 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMAx: An Agentic Framework for AI-Driven Process Mining
Mar 16, 2026Process mining provides powerful insights into organizational workflows, but extracting these insights typically requires expertise in specialized query languages and data science tools. Large Language Models (LLMs) offer the potential to democratize process mining by enabling business users to interact with process data through natural language. However, using LLMs as direct analytical engines over raw event logs introduces fundamental challenges: LLMs struggle with deterministic reasoning and may hallucinate metrics, while sending large, sensitive logs to external AI services raises serious data-privacy concerns. To address these limitations, we present PMAx, an autonomous agentic framework that functions as a virtual process analyst. Rather than relying on LLMs to generate process models or compute analytical results, PMAx employs a privacy-preserving multi-agent architecture. An Engineer agent analyzes event-log metadata and autonomously generates local scripts to run established process mining algorithms, compute exact metrics, and produce artifacts such as process models, summary tables, and visualizations. An Analyst agent then interprets these insights and artifacts to compile comprehensive reports. By separating computation from interpretation and executing analysis locally, PMAx ensures mathematical accuracy and data privacy while enabling non-technical users to transform high-level business questions into reliable process insights.
Integrating Domain Knowledge into Process Discovery Using Large Language Models
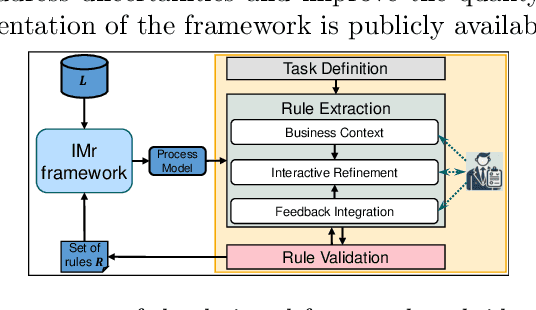
Oct 08, 2025Process discovery aims to derive process models from event logs, providing insights into operational behavior and forming a foundation for conformance checking and process improvement. However, models derived solely from event data may not accurately reflect the real process, as event logs are often incomplete or affected by noise, and domain knowledge, an important complementary resource, is typically disregarded. As a result, the discovered models may lack reliability for downstream tasks. We propose an interactive framework that incorporates domain knowledge, expressed in natural language, into the process discovery pipeline using Large Language Models (LLMs). Our approach leverages LLMs to extract declarative rules from textual descriptions provided by domain experts. These rules are used to guide the IMr discovery algorithm, which recursively constructs process models by combining insights from both the event log and the extracted rules, helping to avoid problematic process structures that contradict domain knowledge. The framework coordinates interactions among the LLM, domain experts, and a set of backend services. We present a fully implemented tool that supports this workflow and conduct an extensive evaluation of multiple LLMs and prompt engineering strategies. Our empirical study includes a case study based on a real-life event log with the involvement of domain experts, who assessed the usability and effectiveness of the framework.
Knowledge-Driven Hallucination in Large Language Models: An Empirical Study on Process Modeling
Sep 18, 2025The utility of Large Language Models (LLMs) in analytical tasks is rooted in their vast pre-trained knowledge, which allows them to interpret ambiguous inputs and infer missing information. However, this same capability introduces a critical risk of what we term knowledge-driven hallucination: a phenomenon where the model's output contradicts explicit source evidence because it is overridden by the model's generalized internal knowledge. This paper investigates this phenomenon by evaluating LLMs on the task of automated process modeling, where the goal is to generate a formal business process model from a given source artifact. The domain of Business Process Management (BPM) provides an ideal context for this study, as many core business processes follow standardized patterns, making it likely that LLMs possess strong pre-trained schemas for them. We conduct a controlled experiment designed to create scenarios with deliberate conflict between provided evidence and the LLM's background knowledge. We use inputs describing both standard and deliberately atypical process structures to measure the LLM's fidelity to the provided evidence. Our work provides a methodology for assessing this critical reliability issue and raises awareness of the need for rigorous validation of AI-generated artifacts in any evidence-based domain.
Unlocking Non-Block-Structured Decisions: Inductive Mining with Choice Graphs
May 11, 2025Process discovery aims to automatically derive process models from event logs, enabling organizations to analyze and improve their operational processes. Inductive mining algorithms, while prioritizing soundness and efficiency through hierarchical modeling languages, often impose a strict block-structured representation. This limits their ability to accurately capture the complexities of real-world processes. While recent advancements like the Partially Ordered Workflow Language (POWL) have addressed the block-structure limitation for concurrency, a significant gap remains in effectively modeling non-block-structured decision points. In this paper, we bridge this gap by proposing an extension of POWL to handle non-block-structured decisions through the introduction of choice graphs. Choice graphs offer a structured yet flexible approach to model complex decision logic within the hierarchical framework of POWL. We present an inductive mining discovery algorithm that uses our extension and preserves the quality guarantees of the inductive mining framework. Our experimental evaluation demonstrates that the discovered models, enriched with choice graphs, more precisely represent the complex decision-making behavior found in real-world processes, without compromising the high scalability inherent in inductive mining techniques.
Bridging Domain Knowledge and Process Discovery Using Large Language Models
Aug 30, 2024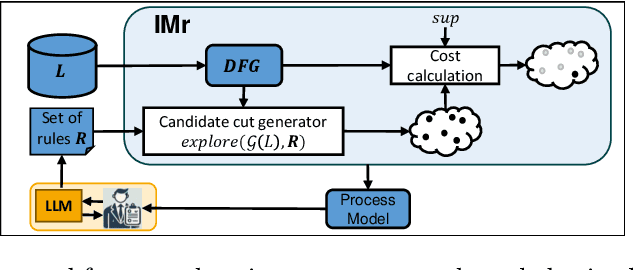


Discovering good process models is essential for different process analysis tasks such as conformance checking and process improvements. Automated process discovery methods often overlook valuable domain knowledge. This knowledge, including insights from domain experts and detailed process documentation, remains largely untapped during process discovery. This paper leverages Large Language Models (LLMs) to integrate such knowledge directly into process discovery. We use rules derived from LLMs to guide model construction, ensuring alignment with both domain knowledge and actual process executions. By integrating LLMs, we create a bridge between process knowledge expressed in natural language and the discovery of robust process models, advancing process discovery methodologies significantly. To showcase the usability of our framework, we conducted a case study with the UWV employee insurance agency, demonstrating its practical benefits and effectiveness.
PM-LLM-Benchmark: Evaluating Large Language Models on Process Mining Tasks
Jul 18, 2024



Large Language Models (LLMs) have the potential to semi-automate some process mining (PM) analyses. While commercial models are already adequate for many analytics tasks, the competitive level of open-source LLMs in PM tasks is unknown. In this paper, we propose PM-LLM-Benchmark, the first comprehensive benchmark for PM focusing on domain knowledge (process-mining-specific and process-specific) and on different implementation strategies. We focus also on the challenges in creating such a benchmark, related to the public availability of the data and on evaluation biases by the LLMs. Overall, we observe that most of the considered LLMs can perform some process mining tasks at a satisfactory level, but tiny models that would run on edge devices are still inadequate. We also conclude that while the proposed benchmark is useful for identifying LLMs that are adequate for process mining tasks, further research is needed to overcome the evaluation biases and perform a more thorough ranking of the competitive LLMs.
ProMoAI: Process Modeling with Generative AI
Mar 07, 2024ProMoAI is a novel tool that leverages Large Language Models (LLMs) to automatically generate process models from textual descriptions, incorporating advanced prompt engineering, error handling, and code generation techniques. Beyond automating the generation of complex process models, ProMoAI also supports process model optimization. Users can interact with the tool by providing feedback on the generated model, which is then used for refining the process model. ProMoAI utilizes the capabilities LLMs to offer a novel, AI-driven approach to process modeling, significantly reducing the barrier to entry for users without deep technical knowledge in process modeling.