 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredit Card Fraud Detection Using Asexual Reproduction Optimization
May 31, 2023


As the number of credit card users has increased, detecting fraud in this domain has become a vital issue. Previous literature has applied various supervised and unsupervised machine learning methods to find an effective fraud detection system. However, some of these methods require an enormous amount of time to achieve reasonable accuracy. In this paper, an Asexual Reproduction Optimization (ARO) approach was employed, which is a supervised method to detect credit card fraud. ARO refers to a kind of production in which one parent produces some offspring. By applying this method and sampling just from the majority class, the effectiveness of the classification is increased. A comparison to Artificial Immune Systems (AIS), which is one of the best methods implemented on current datasets, has shown that the proposed method is able to remarkably reduce the required training time and at the same time increase the recall that is important in fraud detection problems. The obtained results show that ARO achieves the best cost in a short time, and consequently, it can be considered a real-time fraud detection system.
Clustering Object-Centric Event Logs
Jul 26, 2022


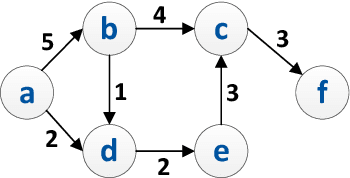
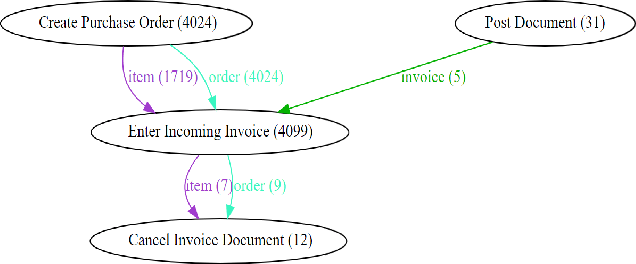
Process mining provides various algorithms to analyze process executions based on event data. Process discovery, the most prominent category of process mining techniques, aims to discover process models from event logs, however, it leads to spaghetti models when working with real-life data. Therefore, several clustering techniques have been proposed on top of traditional event logs (i.e., event logs with a single case notion) to reduce the complexity of process models and discover homogeneous subsets of cases. Nevertheless, in real-life processes, particularly in the context of Business-to-Business (B2B) processes, multiple objects are involved in a process. Recently, Object-Centric Event Logs (OCELs) have been introduced to capture the information of such processes, and several process discovery techniques have been developed on top of OCELs. Yet, the output of the proposed discovery techniques on real OCELs leads to more informative but also more complex models. In this paper, we propose a clustering-based approach to cluster similar objects in OCELs to simplify the obtained process models. Using a case study of a real B2B process, we demonstrate that our approach reduces the complexity of the process models and generates coherent subsets of objects which help the end-users gain insights into the process.
Predictive Object-Centric Process Monitoring
Jul 20, 2022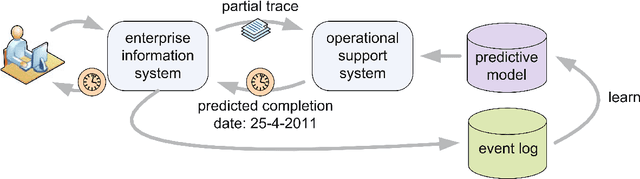
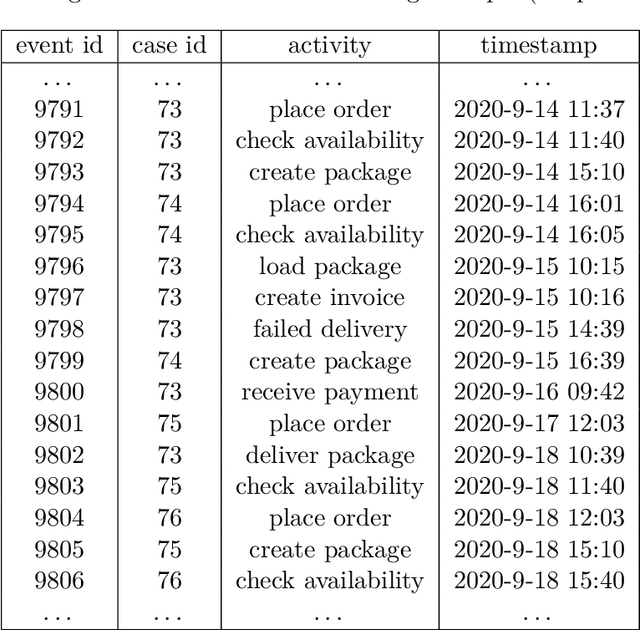
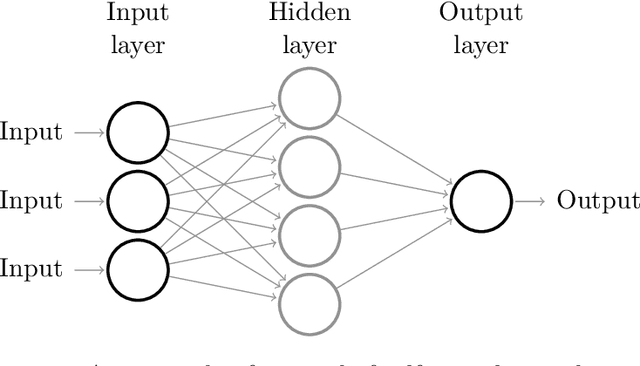
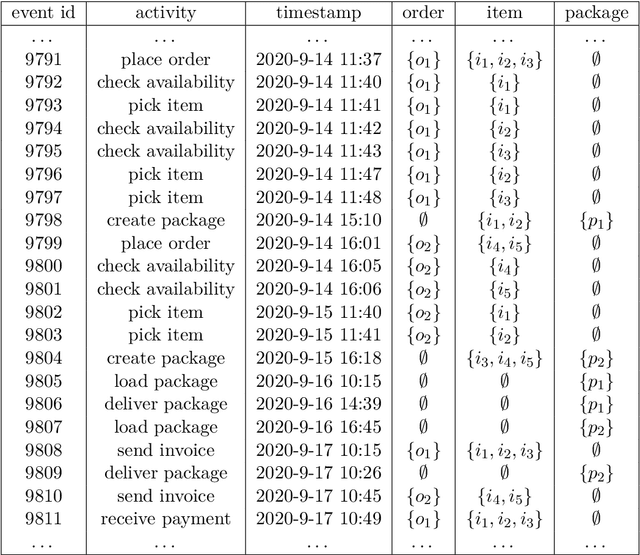
The automation and digitalization of business processes has resulted in large amounts of data captured in information systems, which can aid businesses in understanding their processes better, improve workflows, or provide operational support. By making predictions about ongoing processes, bottlenecks can be identified and resources reallocated, as well as insights gained into the state of a process instance (case). Traditionally, data is extracted from systems in the form of an event log with a single identifying case notion, such as an order id for an Order to Cash (O2C) process. However, real processes often have multiple object types, for example, order, item, and package, so a format that forces the use of a single case notion does not reflect the underlying relations in the data. The Object-Centric Event Log (OCEL) format was introduced to correctly capture this information. The state-of-the-art predictive methods have been tailored to only traditional event logs. This thesis shows that a prediction method utilizing Generative Adversarial Networks (GAN), Long Short-Term Memory (LSTM) architectures, and Sequence to Sequence models (Seq2seq), can be augmented with the rich data contained in OCEL. Objects in OCEL can have attributes that are useful in predicting the next event and timestamp, such as a priority class attribute for an object type package indicating slower or faster processing. In the metrics of sequence similarity of predicted remaining events and mean absolute error (MAE) of the timestamp, the approach in this thesis matches or exceeds previous research, depending on whether selected object attributes are useful features for the model. Additionally, this thesis provides a web interface to predict the next sequence of activities from user input.
Removing Operational Friction Using Process Mining: Challenges Provided by the Internet of Production (IoP)
Jul 27, 2021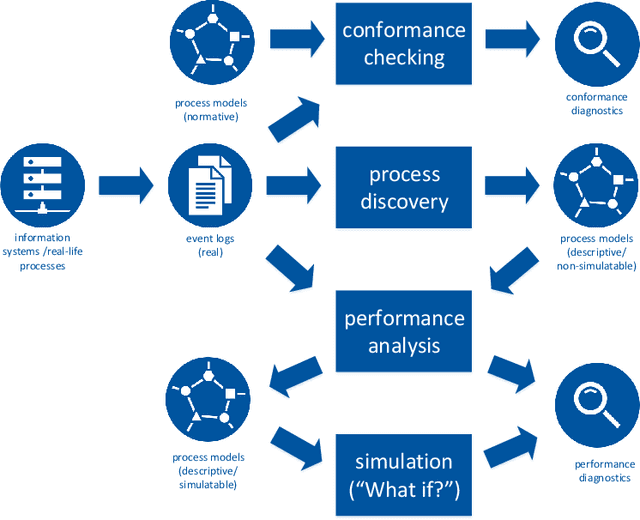
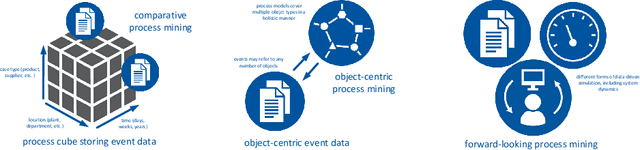
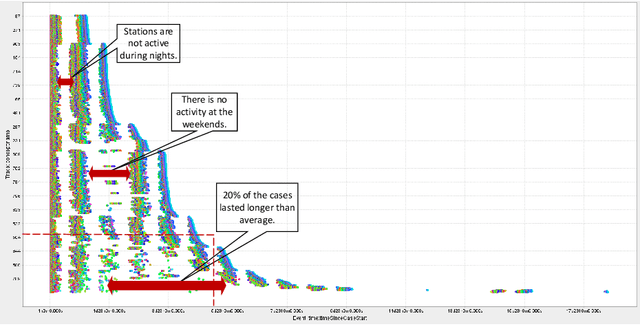
Operational processes in production, logistics, material handling, maintenance, etc., are supported by cyber-physical systems combining hardware and software components. As a result, the digital and the physical world are closely aligned, and it is possible to track operational processes in detail (e.g., using sensors). The abundance of event data generated by today's operational processes provides opportunities and challenges for process mining techniques supporting process discovery, performance analysis, and conformance checking. Using existing process mining tools, it is already possible to automatically discover process models and uncover performance and compliance problems. In the DFG-funded Cluster of Excellence "Internet of Production" (IoP), process mining is used to create "digital shadows" to improve a wide variety of operational processes. However, operational processes are dynamic, distributed, and complex. Driven by the challenges identified in the IoP cluster, we work on novel techniques for comparative process mining (comparing process variants for different products at different locations at different times), object-centric process mining (to handle processes involving different types of objects that interact), and forward-looking process mining (to explore "What if?" questions). By addressing these challenges, we aim to develop valuable "digital shadows" that can be used to remove operational friction.
Process Comparison Using Object-Centric Process Cubes
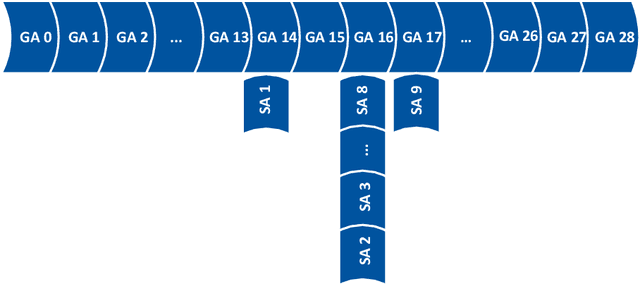
Mar 12, 2021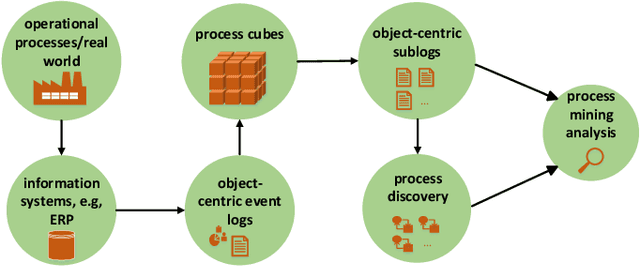
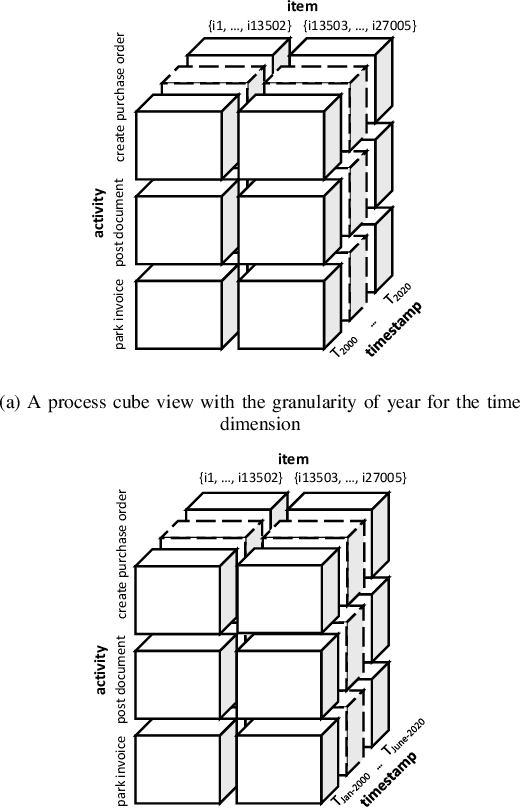
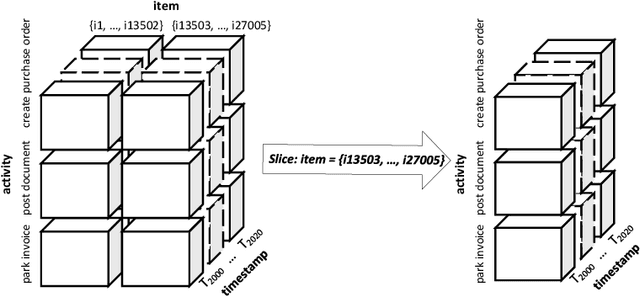
Process mining provides ways to analyze business processes. Common process mining techniques consider the process as a whole. However, in real-life business processes, different behaviors exist that make the overall process too complex to interpret. Process comparison is a branch of process mining that isolates different behaviors of the process from each other by using process cubes. Process cubes organize event data using different dimensions. Each cell contains a set of events that can be used as an input to apply process mining techniques. Existing work on process cubes assume single case notions. However, in real processes, several case notions (e.g., order, item, package, etc.) are intertwined. Object-centric process mining is a new branch of process mining addressing multiple case notions in a process. To make a bridge between object-centric process mining and process comparison, we propose a process cube framework, which supports process cube operations such as slice and dice on object-centric event logs. To facilitate the comparison, the framework is integrated with several object-centric process discovery approaches.