 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Clustering with k-Means: a Hybrid Approach
Dec 15, 2022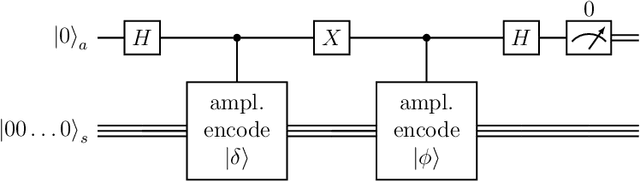
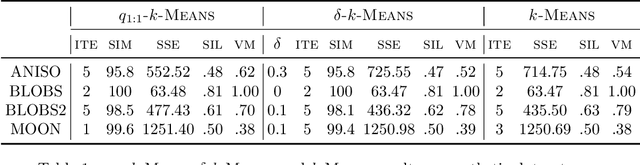
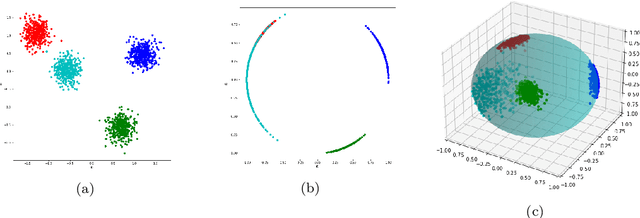
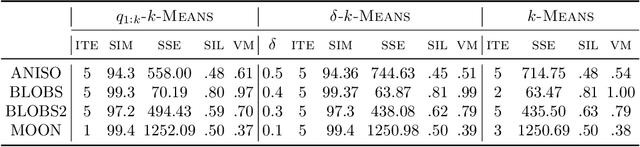
Quantum computing is a promising paradigm based on quantum theory for performing fast computations. Quantum algorithms are expected to surpass their classical counterparts in terms of computational complexity for certain tasks, including machine learning. In this paper, we design, implement, and evaluate three hybrid quantum k-Means algorithms, exploiting different degree of parallelism. Indeed, each algorithm incrementally leverages quantum parallelism to reduce the complexity of the cluster assignment step up to a constant cost. In particular, we exploit quantum phenomena to speed up the computation of distances. The core idea is that the computation of distances between records and centroids can be executed simultaneously, thus saving time, especially for big datasets. We show that our hybrid quantum k-Means algorithms can be more efficient than the classical version, still obtaining comparable clustering results.
Adaptive Nonnegative Matrix Factorization and Measure Comparisons for Recommender Systems
Aug 27, 2018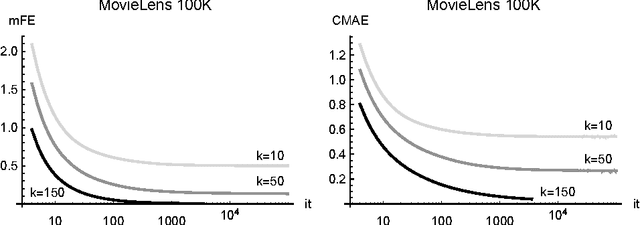
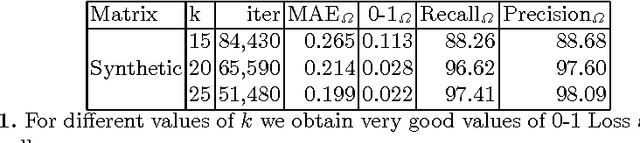
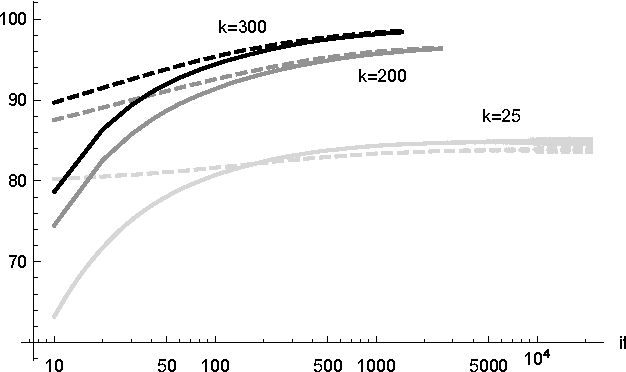

The Nonnegative Matrix Factorization (NMF) of the rating matrix has shown to be an effective method to tackle the recommendation problem. In this paper we propose new methods based on the NMF of the rating matrix and we compare them with some classical algorithms such as the SVD and the regularized and unregularized non-negative matrix factorization approach. In particular a new algorithm is obtained changing adaptively the function to be minimized at each step, realizing a sort of dynamic prior strategy. Another algorithm is obtained modifying the function to be minimized in the NMF formulation by enforcing the reconstruction of the unknown ratings toward a prior term. We then combine different methods obtaining two mixed strategies which turn out to be very effective in the reconstruction of missing observations. We perform a thoughtful comparison of different methods on the basis of several evaluation measures. We consider in particular rating, classification and ranking measures showing that the algorithm obtaining the best score for a given measure is in general the best also when different measures are considered, lowering the interest in designing specific evaluation measures. The algorithms have been tested on different datasets, in particular the 1M, and 10M MovieLens datasets containing ratings on movies, the Jester dataset with ranting on jokes and Amazon Fine Foods dataset with ratings on foods. The comparison of the different algorithms, shows the good performance of methods employing both an explicit and an implicit regularization scheme. Moreover we can get a boost by mixed strategies combining a fast method with a more accurate one.