 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Gender Stereotypes and Biases in Automated Translation from English to Italian using Similarity Networks
Feb 17, 2025


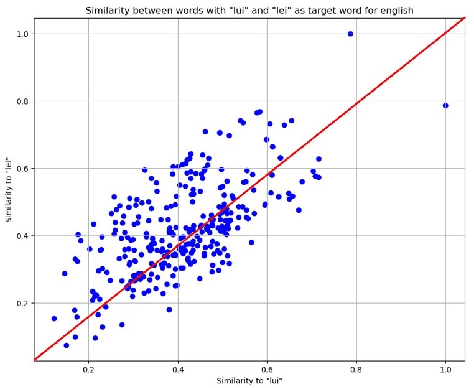
This paper is a collaborative effort between Linguistics, Law, and Computer Science to evaluate stereotypes and biases in automated translation systems. We advocate gender-neutral translation as a means to promote gender inclusion and improve the objectivity of machine translation. Our approach focuses on identifying gender bias in English-to-Italian translations. First, we define gender bias following human rights law and linguistics literature. Then we proceed by identifying gender-specific terms such as she/lei and he/lui as key elements. We then evaluate the cosine similarity between these target terms and others in the dataset to reveal the model's perception of semantic relations. Using numerical features, we effectively evaluate the intensity and direction of the bias. Our findings provide tangible insights for developing and training gender-neutral translation algorithms.