 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailoring Machine Learning for Process Mining
Paper and Code
Jun 17, 2023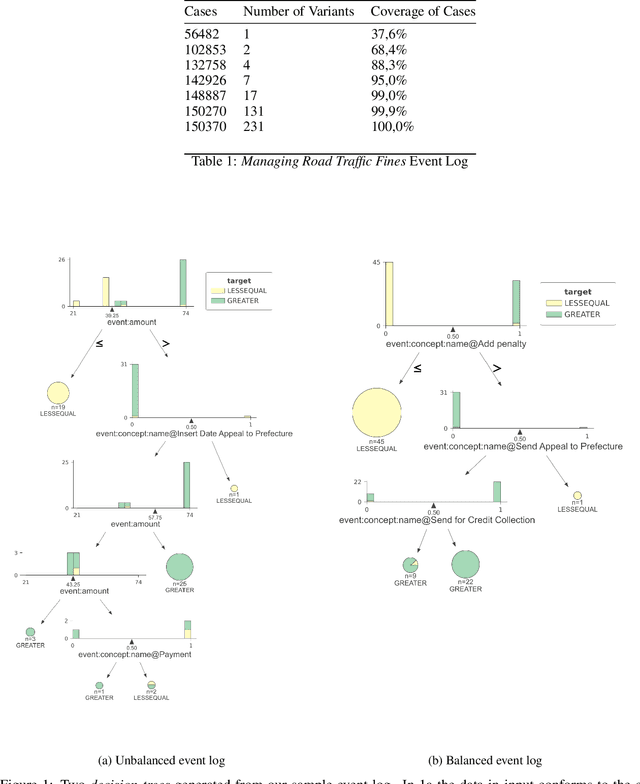
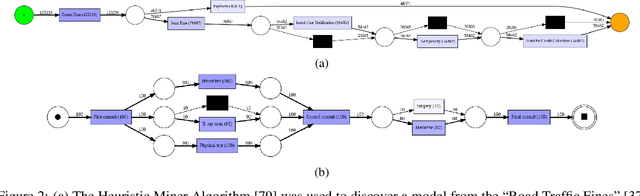
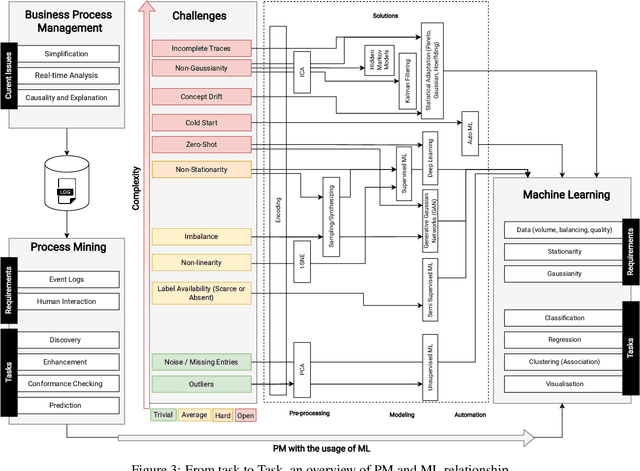
Machine learning models are routinely integrated into process mining pipelines to carry out tasks like data transformation, noise reduction, anomaly detection, classification, and prediction. Often, the design of such models is based on some ad-hoc assumptions about the corresponding data distributions, which are not necessarily in accordance with the non-parametric distributions typically observed with process data. Moreover, the learning procedure they follow ignores the constraints concurrency imposes to process data. Data encoding is a key element to smooth the mismatch between these assumptions but its potential is poorly exploited. In this paper, we argue that a deeper insight into the issues raised by training machine learning models with process data is crucial to ground a sound integration of process mining and machine learning. Our analysis of such issues is aimed at laying the foundation for a methodology aimed at correctly aligning machine learning with process mining requirements and stimulating the research to elaborate in this direction.