 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Rule Learning for Outcome-Guided Process Model Discovery
Oct 31, 2025Event logs extracted from information systems offer a rich foundation for understanding and improving business processes. In many real-world applications, it is possible to distinguish between desirable and undesirable process executions, where desirable traces reflect efficient or compliant behavior, and undesirable ones may involve inefficiencies, rule violations, delays, or resource waste. This distinction presents an opportunity to guide process discovery in a more outcome-aware manner. Discovering a single process model without considering outcomes can yield representations poorly suited for conformance checking and performance analysis, as they fail to capture critical behavioral differences. Moreover, prioritizing one behavior over the other may obscure structural distinctions vital for understanding process outcomes. By learning interpretable discriminative rules over control-flow features, we group traces with similar desirability profiles and apply process discovery separately within each group. This results in focused and interpretable models that reveal the drivers of both desirable and undesirable executions. The approach is implemented as a publicly available tool and it is evaluated on multiple real-life event logs, demonstrating its effectiveness in isolating and visualizing critical process patterns.
Integrating Domain Knowledge into Process Discovery Using Large Language Models
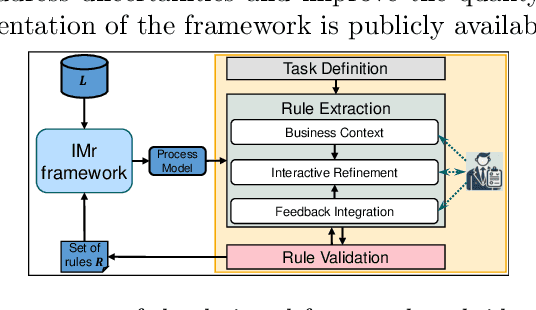
Oct 08, 2025Process discovery aims to derive process models from event logs, providing insights into operational behavior and forming a foundation for conformance checking and process improvement. However, models derived solely from event data may not accurately reflect the real process, as event logs are often incomplete or affected by noise, and domain knowledge, an important complementary resource, is typically disregarded. As a result, the discovered models may lack reliability for downstream tasks. We propose an interactive framework that incorporates domain knowledge, expressed in natural language, into the process discovery pipeline using Large Language Models (LLMs). Our approach leverages LLMs to extract declarative rules from textual descriptions provided by domain experts. These rules are used to guide the IMr discovery algorithm, which recursively constructs process models by combining insights from both the event log and the extracted rules, helping to avoid problematic process structures that contradict domain knowledge. The framework coordinates interactions among the LLM, domain experts, and a set of backend services. We present a fully implemented tool that supports this workflow and conduct an extensive evaluation of multiple LLMs and prompt engineering strategies. Our empirical study includes a case study based on a real-life event log with the involvement of domain experts, who assessed the usability and effectiveness of the framework.
Online Discovery of Simulation Models for Evolving Business Processes (Extended Version)
Jun 11, 2025Business Process Simulation (BPS) refers to techniques designed to replicate the dynamic behavior of a business process. Many approaches have been proposed to automatically discover simulation models from historical event logs, reducing the cost and time to manually design them. However, in dynamic business environments, organizations continuously refine their processes to enhance efficiency, reduce costs, and improve customer satisfaction. Existing techniques to process simulation discovery lack adaptability to real-time operational changes. In this paper, we propose a streaming process simulation discovery technique that integrates Incremental Process Discovery with Online Machine Learning methods. This technique prioritizes recent data while preserving historical information, ensuring adaptation to evolving process dynamics. Experiments conducted on four different event logs demonstrate the importance in simulation of giving more weight to recent data while retaining historical knowledge. Our technique not only produces more stable simulations but also exhibits robustness in handling concept drift, as highlighted in one of the use cases.
eST$^2$ Miner -- Process Discovery Based on Firing Partial Orders
Apr 11, 2025Process discovery generates process models from event logs. Traditionally, an event log is defined as a multiset of traces, where each trace is a sequence of events. The total order of the events in a sequential trace is typically based on their temporal occurrence. However, real-life processes are partially ordered by nature. Different activities can occur in different parts of the process and, thus, independently of each other. Therefore, the temporal total order of events does not necessarily reflect their causal order, as also causally unrelated events may be ordered in time. Only partial orders allow to express concurrency, duration, overlap, and uncertainty of events. Consequently, there is a growing need for process mining algorithms that can directly handle partially ordered input. In this paper, we combine two well-established and efficient algorithms, the eST Miner from the process mining community and the Firing LPO algorithm from the Petri net community, to introduce the eST$^2$ Miner. The eST$^2$ Miner is a process discovery algorithm that can directly handle partially ordered input, gives strong formal guarantees, offers good runtime and excellent space complexity, and can, thus, be used in real-life applications.
Bridging Domain Knowledge and Process Discovery Using Large Language Models
Aug 30, 2024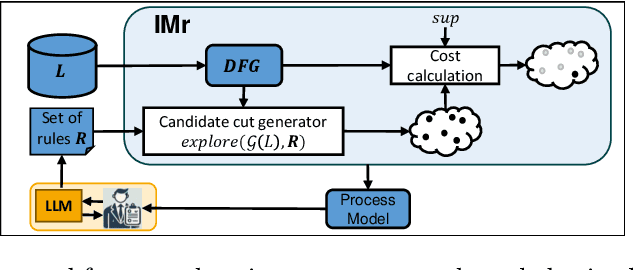


Discovering good process models is essential for different process analysis tasks such as conformance checking and process improvements. Automated process discovery methods often overlook valuable domain knowledge. This knowledge, including insights from domain experts and detailed process documentation, remains largely untapped during process discovery. This paper leverages Large Language Models (LLMs) to integrate such knowledge directly into process discovery. We use rules derived from LLMs to guide model construction, ensuring alignment with both domain knowledge and actual process executions. By integrating LLMs, we create a bridge between process knowledge expressed in natural language and the discovery of robust process models, advancing process discovery methodologies significantly. To showcase the usability of our framework, we conducted a case study with the UWV employee insurance agency, demonstrating its practical benefits and effectiveness.
People Make Better Edits: Measuring the Efficacy of LLM-Generated Counterfactually Augmented Data for Harmful Language Detection
Nov 02, 2023



NLP models are used in a variety of critical social computing tasks, such as detecting sexist, racist, or otherwise hateful content. Therefore, it is imperative that these models are robust to spurious features. Past work has attempted to tackle such spurious features using training data augmentation, including Counterfactually Augmented Data (CADs). CADs introduce minimal changes to existing training data points and flip their labels; training on them may reduce model dependency on spurious features. However, manually generating CADs can be time-consuming and expensive. Hence in this work, we assess if this task can be automated using generative NLP models. We automatically generate CADs using Polyjuice, ChatGPT, and Flan-T5, and evaluate their usefulness in improving model robustness compared to manually-generated CADs. By testing both model performance on multiple out-of-domain test sets and individual data point efficacy, our results show that while manual CADs are still the most effective, CADs generated by ChatGPT come a close second. One key reason for the lower performance of automated methods is that the changes they introduce are often insufficient to flip the original label.
Tailoring Machine Learning for Process Mining
Jun 17, 2023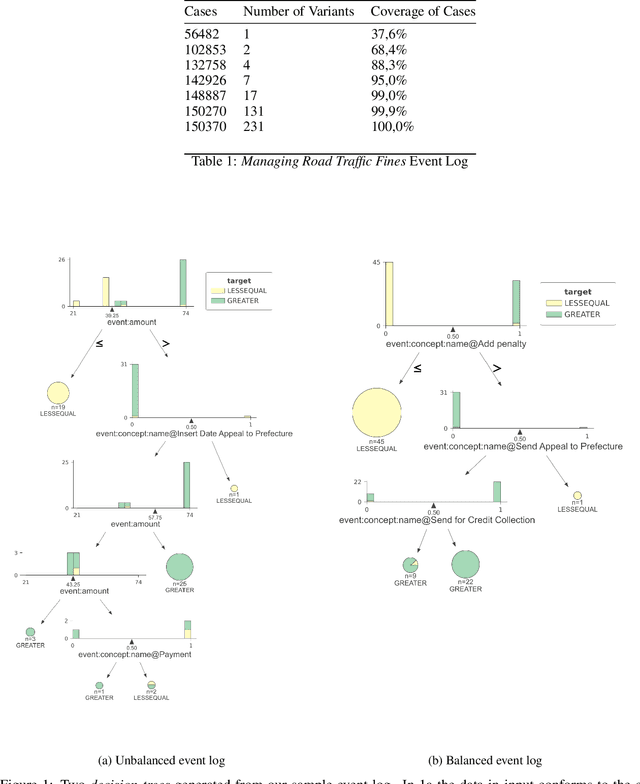
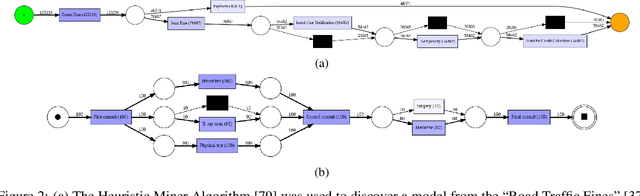
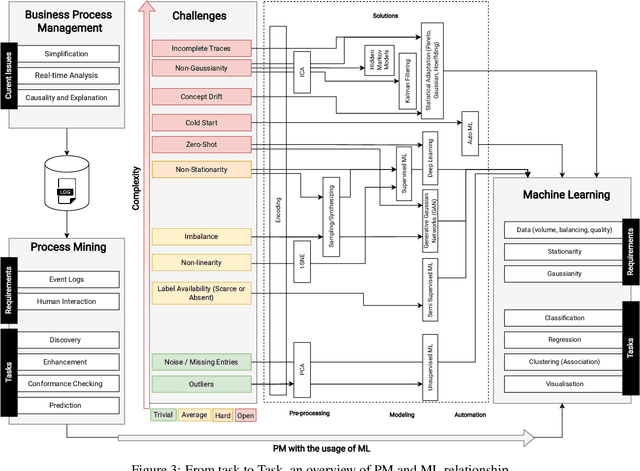
Machine learning models are routinely integrated into process mining pipelines to carry out tasks like data transformation, noise reduction, anomaly detection, classification, and prediction. Often, the design of such models is based on some ad-hoc assumptions about the corresponding data distributions, which are not necessarily in accordance with the non-parametric distributions typically observed with process data. Moreover, the learning procedure they follow ignores the constraints concurrency imposes to process data. Data encoding is a key element to smooth the mismatch between these assumptions but its potential is poorly exploited. In this paper, we argue that a deeper insight into the issues raised by training machine learning models with process data is crucial to ground a sound integration of process mining and machine learning. Our analysis of such issues is aimed at laying the foundation for a methodology aimed at correctly aligning machine learning with process mining requirements and stimulating the research to elaborate in this direction.
A Combined Approach of Process Mining and Rule-based AI for Study Planning and Monitoring in Higher Education
Nov 22, 2022This paper presents an approach of using methods of process mining and rule-based artificial intelligence to analyze and understand study paths of students based on campus management system data and study program models. Process mining techniques are used to characterize successful study paths, as well as to detect and visualize deviations from expected plans. These insights are combined with recommendations and requirements of the corresponding study programs extracted from examination regulations. Here, event calculus and answer set programming are used to provide models of the study programs which support planning and conformance checking while providing feedback on possible study plan violations. In its combination, process mining and rule-based artificial intelligence are used to support study planning and monitoring by deriving rules and recommendations for guiding students to more suitable study paths with higher success rates. Two applications will be implemented, one for students and one for study program designers.
Feature Recommendation for Structural Equation Model Discovery in Process Mining
Aug 13, 2021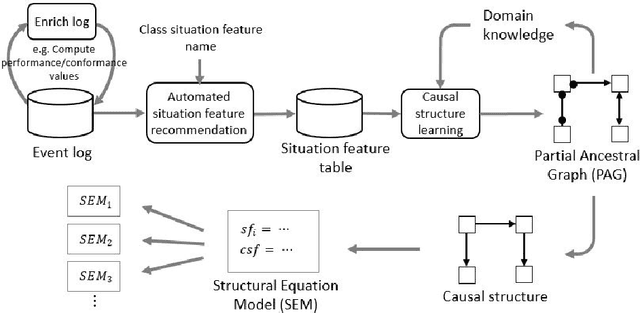
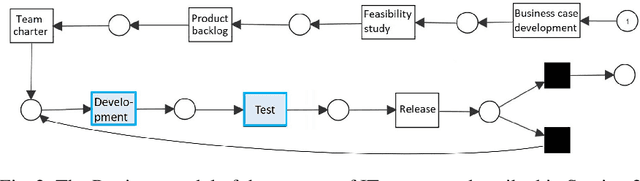
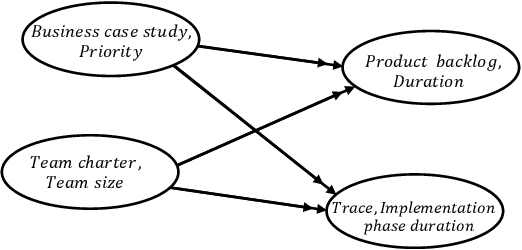
Process mining techniques can help organizations to improve their operational processes. Organizations can benefit from process mining techniques in finding and amending the root causes of performance or compliance problems. Considering the volume of the data and the number of features captured by the information system of today's companies, the task of discovering the set of features that should be considered in root cause analysis can be quite involving. In this paper, we propose a method for finding the set of (aggregated) features with a possible effect on the problem. The root cause analysis task is usually done by applying a machine learning technique to the data gathered from the information system supporting the processes. To prevent mixing up correlation and causation, which may happen because of interpreting the findings of machine learning techniques as causal, we propose a method for discovering the structural equation model of the process that can be used for root cause analysis. We have implemented the proposed method as a plugin in ProM and we have evaluated it using two real and synthetic event logs. These experiments show the validity and effectiveness of the proposed methods.
Removing Operational Friction Using Process Mining: Challenges Provided by the Internet of Production (IoP)
Jul 27, 2021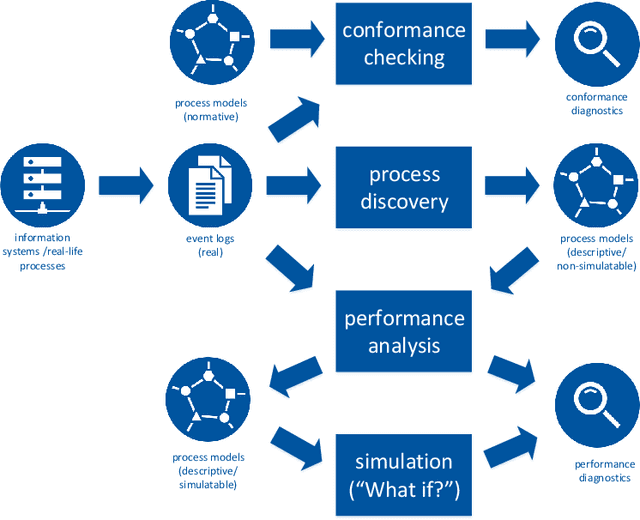
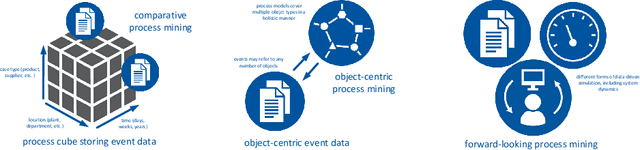
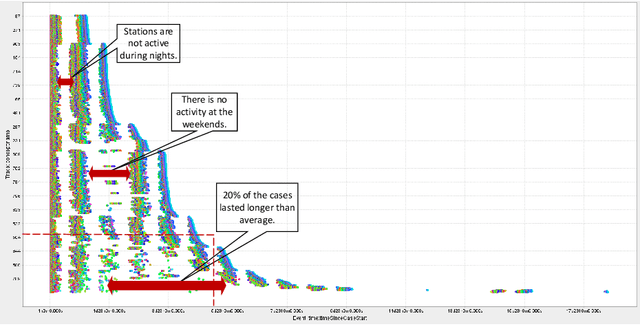
Operational processes in production, logistics, material handling, maintenance, etc., are supported by cyber-physical systems combining hardware and software components. As a result, the digital and the physical world are closely aligned, and it is possible to track operational processes in detail (e.g., using sensors). The abundance of event data generated by today's operational processes provides opportunities and challenges for process mining techniques supporting process discovery, performance analysis, and conformance checking. Using existing process mining tools, it is already possible to automatically discover process models and uncover performance and compliance problems. In the DFG-funded Cluster of Excellence "Internet of Production" (IoP), process mining is used to create "digital shadows" to improve a wide variety of operational processes. However, operational processes are dynamic, distributed, and complex. Driven by the challenges identified in the IoP cluster, we work on novel techniques for comparative process mining (comparing process variants for different products at different locations at different times), object-centric process mining (to handle processes involving different types of objects that interact), and forward-looking process mining (to explore "What if?" questions). By addressing these challenges, we aim to develop valuable "digital shadows" that can be used to remove operational friction.