 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrace Encoding in Process Mining: a survey and benchmarking
Jan 05, 2023Encoding methods are employed across several process mining tasks, including predictive process monitoring, anomalous case detection, trace clustering, etc. These methods are usually performed as preprocessing steps and are responsible for transforming complex information into a numerical feature space. Most papers choose existing encoding methods arbitrarily or employ a strategy based on a specific expert knowledge domain. Moreover, existing methods are employed by using their default hyperparameters without evaluating other options. This practice can lead to several drawbacks, such as suboptimal performance and unfair comparisons with the state-of-the-art. Therefore, this work aims at providing a comprehensive survey on event log encoding by comparing 27 methods, from different natures, in terms of expressivity, scalability, correlation, and domain agnosticism. To the best of our knowledge, this is the most comprehensive study so far focusing on trace encoding in process mining. It contributes to maturing awareness about the role of trace encoding in process mining pipelines and sheds light on issues, concerns, and future research directions regarding the use of encoding methods to bridge the gap between machine learning models and process mining.
Online Multi-target regression trees with stacked leaf models
Mar 29, 2019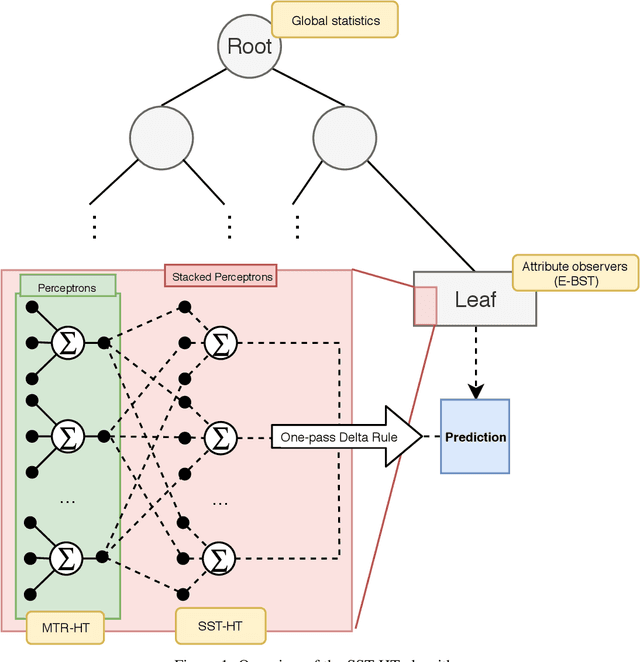
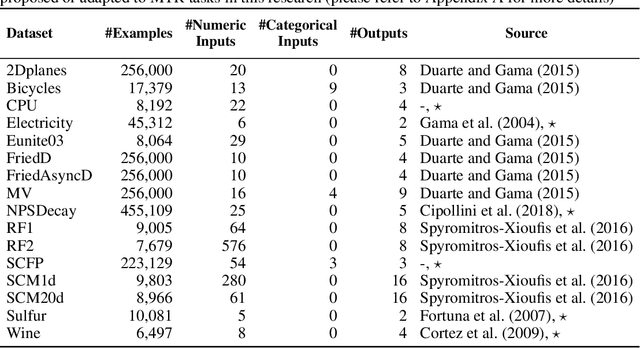

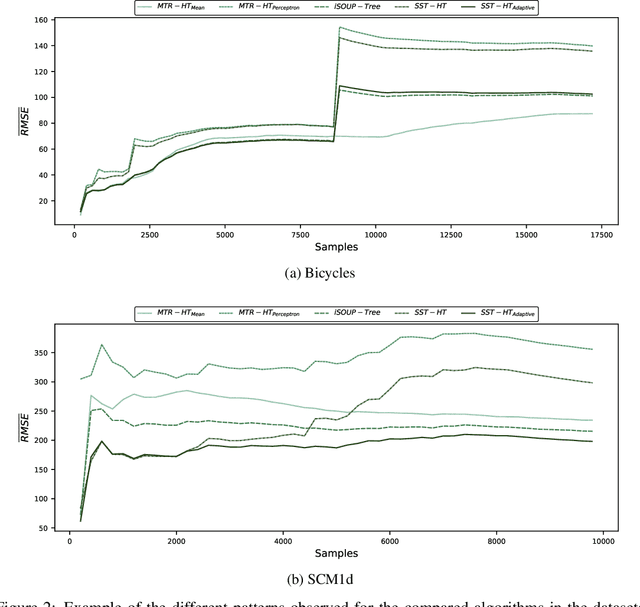
The amount of available data raises at large steps. Developing machine learning strategies to cope with the high throughput and changing data streams is a scope of high relevance. Among the prediction tasks in online machine learning, multi-target regression has gained increased attention due to its high applicability and relation with real-world problems. While reliable and effective solutions have been proposed for batch multi-target regression, the few existing solutions in the online scenario present gaps which should be further investigated. Among these problems, none of the existing solutions consider the occurrence of inter-target correlations when making predictions. In this work, we propose an extension to existing decision tree based solutions in online multi-target regression which tackles the problem mentioned above. Our proposal, called Stacked Single-target Hoeffding Tree (SST-HT) uses the inter-target dependencies as an additional information source to enhance accuracy. Throughout an extensive experimental setup, we evaluate our proposal against state-of-the-art decision tree-based solutions for online multi-target regression tasks on sixteen datasets. Our observations show that SST-HT is capable of achieving significantly smaller errors than the other methods, whereas only increasing the needed time and memory requirements in small amounts.