 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelecting Optimal Trace Clustering Pipelines with AutoML
Paper and Code
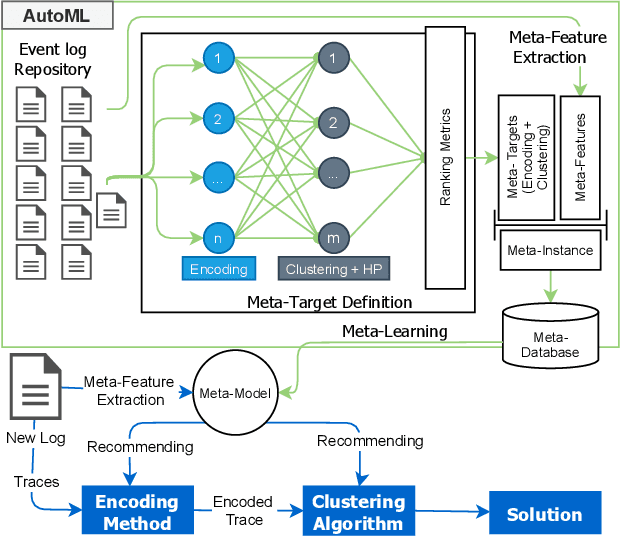


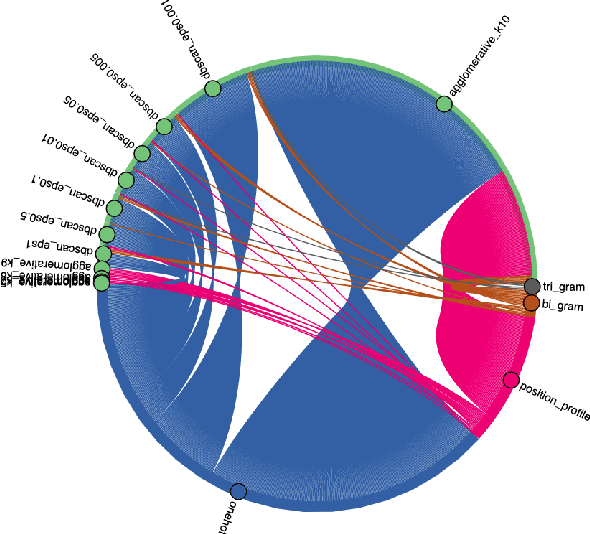
Trace clustering has been extensively used to preprocess event logs. By grouping similar behavior, these techniques guide the identification of sub-logs, producing more understandable models and conformance analytics. Nevertheless, little attention has been posed to the relationship between event log properties and clustering quality. In this work, we propose an Automatic Machine Learning (AutoML) framework to recommend the most suitable pipeline for trace clustering given an event log, which encompasses the encoding method, clustering algorithm, and its hyperparameters. Our experiments were conducted using a thousand event logs, four encoding techniques, and three clustering methods. Results indicate that our framework sheds light on the trace clustering problem and can assist users in choosing the best pipeline considering their scenario.