 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Conversations, Real Results: Fostering Language Detection with Synthetic Data
Mar 31, 2025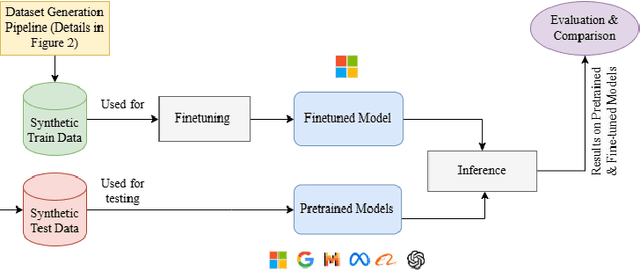

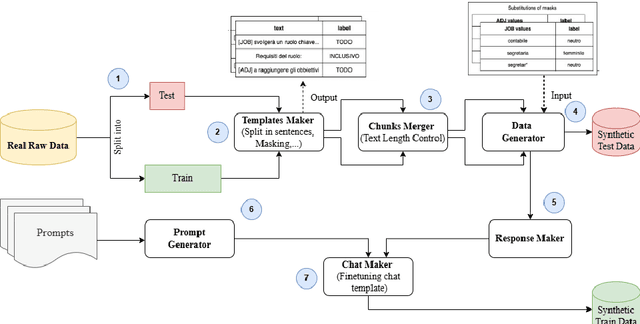

Collecting high-quality training data is essential for fine-tuning Large Language Models (LLMs). However, acquiring such data is often costly and time-consuming, especially for non-English languages such as Italian. Recently, researchers have begun to explore the use of LLMs to generate synthetic datasets as a viable alternative. This study proposes a pipeline for generating synthetic data and a comprehensive approach for investigating the factors that influence the validity of synthetic data generated by LLMs by examining how model performance is affected by metrics such as prompt strategy, text length and target position in a specific task, i.e. inclusive language detection in Italian job advertisements. Our results show that, in most cases and across different metrics, the fine-tuned models trained on synthetic data consistently outperformed other models on both real and synthetic test datasets. The study discusses the practical implications and limitations of using synthetic data for language detection tasks with LLMs.
Identifying Gender Stereotypes and Biases in Automated Translation from English to Italian using Similarity Networks
Feb 17, 2025


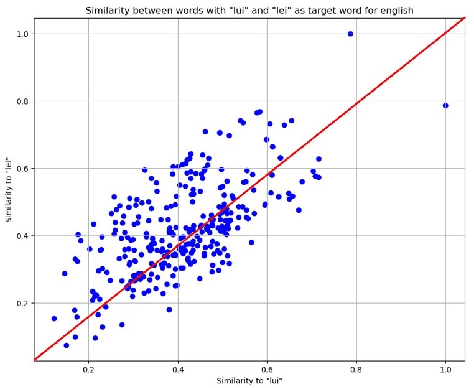
This paper is a collaborative effort between Linguistics, Law, and Computer Science to evaluate stereotypes and biases in automated translation systems. We advocate gender-neutral translation as a means to promote gender inclusion and improve the objectivity of machine translation. Our approach focuses on identifying gender bias in English-to-Italian translations. First, we define gender bias following human rights law and linguistics literature. Then we proceed by identifying gender-specific terms such as she/lei and he/lui as key elements. We then evaluate the cosine similarity between these target terms and others in the dataset to reveal the model's perception of semantic relations. Using numerical features, we effectively evaluate the intensity and direction of the bias. Our findings provide tangible insights for developing and training gender-neutral translation algorithms.
Leveraging GPT-4o Efficiency for Detecting Rework Anomaly in Business Processes
Feb 10, 2025This paper investigates the effectiveness of GPT-4o-2024-08-06, one of the Large Language Models (LLM) from OpenAI, in detecting business process anomalies, with a focus on rework anomalies. In our study, we developed a GPT-4o-based tool capable of transforming event logs into a structured format and identifying reworked activities within business event logs. The analysis was performed on a synthetic dataset designed to contain rework anomalies but free of loops. To evaluate the anomaly detection capabilities of GPT 4o-2024-08-06, we used three prompting techniques: zero-shot, one-shot, and few-shot. These techniques were tested on different anomaly distributions, namely normal, uniform, and exponential, to identify the most effective approach for each case. The results demonstrate the strong performance of GPT-4o-2024-08-06. On our dataset, the model achieved 96.14% accuracy with one-shot prompting for the normal distribution, 97.94% accuracy with few-shot prompting for the uniform distribution, and 74.21% accuracy with few-shot prompting for the exponential distribution. These results highlight the model's potential as a reliable tool for detecting rework anomalies in event logs and how anomaly distribution and prompting strategy influence the model's performance.