classifiers; more specifically, directed towards training procedures against data poisoning attacks, representing a type of attack that consists of tampering the data samples fed to the model during the training phase, leading to a degradation in the models accuracy during the inference phase. This work compiles the most relevant insights and findings found in the latest existing literatures addressing this type of attacks. Moreover, this paper also covers several defense techniques that promise feasible detection and mitigation mechanisms, capable of conferring a certain level of robustness to a target model against an attacker. A thorough assessment is performed on the reviewed works, comparing the effects of data poisoning on a wide range of ML models in real-world conditions, performing quantitative and qualitative analyses. This paper analyzes the main characteristics for each approach including performance success metrics, required hyperparameters, and deployment complexity. Moreover, this paper emphasizes the underlying assumptions and limitations considered by both attackers and defenders along with their intrinsic properties such as: availability, reliability, privacy, accountability, interpretability, etc. Finally, this paper concludes by making references of some of main existing research trends that provide pathways towards future research directions in the field of cyber-security.