 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelecting Optimal Trace Clustering Pipelines with AutoML
Sep 01, 2021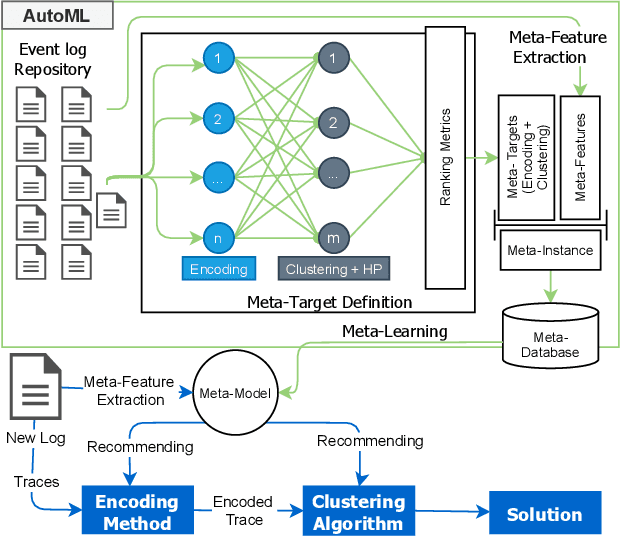


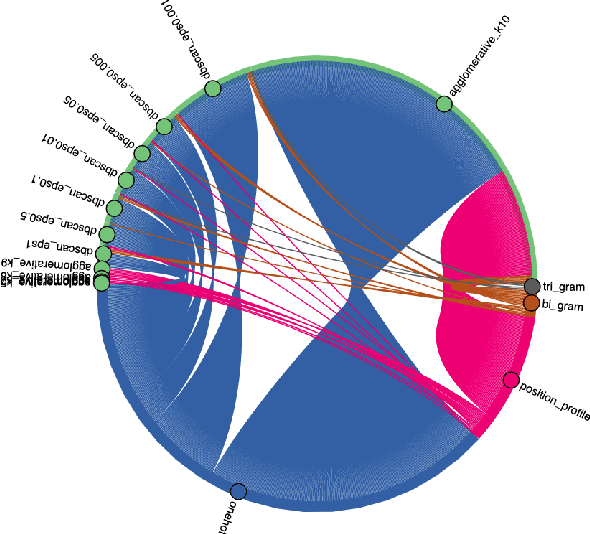
Trace clustering has been extensively used to preprocess event logs. By grouping similar behavior, these techniques guide the identification of sub-logs, producing more understandable models and conformance analytics. Nevertheless, little attention has been posed to the relationship between event log properties and clustering quality. In this work, we propose an Automatic Machine Learning (AutoML) framework to recommend the most suitable pipeline for trace clustering given an event log, which encompasses the encoding method, clustering algorithm, and its hyperparameters. Our experiments were conducted using a thousand event logs, four encoding techniques, and three clustering methods. Results indicate that our framework sheds light on the trace clustering problem and can assist users in choosing the best pipeline considering their scenario.
Using Meta-learning to Recommend Process Discovery Methods
Mar 23, 2021
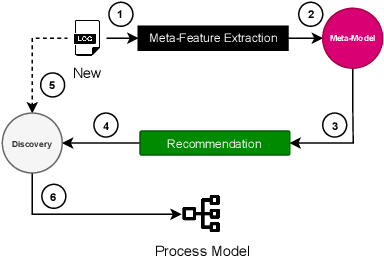

Process discovery methods have obtained remarkable achievements in Process Mining, delivering comprehensible process models to enhance management capabilities. However, selecting the suitable method for a specific event log highly relies on human expertise, hindering its broad application. Solutions based on Meta-learning (MtL) have been promising for creating systems with reduced human assistance. This paper presents a MtL solution for recommending process discovery methods that maximize model quality according to complementary dimensions. Thanks to our MtL pipeline, it was possible to recommend a discovery method with 92% of accuracy using light-weight features that describe the event log. Our experimental analysis also provided significant insights on the importance of log features in generating recommendations, paving the way to a deeper understanding of the discovery algorithms.
Improved prediction of soil properties with Multi-target Stacked Generalisation on EDXRF spectra
Feb 11, 2020Machine Learning (ML) algorithms have been used for assessing soil quality parameters along with non-destructive methodologies. Among spectroscopic analytical methodologies, energy dispersive X-ray fluorescence (EDXRF) is one of the more quick, environmentally friendly and less expensive when compared to conventional methods. However, some challenges in EDXRF spectral data analysis still demand more efficient methods capable of providing accurate outcomes. Using Multi-target Regression (MTR) methods, multiple parameters can be predicted, and also taking advantage of inter-correlated parameters the overall predictive performance can be improved. In this study, we proposed the Multi-target Stacked Generalisation (MTSG), a novel MTR method relying on learning from different regressors arranged in stacking structure for a boosted outcome. We compared MTSG and 5 MTR methods for predicting 10 parameters of soil fertility. Random Forest and Support Vector Machine (with linear and radial kernels) were used as learning algorithms embedded into each MTR method. Results showed the superiority of MTR methods over the Single-target Regression (the traditional ML method), reducing the predictive error for 5 parameters. Particularly, MTSG obtained the lowest error for phosphorus, total organic carbon and cation exchange capacity. When observing the relative performance of Support Vector Machine with a radial kernel, the prediction of base saturation percentage was improved in 19%. Finally, the proposed method was able to reduce the average error from 0.67 (single-target) to 0.64 analysing all targets, representing a global improvement of 4.48%.
Towards meta-learning for multi-target regression problems
Jul 25, 2019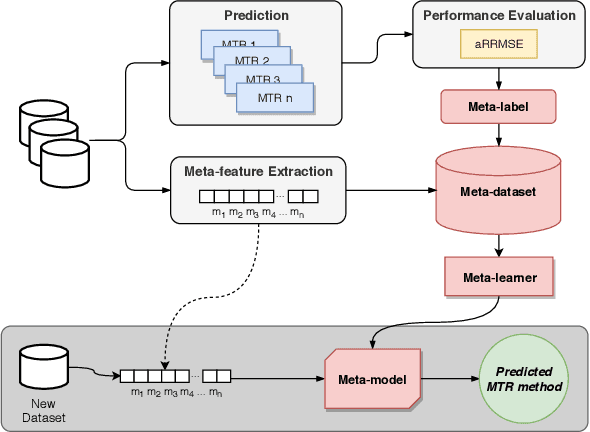
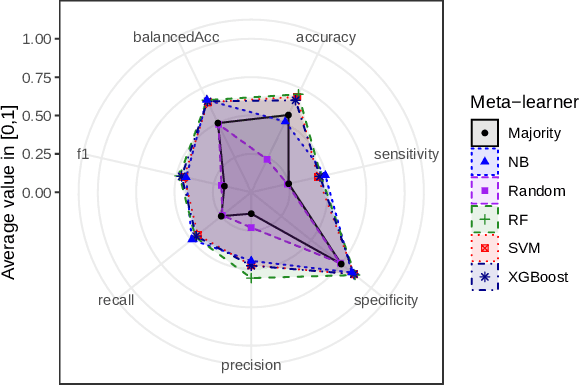
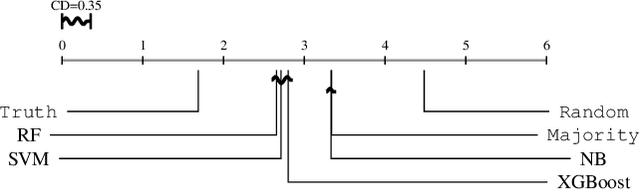
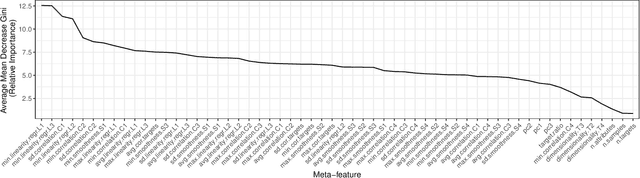
Several multi-target regression methods were devel-oped in the last years aiming at improving predictive performanceby exploring inter-target correlation within the problem. However, none of these methods outperforms the others for all problems. This motivates the development of automatic approachesto recommend the most suitable multi-target regression method. In this paper, we propose a meta-learning system to recommend the best predictive method for a given multi-target regression problem. We performed experiments with a meta-dataset generated by a total of 648 synthetic datasets. These datasets were created to explore distinct inter-targets characteristics toward recommending the most promising method. In experiments, we evaluated four different algorithms with different biases as meta-learners. Our meta-dataset is composed of 58 meta-features, based on: statistical information, correlation characteristics, linear landmarking, from the distribution and smoothness of the data, and has four different meta-labels. Results showed that induced meta-models were able to recommend the best methodfor different base level datasets with a balanced accuracy superior to 70% using a Random Forest meta-model, which statistically outperformed the meta-learning baselines.
Online Local Boosting: improving performance in online decision trees
Jul 16, 2019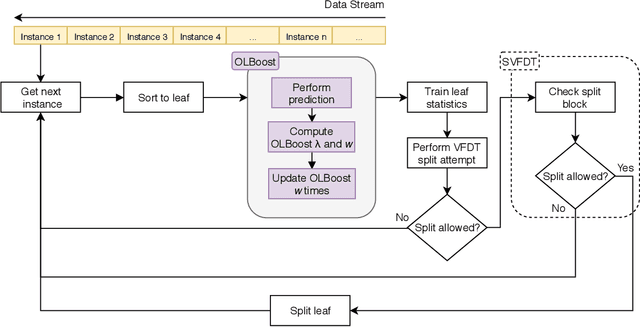
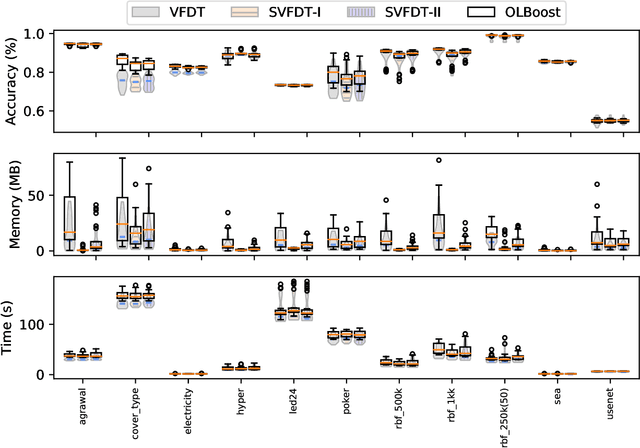
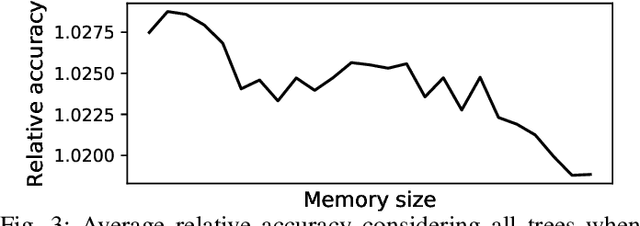
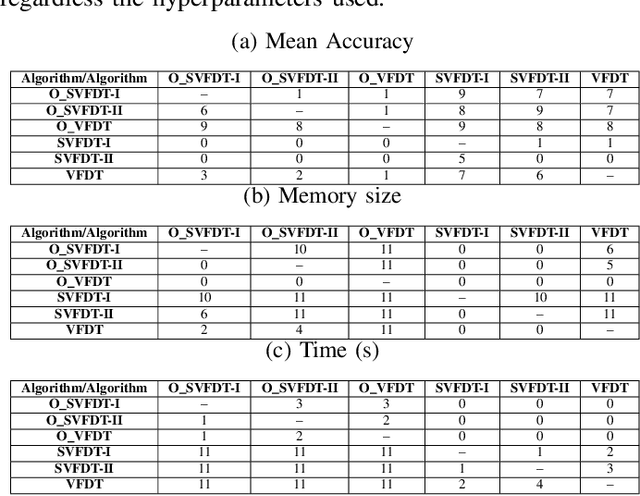
As more data are produced each day, and faster, data stream mining is growing in importance, making clear the need for algorithms able to fast process these data. Data stream mining algorithms are meant to be solutions to extract knowledge online, specially tailored from continuous data problem. Many of the current algorithms for data stream mining have high processing and memory costs. Often, the higher the predictive performance, the higher these costs. To increase predictive performance without largely increasing memory and time costs, this paper introduces a novel algorithm, named Online Local Boosting (OLBoost), which can be combined into online decision tree algorithms to improve their predictive performance without modifying the structure of the induced decision trees. For such, OLBoost applies a boosting to small separate regions of the instances space. Experimental results presented in this paper show that by using OLBoost the online learning decision tree algorithms can significantly improve their predictive performance. Additionally, it can make smaller trees perform as good or better than larger trees.