 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Driven Hallucination in Large Language Models: An Empirical Study on Process Modeling
Sep 18, 2025The utility of Large Language Models (LLMs) in analytical tasks is rooted in their vast pre-trained knowledge, which allows them to interpret ambiguous inputs and infer missing information. However, this same capability introduces a critical risk of what we term knowledge-driven hallucination: a phenomenon where the model's output contradicts explicit source evidence because it is overridden by the model's generalized internal knowledge. This paper investigates this phenomenon by evaluating LLMs on the task of automated process modeling, where the goal is to generate a formal business process model from a given source artifact. The domain of Business Process Management (BPM) provides an ideal context for this study, as many core business processes follow standardized patterns, making it likely that LLMs possess strong pre-trained schemas for them. We conduct a controlled experiment designed to create scenarios with deliberate conflict between provided evidence and the LLM's background knowledge. We use inputs describing both standard and deliberately atypical process structures to measure the LLM's fidelity to the provided evidence. Our work provides a methodology for assessing this critical reliability issue and raises awareness of the need for rigorous validation of AI-generated artifacts in any evidence-based domain.
Re-Thinking Process Mining in the AI-Based Agents Era
Aug 14, 2024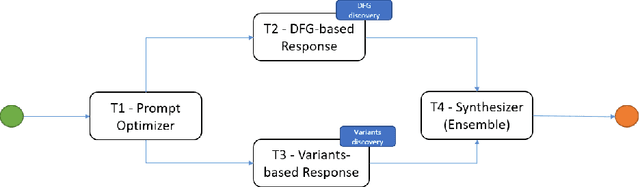



Large Language Models (LLMs) have emerged as powerful conversational interfaces, and their application in process mining (PM) tasks has shown promising results. However, state-of-the-art LLMs struggle with complex scenarios that demand advanced reasoning capabilities. In the literature, two primary approaches have been proposed for implementing PM using LLMs: providing textual insights based on a textual abstraction of the process mining artifact, and generating code executable on the original artifact. This paper proposes utilizing the AI-Based Agents Workflow (AgWf) paradigm to enhance the effectiveness of PM on LLMs. This approach allows for: i) the decomposition of complex tasks into simpler workflows, and ii) the integration of deterministic tools with the domain knowledge of LLMs. We examine various implementations of AgWf and the types of AI-based tasks involved. Additionally, we discuss the CrewAI implementation framework and present examples related to process mining.
PM-LLM-Benchmark: Evaluating Large Language Models on Process Mining Tasks
Jul 18, 2024



Large Language Models (LLMs) have the potential to semi-automate some process mining (PM) analyses. While commercial models are already adequate for many analytics tasks, the competitive level of open-source LLMs in PM tasks is unknown. In this paper, we propose PM-LLM-Benchmark, the first comprehensive benchmark for PM focusing on domain knowledge (process-mining-specific and process-specific) and on different implementation strategies. We focus also on the challenges in creating such a benchmark, related to the public availability of the data and on evaluation biases by the LLMs. Overall, we observe that most of the considered LLMs can perform some process mining tasks at a satisfactory level, but tiny models that would run on edge devices are still inadequate. We also conclude that while the proposed benchmark is useful for identifying LLMs that are adequate for process mining tasks, further research is needed to overcome the evaluation biases and perform a more thorough ranking of the competitive LLMs.
ProMoAI: Process Modeling with Generative AI
Mar 07, 2024ProMoAI is a novel tool that leverages Large Language Models (LLMs) to automatically generate process models from textual descriptions, incorporating advanced prompt engineering, error handling, and code generation techniques. Beyond automating the generation of complex process models, ProMoAI also supports process model optimization. Users can interact with the tool by providing feedback on the generated model, which is then used for refining the process model. ProMoAI utilizes the capabilities LLMs to offer a novel, AI-driven approach to process modeling, significantly reducing the barrier to entry for users without deep technical knowledge in process modeling.
Quantum Clustering with k-Means: a Hybrid Approach
Dec 15, 2022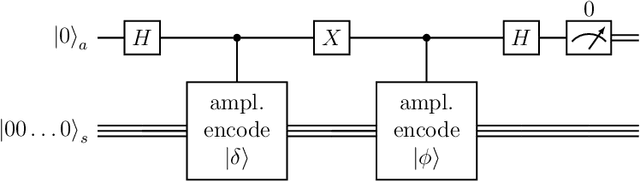
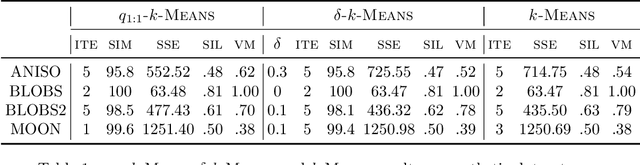
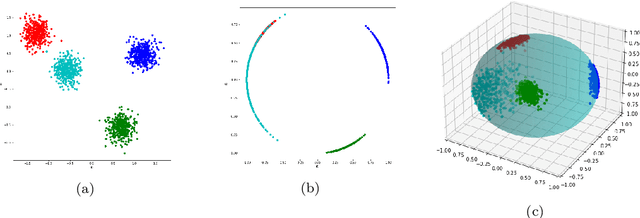
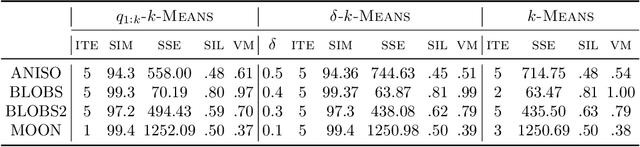
Quantum computing is a promising paradigm based on quantum theory for performing fast computations. Quantum algorithms are expected to surpass their classical counterparts in terms of computational complexity for certain tasks, including machine learning. In this paper, we design, implement, and evaluate three hybrid quantum k-Means algorithms, exploiting different degree of parallelism. Indeed, each algorithm incrementally leverages quantum parallelism to reduce the complexity of the cluster assignment step up to a constant cost. In particular, we exploit quantum phenomena to speed up the computation of distances. The core idea is that the computation of distances between records and centroids can be executed simultaneously, thus saving time, especially for big datasets. We show that our hybrid quantum k-Means algorithms can be more efficient than the classical version, still obtaining comparable clustering results.
Process Comparison Using Object-Centric Process Cubes
Mar 12, 2021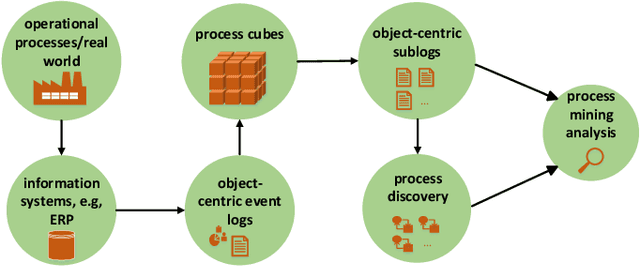
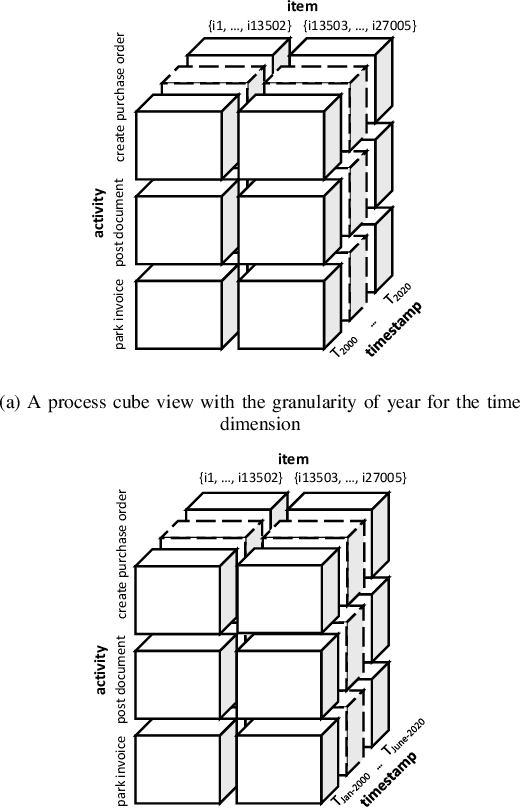
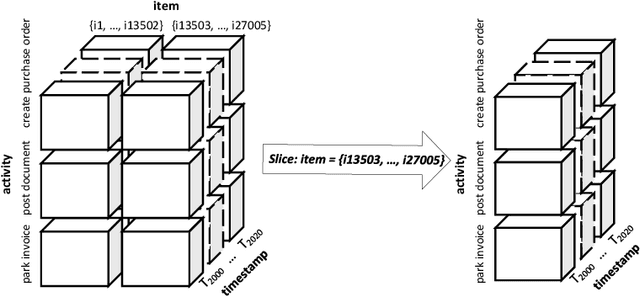
Process mining provides ways to analyze business processes. Common process mining techniques consider the process as a whole. However, in real-life business processes, different behaviors exist that make the overall process too complex to interpret. Process comparison is a branch of process mining that isolates different behaviors of the process from each other by using process cubes. Process cubes organize event data using different dimensions. Each cell contains a set of events that can be used as an input to apply process mining techniques. Existing work on process cubes assume single case notions. However, in real processes, several case notions (e.g., order, item, package, etc.) are intertwined. Object-centric process mining is a new branch of process mining addressing multiple case notions in a process. To make a bridge between object-centric process mining and process comparison, we propose a process cube framework, which supports process cube operations such as slice and dice on object-centric event logs. To facilitate the comparison, the framework is integrated with several object-centric process discovery approaches.
Discovering Object-Centric Petri Nets
Oct 05, 2020

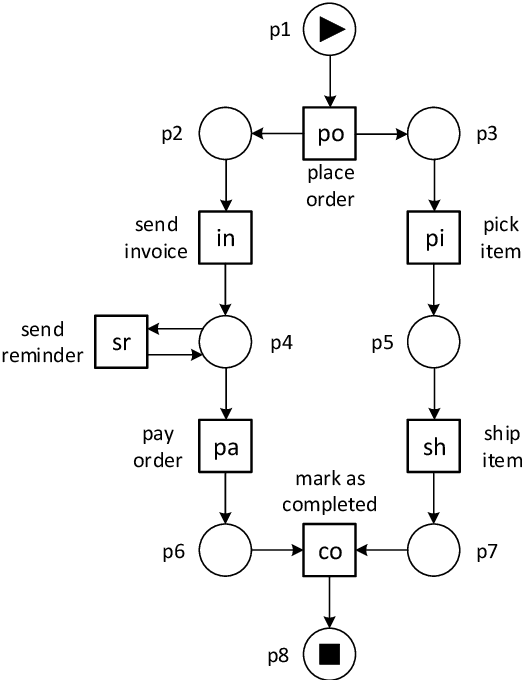

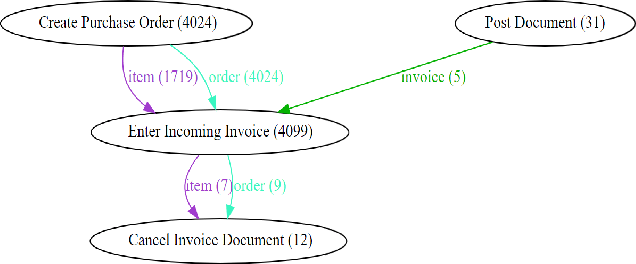
Techniques to discover Petri nets from event data assume precisely one case identifier per event. These case identifiers are used to correlate events, and the resulting discovered Petri net aims to describe the life-cycle of individual cases. In reality, there is not one possible case notion, but multiple intertwined case notions. For example, events may refer to mixtures of orders, items, packages, customers, and products. A package may refer to multiple items, multiple products, one order, and one customer. Therefore, we need to assume that each event refers to a collection of objects, each having a type (instead of a single case identifier). Such object-centric event logs are closer to data in real-life information systems. From an object-centric event log, we want to discover an object-centric Petri net with places that correspond to object types and transitions that may consume and produce collections of objects of different types. Object-centric Petri nets visualize the complex relationships among objects from different types. This paper discusses a novel process discovery approach implemented in PM4Py. As will be demonstrated, it is indeed feasible to discover holistic process models that can be used to drill-down into specific viewpoints if needed.