 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Conversations, Real Results: Fostering Language Detection with Synthetic Data
Mar 31, 2025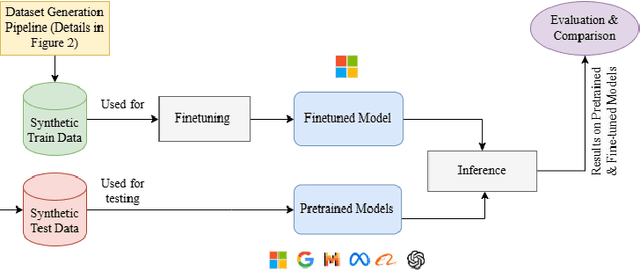

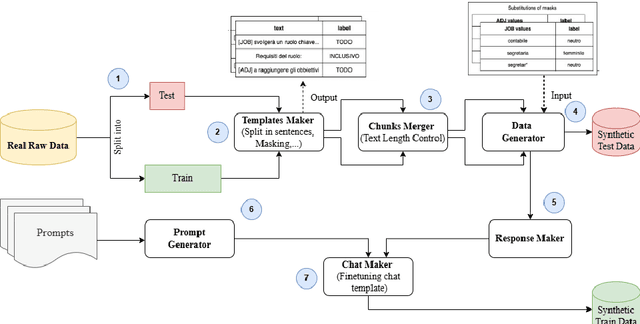

Collecting high-quality training data is essential for fine-tuning Large Language Models (LLMs). However, acquiring such data is often costly and time-consuming, especially for non-English languages such as Italian. Recently, researchers have begun to explore the use of LLMs to generate synthetic datasets as a viable alternative. This study proposes a pipeline for generating synthetic data and a comprehensive approach for investigating the factors that influence the validity of synthetic data generated by LLMs by examining how model performance is affected by metrics such as prompt strategy, text length and target position in a specific task, i.e. inclusive language detection in Italian job advertisements. Our results show that, in most cases and across different metrics, the fine-tuned models trained on synthetic data consistently outperformed other models on both real and synthetic test datasets. The study discusses the practical implications and limitations of using synthetic data for language detection tasks with LLMs.
Identifying Gender Stereotypes and Biases in Automated Translation from English to Italian using Similarity Networks
Feb 17, 2025


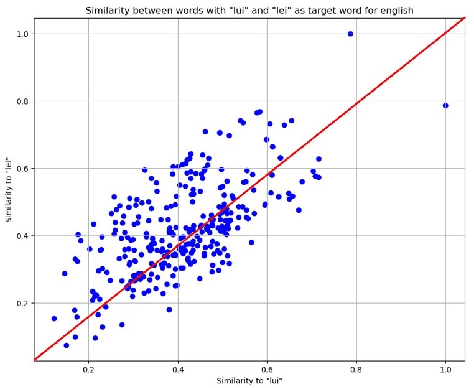
This paper is a collaborative effort between Linguistics, Law, and Computer Science to evaluate stereotypes and biases in automated translation systems. We advocate gender-neutral translation as a means to promote gender inclusion and improve the objectivity of machine translation. Our approach focuses on identifying gender bias in English-to-Italian translations. First, we define gender bias following human rights law and linguistics literature. Then we proceed by identifying gender-specific terms such as she/lei and he/lui as key elements. We then evaluate the cosine similarity between these target terms and others in the dataset to reveal the model's perception of semantic relations. Using numerical features, we effectively evaluate the intensity and direction of the bias. Our findings provide tangible insights for developing and training gender-neutral translation algorithms.
Enhancing Model Fairness and Accuracy with Similarity Networks: A Methodological Approach
Nov 08, 2024In this paper, we propose an innovative approach to thoroughly explore dataset features that introduce bias in downstream machine-learning tasks. Depending on the data format, we use different techniques to map instances into a similarity feature space. Our method's ability to adjust the resolution of pairwise similarity provides clear insights into the relationship between the dataset classification complexity and model fairness. Experimental results confirm the promising applicability of the similarity network in promoting fair models. Moreover, leveraging our methodology not only seems promising in providing a fair downstream task such as classification, it also performs well in imputation and augmentation of the dataset satisfying the fairness criteria such as demographic parity and imbalanced classes.
Are Large Language Models the New Interface for Data Pipelines?
Jun 06, 2024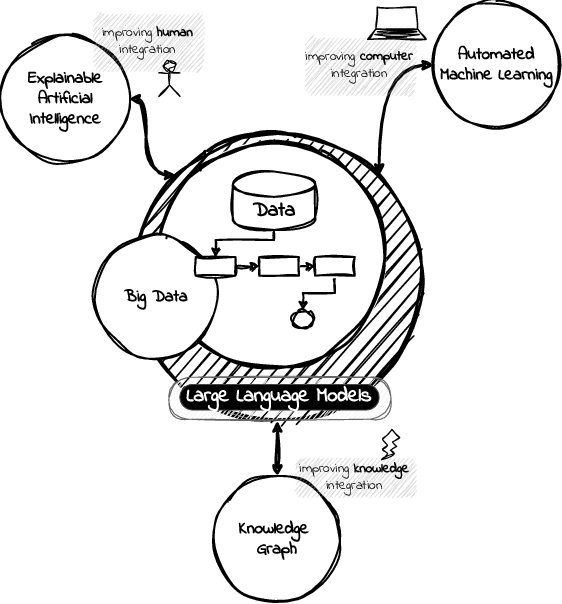
A Language Model is a term that encompasses various types of models designed to understand and generate human communication. Large Language Models (LLMs) have gained significant attention due to their ability to process text with human-like fluency and coherence, making them valuable for a wide range of data-related tasks fashioned as pipelines. The capabilities of LLMs in natural language understanding and generation, combined with their scalability, versatility, and state-of-the-art performance, enable innovative applications across various AI-related fields, including eXplainable Artificial Intelligence (XAI), Automated Machine Learning (AutoML), and Knowledge Graphs (KG). Furthermore, we believe these models can extract valuable insights and make data-driven decisions at scale, a practice commonly referred to as Big Data Analytics (BDA). In this position paper, we provide some discussions in the direction of unlocking synergies among these technologies, which can lead to more powerful and intelligent AI solutions, driving improvements in data pipelines across a wide range of applications and domains integrating humans, computers, and knowledge.