 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegazordNet: combining statistical and machine learning standpoints for time series forecasting
Jun 23, 2021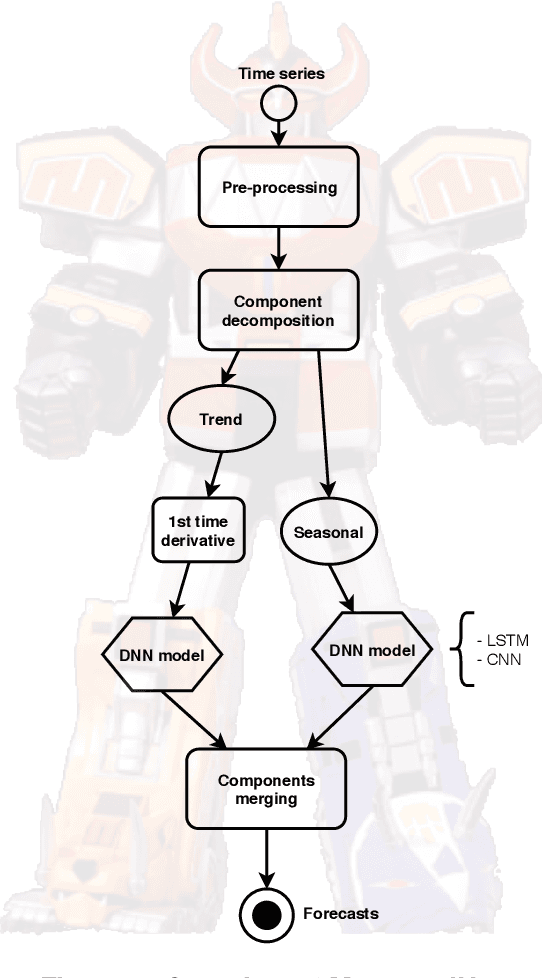

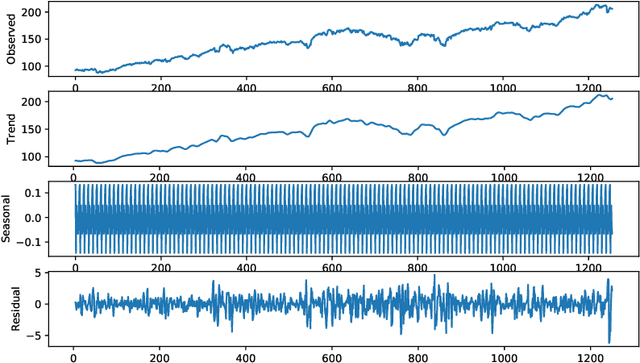

Forecasting financial time series is considered to be a difficult task due to the chaotic feature of the series. Statistical approaches have shown solid results in some specific problems such as predicting market direction and single-price of stocks; however, with the recent advances in deep learning and big data techniques, new promising options have arises to tackle financial time series forecasting. Moreover, recent literature has shown that employing a combination of statistics and machine learning may improve accuracy in the forecasts in comparison to single solutions. Taking into consideration the mentioned aspects, in this work, we proposed the MegazordNet, a framework that explores statistical features within a financial series combined with a structured deep learning model for time series forecasting. We evaluated our approach predicting the closing price of stocks in the S&P 500 using different metrics, and we were able to beat single statistical and machine learning methods.
River: machine learning for streaming data in Python
Dec 08, 2020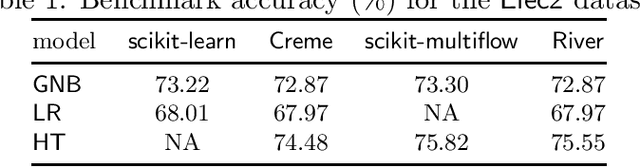

River is a machine learning library for dynamic data streams and continual learning. It provides multiple state-of-the-art learning methods, data generators/transformers, performance metrics and evaluators for different stream learning problems. It is the result from the merger of the two most popular packages for stream learning in Python: Creme and scikit-multiflow. River introduces a revamped architecture based on the lessons learnt from the seminal packages. River's ambition is to be the go-to library for doing machine learning on streaming data. Additionally, this open source package brings under the same umbrella a large community of practitioners and researchers. The source code is available at https://github.com/online-ml/river.
Using dynamical quantization to perform split attempts in online tree regressors
Dec 03, 2020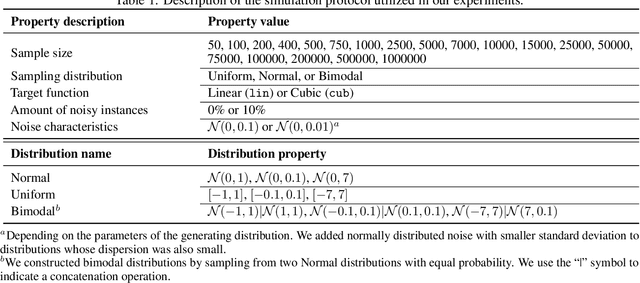
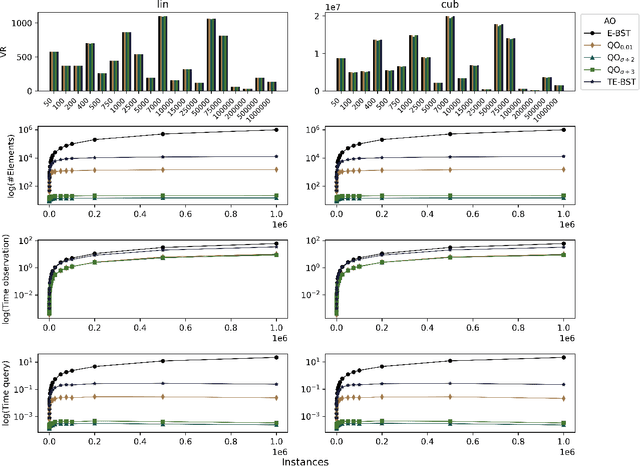

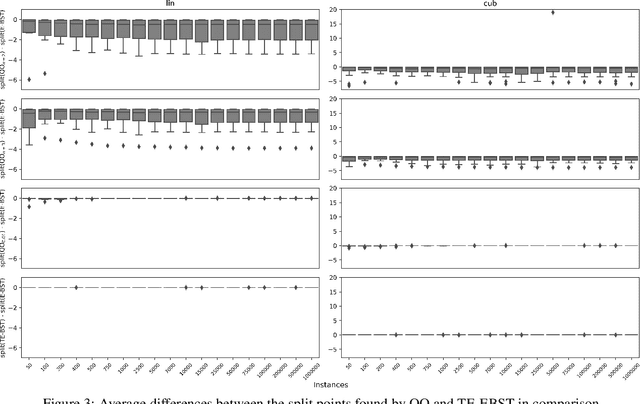
A central aspect of online decision tree solutions is evaluating the incoming data and enabling model growth. For such, trees much deal with different kinds of input features and partition them to learn from the data. Numerical features are no exception, and they pose additional challenges compared to other kinds of features, as there is no trivial strategy to choose the best point to make a split decision. The problem is even more challenging in regression tasks because both the features and the target are continuous. Typical online solutions evaluate and store all the points monitored between split attempts, which goes against the constraints posed in real-time applications. In this paper, we introduce the Quantization Observer (QO), a simple yet effective hashing-based algorithm to monitor and evaluate split point candidates in numerical features for online tree regressors. QO can be easily integrated into incremental decision trees, such as Hoeffding Trees, and it has a monitoring cost of $O(1)$ per instance and sub-linear cost to evaluate split candidates. Previous solutions had a $O(\log n)$ cost per insertion (in the best case) and a linear cost to evaluate split points. Our extensive experimental setup highlights QO's effectiveness in providing accurate split point suggestions while spending much less memory and processing time than its competitors.
Improved prediction of soil properties with Multi-target Stacked Generalisation on EDXRF spectra
Feb 11, 2020Machine Learning (ML) algorithms have been used for assessing soil quality parameters along with non-destructive methodologies. Among spectroscopic analytical methodologies, energy dispersive X-ray fluorescence (EDXRF) is one of the more quick, environmentally friendly and less expensive when compared to conventional methods. However, some challenges in EDXRF spectral data analysis still demand more efficient methods capable of providing accurate outcomes. Using Multi-target Regression (MTR) methods, multiple parameters can be predicted, and also taking advantage of inter-correlated parameters the overall predictive performance can be improved. In this study, we proposed the Multi-target Stacked Generalisation (MTSG), a novel MTR method relying on learning from different regressors arranged in stacking structure for a boosted outcome. We compared MTSG and 5 MTR methods for predicting 10 parameters of soil fertility. Random Forest and Support Vector Machine (with linear and radial kernels) were used as learning algorithms embedded into each MTR method. Results showed the superiority of MTR methods over the Single-target Regression (the traditional ML method), reducing the predictive error for 5 parameters. Particularly, MTSG obtained the lowest error for phosphorus, total organic carbon and cation exchange capacity. When observing the relative performance of Support Vector Machine with a radial kernel, the prediction of base saturation percentage was improved in 19%. Finally, the proposed method was able to reduce the average error from 0.67 (single-target) to 0.64 analysing all targets, representing a global improvement of 4.48%.
Towards meta-learning for multi-target regression problems
Jul 25, 2019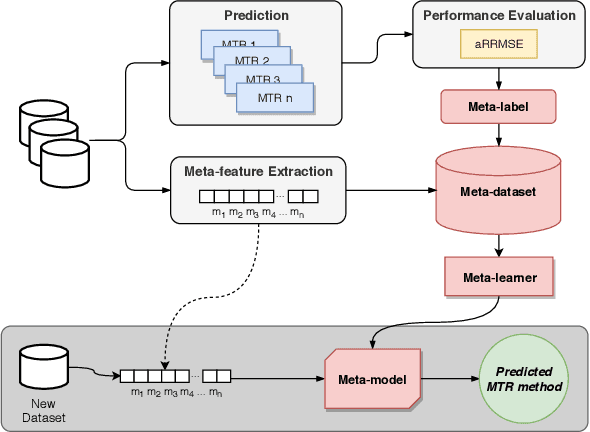
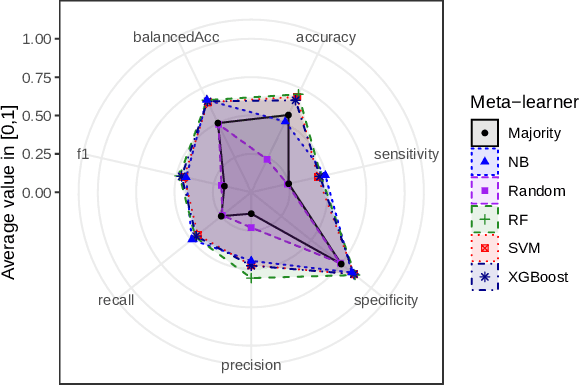
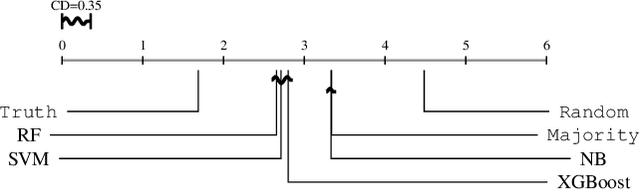
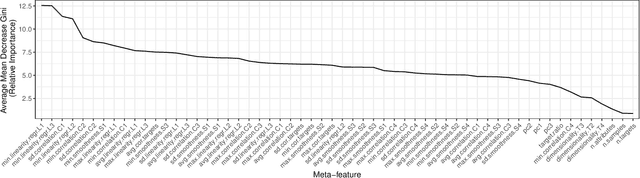
Several multi-target regression methods were devel-oped in the last years aiming at improving predictive performanceby exploring inter-target correlation within the problem. However, none of these methods outperforms the others for all problems. This motivates the development of automatic approachesto recommend the most suitable multi-target regression method. In this paper, we propose a meta-learning system to recommend the best predictive method for a given multi-target regression problem. We performed experiments with a meta-dataset generated by a total of 648 synthetic datasets. These datasets were created to explore distinct inter-targets characteristics toward recommending the most promising method. In experiments, we evaluated four different algorithms with different biases as meta-learners. Our meta-dataset is composed of 58 meta-features, based on: statistical information, correlation characteristics, linear landmarking, from the distribution and smoothness of the data, and has four different meta-labels. Results showed that induced meta-models were able to recommend the best methodfor different base level datasets with a balanced accuracy superior to 70% using a Random Forest meta-model, which statistically outperformed the meta-learning baselines.
Online Local Boosting: improving performance in online decision trees
Jul 16, 2019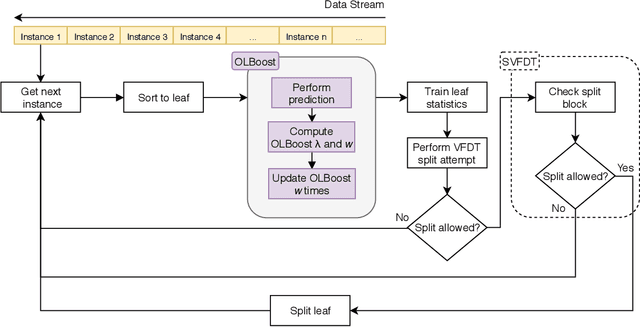
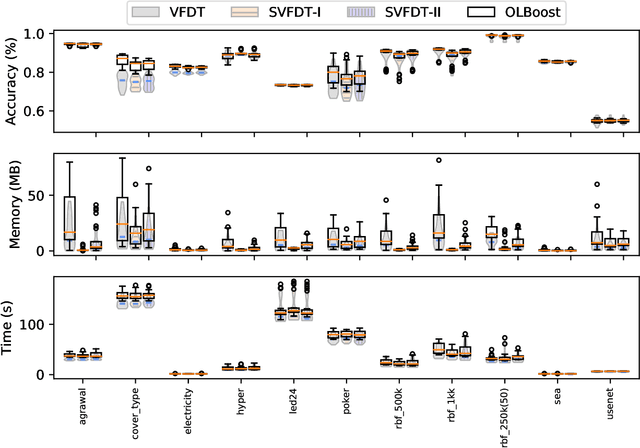
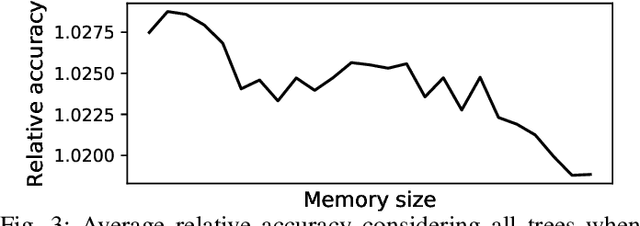
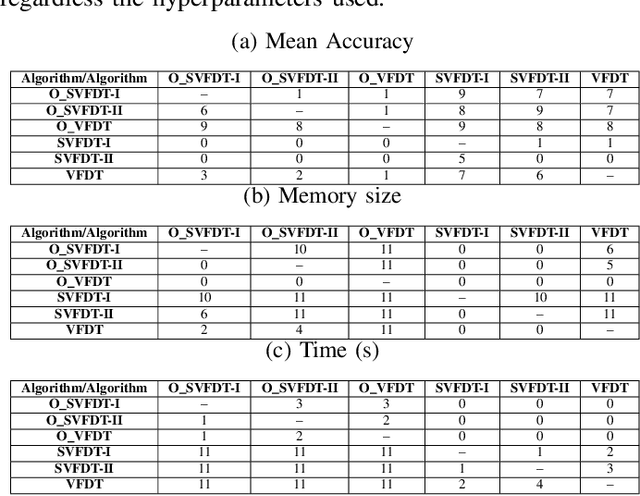
As more data are produced each day, and faster, data stream mining is growing in importance, making clear the need for algorithms able to fast process these data. Data stream mining algorithms are meant to be solutions to extract knowledge online, specially tailored from continuous data problem. Many of the current algorithms for data stream mining have high processing and memory costs. Often, the higher the predictive performance, the higher these costs. To increase predictive performance without largely increasing memory and time costs, this paper introduces a novel algorithm, named Online Local Boosting (OLBoost), which can be combined into online decision tree algorithms to improve their predictive performance without modifying the structure of the induced decision trees. For such, OLBoost applies a boosting to small separate regions of the instances space. Experimental results presented in this paper show that by using OLBoost the online learning decision tree algorithms can significantly improve their predictive performance. Additionally, it can make smaller trees perform as good or better than larger trees.
Online Multi-target regression trees with stacked leaf models
Mar 29, 2019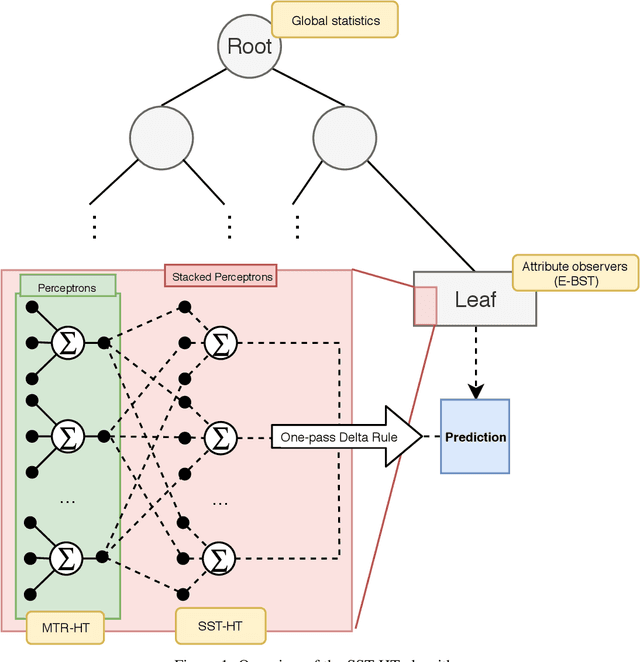
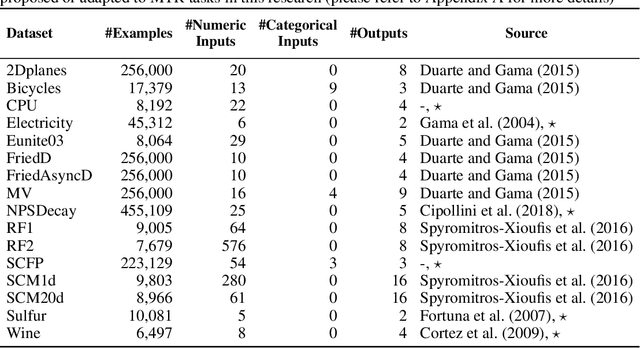

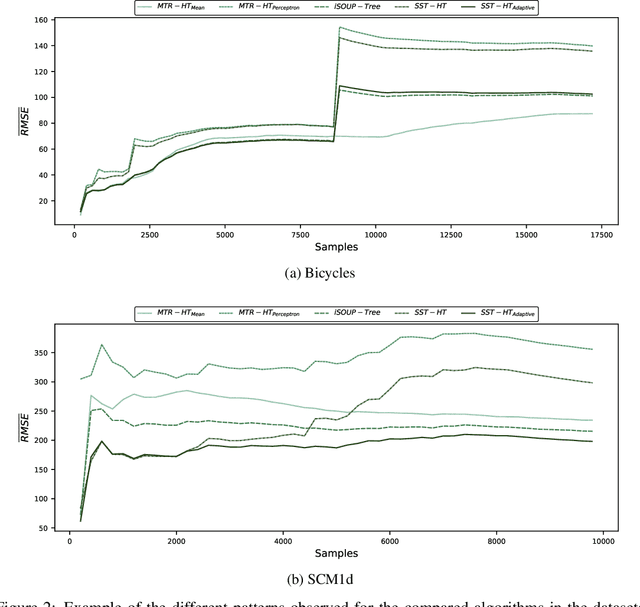
The amount of available data raises at large steps. Developing machine learning strategies to cope with the high throughput and changing data streams is a scope of high relevance. Among the prediction tasks in online machine learning, multi-target regression has gained increased attention due to its high applicability and relation with real-world problems. While reliable and effective solutions have been proposed for batch multi-target regression, the few existing solutions in the online scenario present gaps which should be further investigated. Among these problems, none of the existing solutions consider the occurrence of inter-target correlations when making predictions. In this work, we propose an extension to existing decision tree based solutions in online multi-target regression which tackles the problem mentioned above. Our proposal, called Stacked Single-target Hoeffding Tree (SST-HT) uses the inter-target dependencies as an additional information source to enhance accuracy. Throughout an extensive experimental setup, we evaluate our proposal against state-of-the-art decision tree-based solutions for online multi-target regression tasks on sixteen datasets. Our observations show that SST-HT is capable of achieving significantly smaller errors than the other methods, whereas only increasing the needed time and memory requirements in small amounts.