 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedSage: A Cybersecurity Generalist LLM
Jan 29, 2026Cybersecurity operations demand assistant LLMs that support diverse workflows without exposing sensitive data. Existing solutions either rely on proprietary APIs with privacy risks or on open models lacking domain adaptation. To bridge this gap, we curate 11.8B tokens of cybersecurity-focused continual pretraining data via large-scale web filtering and manual collection of high-quality resources, spanning 28.6K documents across frameworks, offensive techniques, and security tools. Building on this, we design an agentic augmentation pipeline that simulates expert workflows to generate 266K multi-turn cybersecurity samples for supervised fine-tuning. Combined with general open-source LLM data, these resources enable the training of RedSage, an open-source, locally deployable cybersecurity assistant with domain-aware pretraining and post-training. To rigorously evaluate the models, we introduce RedSage-Bench, a benchmark with 30K multiple-choice and 240 open-ended Q&A items covering cybersecurity knowledge, skills, and tool expertise. RedSage is further evaluated on established cybersecurity benchmarks (e.g., CTI-Bench, CyberMetric, SECURE) and general LLM benchmarks to assess broader generalization. At the 8B scale, RedSage achieves consistently better results, surpassing the baseline models by up to +5.59 points on cybersecurity benchmarks and +5.05 points on Open LLM Leaderboard tasks. These findings demonstrate that domain-aware agentic augmentation and pre/post-training can not only enhance cybersecurity-specific expertise but also help to improve general reasoning and instruction-following. All models, datasets, and code are publicly available.
HGCN(O): A Self-Tuning GCN HyperModel Toolkit for Outcome Prediction in Event-Sequence Data
Jul 30, 2025We propose HGCN(O), a self-tuning toolkit using Graph Convolutional Network (GCN) models for event sequence prediction. Featuring four GCN architectures (O-GCN, T-GCN, TP-GCN, TE-GCN) across the GCNConv and GraphConv layers, our toolkit integrates multiple graph representations of event sequences with different choices of node- and graph-level attributes and in temporal dependencies via edge weights, optimising prediction accuracy and stability for balanced and unbalanced datasets. Extensive experiments show that GCNConv models excel on unbalanced data, while all models perform consistently on balanced data. Experiments also confirm the superior performance of HGCN(O) over traditional approaches. Applications include Predictive Business Process Monitoring (PBPM), which predicts future events or states of a business process based on event logs.
Artificial Conversations, Real Results: Fostering Language Detection with Synthetic Data
Mar 31, 2025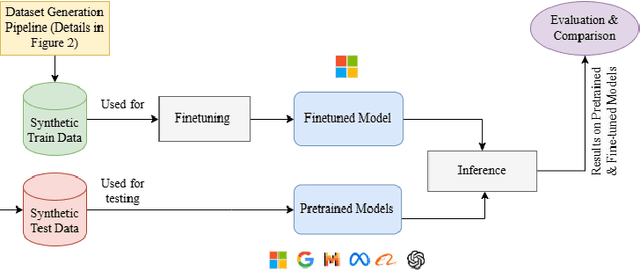

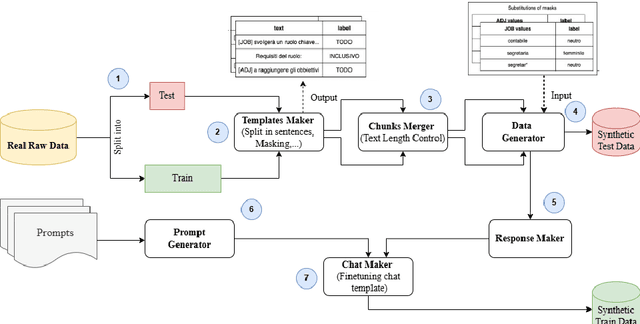

Collecting high-quality training data is essential for fine-tuning Large Language Models (LLMs). However, acquiring such data is often costly and time-consuming, especially for non-English languages such as Italian. Recently, researchers have begun to explore the use of LLMs to generate synthetic datasets as a viable alternative. This study proposes a pipeline for generating synthetic data and a comprehensive approach for investigating the factors that influence the validity of synthetic data generated by LLMs by examining how model performance is affected by metrics such as prompt strategy, text length and target position in a specific task, i.e. inclusive language detection in Italian job advertisements. Our results show that, in most cases and across different metrics, the fine-tuned models trained on synthetic data consistently outperformed other models on both real and synthetic test datasets. The study discusses the practical implications and limitations of using synthetic data for language detection tasks with LLMs.
Identifying Gender Stereotypes and Biases in Automated Translation from English to Italian using Similarity Networks
Feb 17, 2025


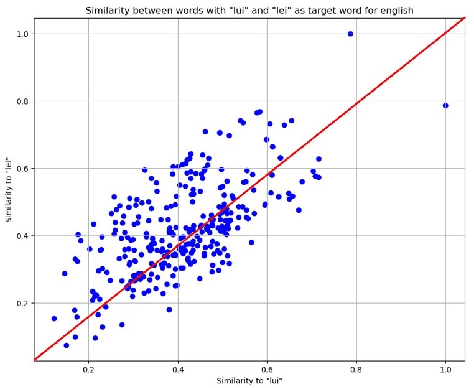
This paper is a collaborative effort between Linguistics, Law, and Computer Science to evaluate stereotypes and biases in automated translation systems. We advocate gender-neutral translation as a means to promote gender inclusion and improve the objectivity of machine translation. Our approach focuses on identifying gender bias in English-to-Italian translations. First, we define gender bias following human rights law and linguistics literature. Then we proceed by identifying gender-specific terms such as she/lei and he/lui as key elements. We then evaluate the cosine similarity between these target terms and others in the dataset to reveal the model's perception of semantic relations. Using numerical features, we effectively evaluate the intensity and direction of the bias. Our findings provide tangible insights for developing and training gender-neutral translation algorithms.
Leveraging GPT-4o Efficiency for Detecting Rework Anomaly in Business Processes
Feb 10, 2025This paper investigates the effectiveness of GPT-4o-2024-08-06, one of the Large Language Models (LLM) from OpenAI, in detecting business process anomalies, with a focus on rework anomalies. In our study, we developed a GPT-4o-based tool capable of transforming event logs into a structured format and identifying reworked activities within business event logs. The analysis was performed on a synthetic dataset designed to contain rework anomalies but free of loops. To evaluate the anomaly detection capabilities of GPT 4o-2024-08-06, we used three prompting techniques: zero-shot, one-shot, and few-shot. These techniques were tested on different anomaly distributions, namely normal, uniform, and exponential, to identify the most effective approach for each case. The results demonstrate the strong performance of GPT-4o-2024-08-06. On our dataset, the model achieved 96.14% accuracy with one-shot prompting for the normal distribution, 97.94% accuracy with few-shot prompting for the uniform distribution, and 74.21% accuracy with few-shot prompting for the exponential distribution. These results highlight the model's potential as a reliable tool for detecting rework anomalies in event logs and how anomaly distribution and prompting strategy influence the model's performance.
Enhancing Model Fairness and Accuracy with Similarity Networks: A Methodological Approach
Nov 08, 2024In this paper, we propose an innovative approach to thoroughly explore dataset features that introduce bias in downstream machine-learning tasks. Depending on the data format, we use different techniques to map instances into a similarity feature space. Our method's ability to adjust the resolution of pairwise similarity provides clear insights into the relationship between the dataset classification complexity and model fairness. Experimental results confirm the promising applicability of the similarity network in promoting fair models. Moreover, leveraging our methodology not only seems promising in providing a fair downstream task such as classification, it also performs well in imputation and augmentation of the dataset satisfying the fairness criteria such as demographic parity and imbalanced classes.
Are Large Language Models the New Interface for Data Pipelines?
Jun 06, 2024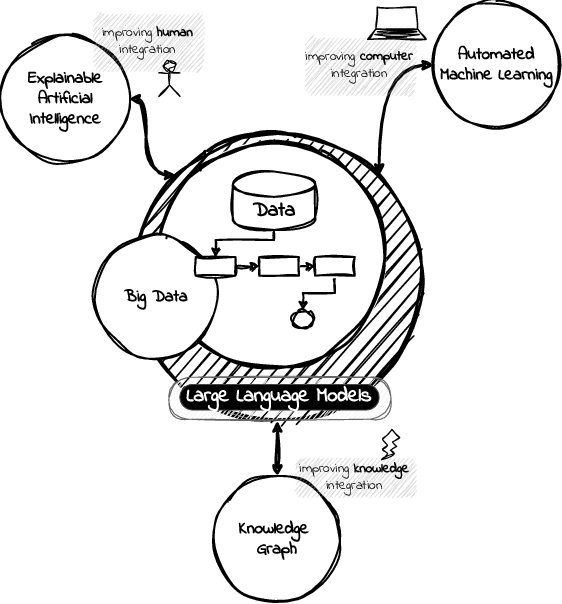
A Language Model is a term that encompasses various types of models designed to understand and generate human communication. Large Language Models (LLMs) have gained significant attention due to their ability to process text with human-like fluency and coherence, making them valuable for a wide range of data-related tasks fashioned as pipelines. The capabilities of LLMs in natural language understanding and generation, combined with their scalability, versatility, and state-of-the-art performance, enable innovative applications across various AI-related fields, including eXplainable Artificial Intelligence (XAI), Automated Machine Learning (AutoML), and Knowledge Graphs (KG). Furthermore, we believe these models can extract valuable insights and make data-driven decisions at scale, a practice commonly referred to as Big Data Analytics (BDA). In this position paper, we provide some discussions in the direction of unlocking synergies among these technologies, which can lead to more powerful and intelligent AI solutions, driving improvements in data pipelines across a wide range of applications and domains integrating humans, computers, and knowledge.
Tailoring Machine Learning for Process Mining
Jun 17, 2023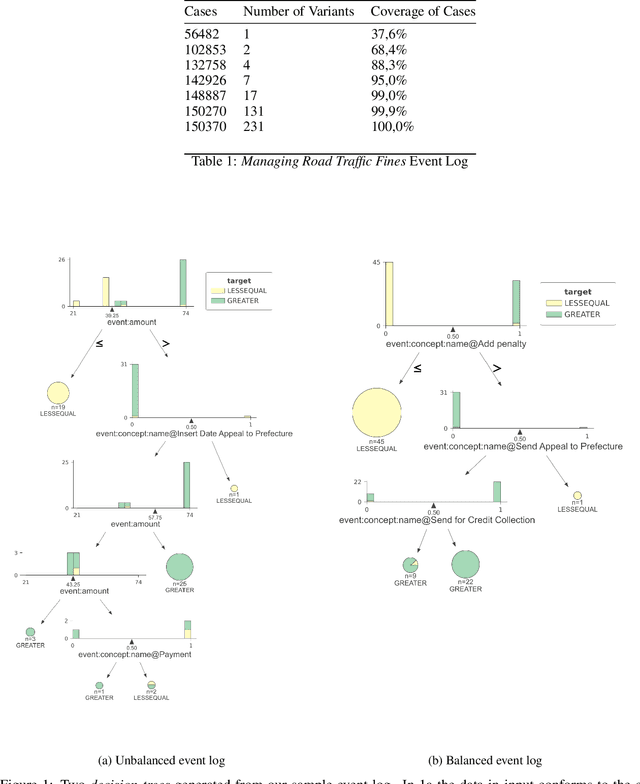
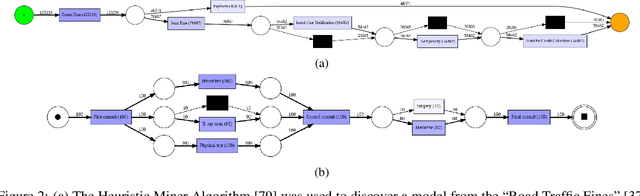
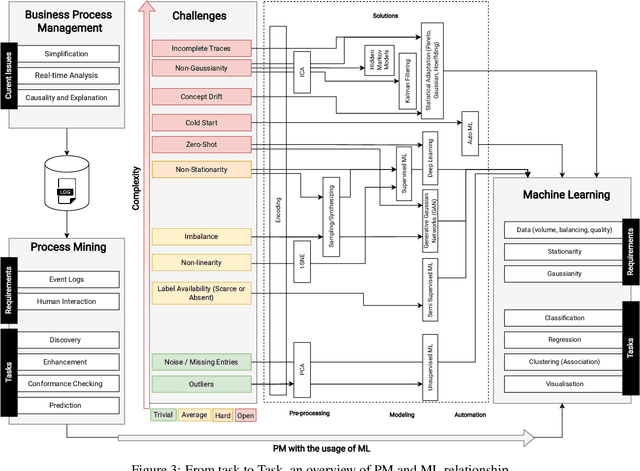
Machine learning models are routinely integrated into process mining pipelines to carry out tasks like data transformation, noise reduction, anomaly detection, classification, and prediction. Often, the design of such models is based on some ad-hoc assumptions about the corresponding data distributions, which are not necessarily in accordance with the non-parametric distributions typically observed with process data. Moreover, the learning procedure they follow ignores the constraints concurrency imposes to process data. Data encoding is a key element to smooth the mismatch between these assumptions but its potential is poorly exploited. In this paper, we argue that a deeper insight into the issues raised by training machine learning models with process data is crucial to ground a sound integration of process mining and machine learning. Our analysis of such issues is aimed at laying the foundation for a methodology aimed at correctly aligning machine learning with process mining requirements and stimulating the research to elaborate in this direction.
CoSMo: a Framework for Implementing Conditioned Process Simulation Models
Mar 31, 2023Process simulation is an analysis tool in process mining that allows users to measure the impact of changes, prevent losses, and update the process without risks or costs. In the literature, several process simulation techniques are available and they are usually built upon process models discovered from a given event log or learned via deep learning. Each group of approaches has its own strengths and limitations. The former is usually restricted to the control-flow but it is more interpretable, whereas the latter is not interpretable by nature but has a greater generalization capability on large event logs. Despite the great performance achieved by deep learning approaches, they are still not suitable to be applied to real scenarios and generate value for users. This issue is mainly due to fact their stochasticity is hard to control. To address this problem, we propose the CoSMo framework for implementing process simulation models fully based on deep learning. This framework enables simulating event logs that satisfy a constraint by conditioning the learning phase of a deep neural network. Throughout experiments, the simulation is validated from both control-flow and data-flow perspectives, demonstrating the proposed framework's capability of simulating cases while satisfying imposed conditions.
Trace Encoding in Process Mining: a survey and benchmarking
Jan 05, 2023Encoding methods are employed across several process mining tasks, including predictive process monitoring, anomalous case detection, trace clustering, etc. These methods are usually performed as preprocessing steps and are responsible for transforming complex information into a numerical feature space. Most papers choose existing encoding methods arbitrarily or employ a strategy based on a specific expert knowledge domain. Moreover, existing methods are employed by using their default hyperparameters without evaluating other options. This practice can lead to several drawbacks, such as suboptimal performance and unfair comparisons with the state-of-the-art. Therefore, this work aims at providing a comprehensive survey on event log encoding by comparing 27 methods, from different natures, in terms of expressivity, scalability, correlation, and domain agnosticism. To the best of our knowledge, this is the most comprehensive study so far focusing on trace encoding in process mining. It contributes to maturing awareness about the role of trace encoding in process mining pipelines and sheds light on issues, concerns, and future research directions regarding the use of encoding methods to bridge the gap between machine learning models and process mining.