 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedSage: A Cybersecurity Generalist LLM
Jan 29, 2026Cybersecurity operations demand assistant LLMs that support diverse workflows without exposing sensitive data. Existing solutions either rely on proprietary APIs with privacy risks or on open models lacking domain adaptation. To bridge this gap, we curate 11.8B tokens of cybersecurity-focused continual pretraining data via large-scale web filtering and manual collection of high-quality resources, spanning 28.6K documents across frameworks, offensive techniques, and security tools. Building on this, we design an agentic augmentation pipeline that simulates expert workflows to generate 266K multi-turn cybersecurity samples for supervised fine-tuning. Combined with general open-source LLM data, these resources enable the training of RedSage, an open-source, locally deployable cybersecurity assistant with domain-aware pretraining and post-training. To rigorously evaluate the models, we introduce RedSage-Bench, a benchmark with 30K multiple-choice and 240 open-ended Q&A items covering cybersecurity knowledge, skills, and tool expertise. RedSage is further evaluated on established cybersecurity benchmarks (e.g., CTI-Bench, CyberMetric, SECURE) and general LLM benchmarks to assess broader generalization. At the 8B scale, RedSage achieves consistently better results, surpassing the baseline models by up to +5.59 points on cybersecurity benchmarks and +5.05 points on Open LLM Leaderboard tasks. These findings demonstrate that domain-aware agentic augmentation and pre/post-training can not only enhance cybersecurity-specific expertise but also help to improve general reasoning and instruction-following. All models, datasets, and code are publicly available.
HGCN(O): A Self-Tuning GCN HyperModel Toolkit for Outcome Prediction in Event-Sequence Data
Jul 30, 2025We propose HGCN(O), a self-tuning toolkit using Graph Convolutional Network (GCN) models for event sequence prediction. Featuring four GCN architectures (O-GCN, T-GCN, TP-GCN, TE-GCN) across the GCNConv and GraphConv layers, our toolkit integrates multiple graph representations of event sequences with different choices of node- and graph-level attributes and in temporal dependencies via edge weights, optimising prediction accuracy and stability for balanced and unbalanced datasets. Extensive experiments show that GCNConv models excel on unbalanced data, while all models perform consistently on balanced data. Experiments also confirm the superior performance of HGCN(O) over traditional approaches. Applications include Predictive Business Process Monitoring (PBPM), which predicts future events or states of a business process based on event logs.
STING-BEE: Towards Vision-Language Model for Real-World X-ray Baggage Security Inspection
Apr 03, 2025Advancements in Computer-Aided Screening (CAS) systems are essential for improving the detection of security threats in X-ray baggage scans. However, current datasets are limited in representing real-world, sophisticated threats and concealment tactics, and existing approaches are constrained by a closed-set paradigm with predefined labels. To address these challenges, we introduce STCray, the first multimodal X-ray baggage security dataset, comprising 46,642 image-caption paired scans across 21 threat categories, generated using an X-ray scanner for airport security. STCray is meticulously developed with our specialized protocol that ensures domain-aware, coherent captions, that lead to the multi-modal instruction following data in X-ray baggage security. This allows us to train a domain-aware visual AI assistant named STING-BEE that supports a range of vision-language tasks, including scene comprehension, referring threat localization, visual grounding, and visual question answering (VQA), establishing novel baselines for multi-modal learning in X-ray baggage security. Further, STING-BEE shows state-of-the-art generalization in cross-domain settings. Code, data, and models are available at https://divs1159.github.io/STING-BEE/.
Leonardo vindicated: Pythagorean trees for minimal reconstruction of the natural branching structures
Nov 12, 2024Trees continue to fascinate with their natural beauty and as engineering masterpieces optimal with respect to several independent criteria. Pythagorean tree is a well-known fractal design that realistically mimics the natural tree branching structures. We study various types of Pythagorean-like fractal trees with different shapes of the base, branching angles and relaxed scales in an attempt to identify and explain which variants are the closest match to the branching structures commonly observed in the natural world. Pursuing simultaneously the realism and minimalism of the fractal tree model, we have developed a flexibly parameterised and fast algorithm to grow and visually examine deep Pythagorean-inspired fractal trees with the capability to orderly over- or underestimate the Leonardo da Vinci's tree branching rule as well as control various imbalances and branching angles. We tested the realism of the generated fractal tree images by means of the classification accuracy of detecting natural tree with the transfer-trained deep Convolutional Neural Networks (CNNs). Having empirically established the parameters of the fractal trees that maximize the CNN's natural tree class classification accuracy we have translated them back to the scales and angles of branches and came to the interesting conclusions that support the da Vinci branching rule and golden ratio based scaling for both the shape of the branch and imbalance between the child branches, and claim the flexibly parameterized fractal trees can be used to generate artificial examples to train robust detectors of different species of trees.
A Visualized Malware Detection Framework with CNN and Conditional GAN
Sep 22, 2024Malware visualization analysis incorporating with Machine Learning (ML) has been proven to be a promising solution for improving security defenses on different platforms. In this work, we propose an integrated framework for addressing common problems experienced by ML utilizers in developing malware detection systems. Namely, a pictorial presentation system with extensions is designed to preserve the identities of benign/malign samples by encoding each variable into binary digits and mapping them into black and white pixels. A conditional Generative Adversarial Network based model is adopted to produce synthetic images and mitigate issues of imbalance classes. Detection models architected by Convolutional Neural Networks are for validating performances while training on datasets with and without artifactual samples. Result demonstrates accuracy rates of 98.51% and 97.26% for these two training scenarios.
A Quantization-based Technique for Privacy Preserving Distributed Learning
Jun 26, 2024The massive deployment of Machine Learning (ML) models raises serious concerns about data protection. Privacy-enhancing technologies (PETs) offer a promising first step, but hard challenges persist in achieving confidentiality and differential privacy in distributed learning. In this paper, we describe a novel, regulation-compliant data protection technique for the distributed training of ML models, applicable throughout the ML life cycle regardless of the underlying ML architecture. Designed from the data owner's perspective, our method protects both training data and ML model parameters by employing a protocol based on a quantized multi-hash data representation Hash-Comb combined with randomization. The hyper-parameters of our scheme can be shared using standard Secure Multi-Party computation protocols. Our experimental results demonstrate the robustness and accuracy-preserving properties of our approach.
Managing ML-Based Application Non-Functional Behavior: A Multi-Model Approach
Nov 21, 2023

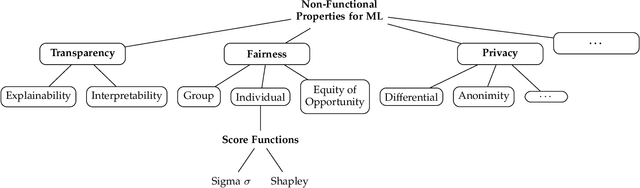
Modern applications are increasingly driven by Machine Learning (ML) models whose non-deterministic behavior is affecting the entire application life cycle from design to operation. The pervasive adoption of ML is urgently calling for approaches that guarantee a stable non-functional behavior of ML-based applications over time and across model changes. To this aim, non-functional properties of ML models, such as privacy, confidentiality, fairness, and explainability, must be monitored, verified, and maintained. This need is even more pressing when modern applications operate in the edge-cloud continuum, increasing their complexity and dynamicity. Existing approaches mostly focus on i) implementing classifier selection solutions according to the functional behavior of ML models, ii) finding new algorithmic solutions to this need, such as continuous re-training. In this paper, we propose a multi-model approach built on dynamic classifier selection, where multiple ML models showing similar non-functional properties are made available to the application and one model is selected over time according to (dynamic and unpredictable) contextual changes. Our solution goes beyond the state of the art by providing an architectural and methodological approach that continuously guarantees a stable non-functional behavior of ML-based applications, is applicable to different ML models, and is driven by non-functional properties assessed on the models themselves. It consists of a two-step process working during application operation, where model assessment verifies non-functional properties of ML models trained and selected at development time, and model substitution guarantees a continuous and stable support of non-functional properties. We experimentally evaluate our solution in a real-world scenario focusing on non-functional property fairness.
Tailoring Machine Learning for Process Mining
Jun 17, 2023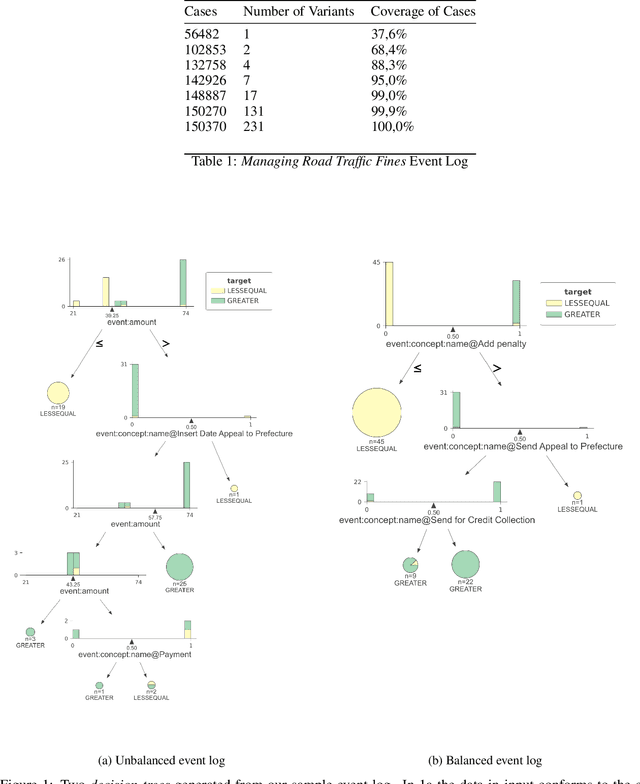
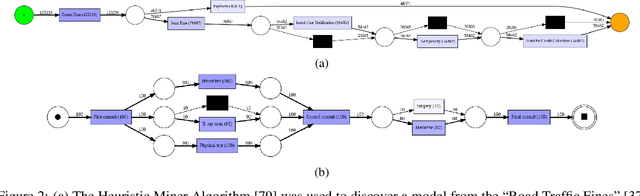
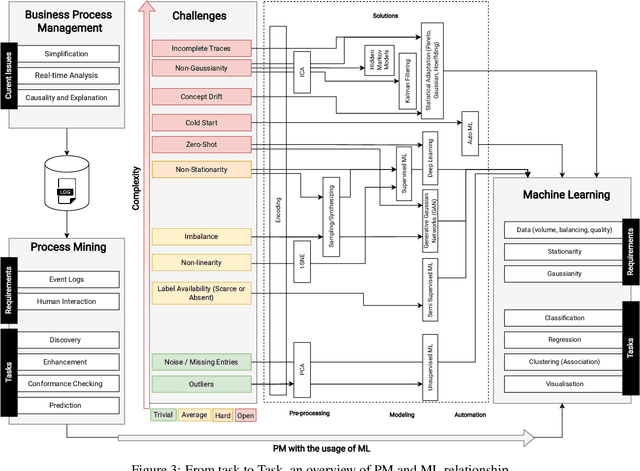
Machine learning models are routinely integrated into process mining pipelines to carry out tasks like data transformation, noise reduction, anomaly detection, classification, and prediction. Often, the design of such models is based on some ad-hoc assumptions about the corresponding data distributions, which are not necessarily in accordance with the non-parametric distributions typically observed with process data. Moreover, the learning procedure they follow ignores the constraints concurrency imposes to process data. Data encoding is a key element to smooth the mismatch between these assumptions but its potential is poorly exploited. In this paper, we argue that a deeper insight into the issues raised by training machine learning models with process data is crucial to ground a sound integration of process mining and machine learning. Our analysis of such issues is aimed at laying the foundation for a methodology aimed at correctly aligning machine learning with process mining requirements and stimulating the research to elaborate in this direction.
Towards Certification of Machine Learning-Based Distributed Systems
Jun 01, 2023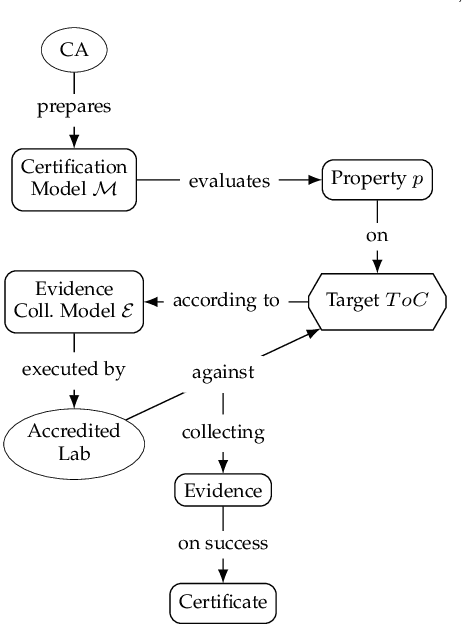
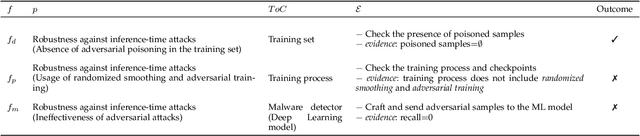
Machine Learning (ML) is increasingly used to drive the operation of complex distributed systems deployed on the cloud-edge continuum enabled by 5G. Correspondingly, distributed systems' behavior is becoming more non-deterministic in nature. This evolution of distributed systems requires the definition of new assurance approaches for the verification of non-functional properties. Certification, the most popular assurance technique for system and software verification, is not immediately applicable to systems whose behavior is determined by Machine Learning-based inference. However, there is an increasing push from policy makers, regulators, and industrial stakeholders towards the definition of techniques for the certification of non-functional properties (e.g., fairness, robustness, privacy) of ML. This article analyzes the challenges and deficiencies of current certification schemes, discusses open research issues and proposes a first certification scheme for ML-based distributed systems.
The Metaverse: Survey, Trends, Novel Pipeline Ecosystem & Future Directions
Apr 18, 2023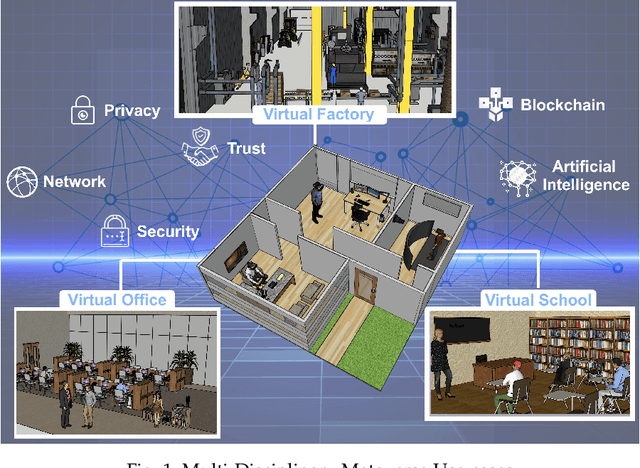

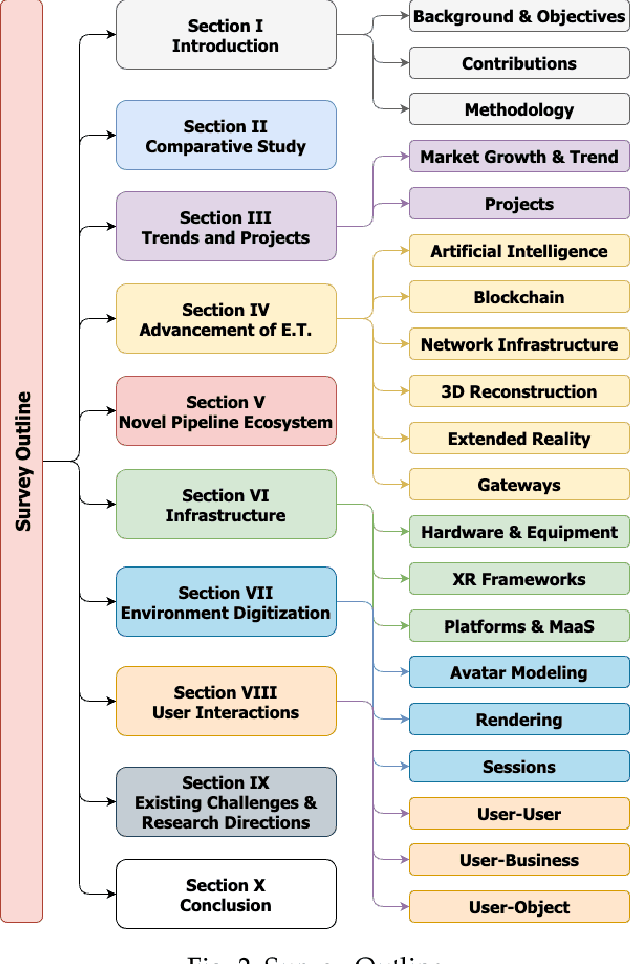

The Metaverse offers a second world beyond reality, where boundaries are non-existent, and possibilities are endless through engagement and immersive experiences using the virtual reality (VR) technology. Many disciplines can benefit from the advancement of the Metaverse when accurately developed, including the fields of technology, gaming, education, art, and culture. Nevertheless, developing the Metaverse environment to its full potential is an ambiguous task that needs proper guidance and directions. Existing surveys on the Metaverse focus only on a specific aspect and discipline of the Metaverse and lack a holistic view of the entire process. To this end, a more holistic, multi-disciplinary, in-depth, and academic and industry-oriented review is required to provide a thorough study of the Metaverse development pipeline. To address these issues, we present in this survey a novel multi-layered pipeline ecosystem composed of (1) the Metaverse computing, networking, communications and hardware infrastructure, (2) environment digitization, and (3) user interactions. For every layer, we discuss the components that detail the steps of its development. Also, for each of these components, we examine the impact of a set of enabling technologies and empowering domains (e.g., Artificial Intelligence, Security & Privacy, Blockchain, Business, Ethics, and Social) on its advancement. In addition, we explain the importance of these technologies to support decentralization, interoperability, user experiences, interactions, and monetization. Our presented study highlights the existing challenges for each component, followed by research directions and potential solutions. To the best of our knowledge, this survey is the most comprehensive and allows users, scholars, and entrepreneurs to get an in-depth understanding of the Metaverse ecosystem to find their opportunities and potentials for contribution.