 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternational AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
No Pattern, No Recognition: a Survey about Reproducibility and Distortion Issues of Text Clustering and Topic Modeling
Aug 02, 2022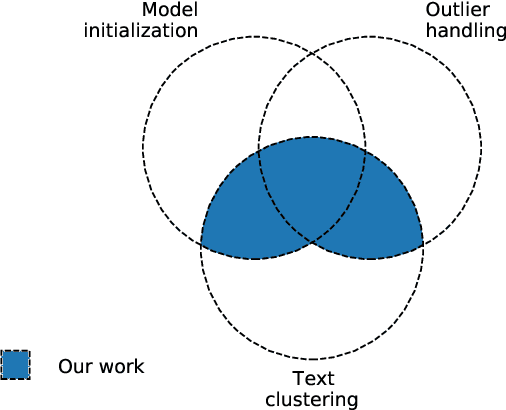


Extracting knowledge from unlabeled texts using machine learning algorithms can be complex. Document categorization and information retrieval are two applications that may benefit from unsupervised learning (e.g., text clustering and topic modeling), including exploratory data analysis. However, the unsupervised learning paradigm poses reproducibility issues. The initialization can lead to variability depending on the machine learning algorithm. Furthermore, the distortions can be misleading when regarding cluster geometry. Amongst the causes, the presence of outliers and anomalies can be a determining factor. Despite the relevance of initialization and outlier issues for text clustering and topic modeling, the authors did not find an in-depth analysis of them. This survey provides a systematic literature review (2011-2022) of these subareas and proposes a common terminology since similar procedures have different terms. The authors describe research opportunities, trends, and open issues. The appendices summarize the theoretical background of the text vectorization, the factorization, and the clustering algorithms that are directly or indirectly related to the reviewed works.
Rethinking Default Values: a Low Cost and Efficient Strategy to Define Hyperparameters
Aug 19, 2020
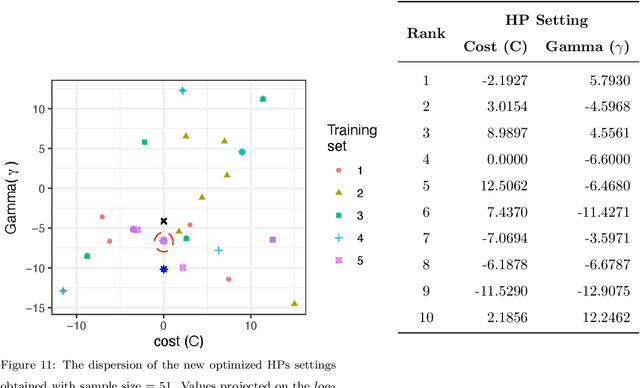
Machine Learning (ML) algorithms have been successfully employed by a vast range of practitioners with different backgrounds. One of the reasons for ML popularity is the capability to consistently delivers accurate results, which can be further boosted by adjusting hyperparameters (HP). However, part of practitioners has limited knowledge about the algorithms and does not take advantage of suitable HP settings. In general, HP values are defined by trial and error, tuning, or by using default values. Trial and error is very subjective, time costly and dependent on the user experience. Tuning techniques search for HP values able to maximize the predictive performance of induced models for a given dataset, but with the drawback of a high computational cost and target specificity. To avoid tuning costs, practitioners use default values suggested by the algorithm developer or by tools implementing the algorithm. Although default values usually result in models with acceptable predictive performance, different implementations of the same algorithm can suggest distinct default values. To maintain a balance between tuning and using default values, we propose a strategy to generate new optimized default values. Our approach is grounded on a small set of optimized values able to obtain predictive performance values better than default settings provided by popular tools. The HP candidates are estimated through a pool of promising values tuned from a small and informative set of datasets. After performing a large experiment and a careful analysis of the results, we concluded that our approach delivers better default values. Besides, it leads to competitive solutions when compared with the use of tuned values, being easier to use and having a lower cost.Based on our results, we also extracted simple rules to guide practitioners in deciding whether using our new methodology or a tuning approach.
A meta-learning recommender system for hyperparameter tuning: predicting when tuning improves SVM classifiers
Jun 11, 2019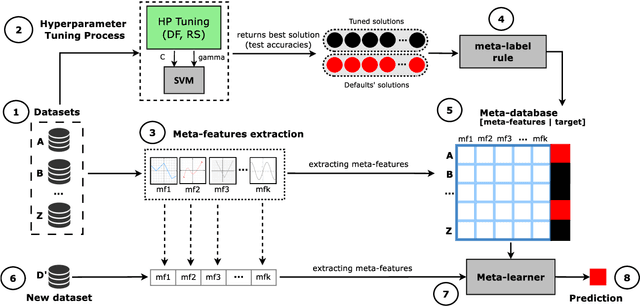
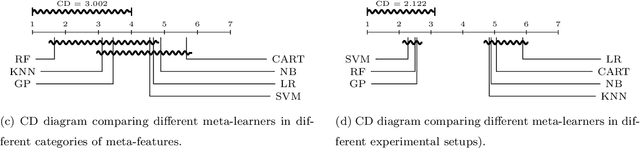
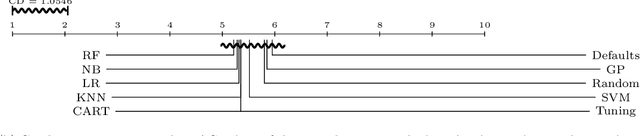
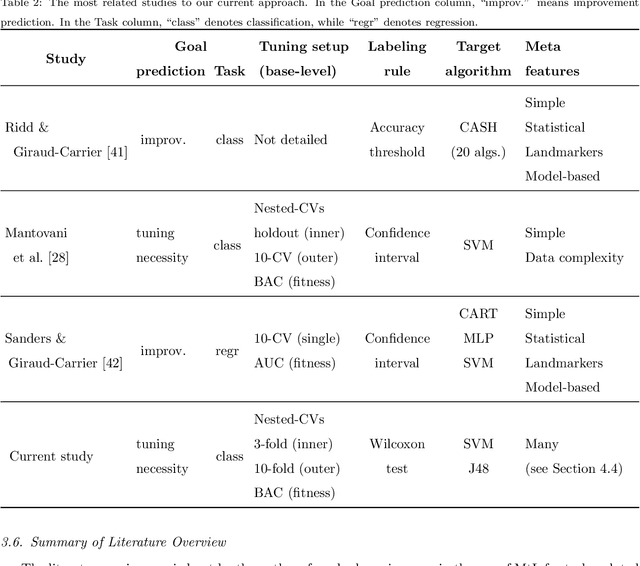
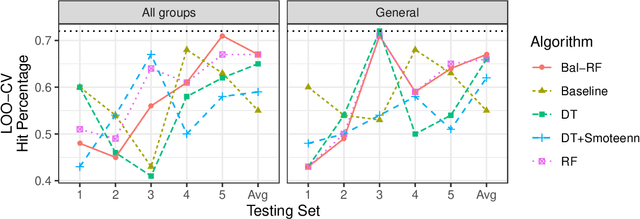
For many machine learning algorithms, predictive performance is critically affected by the hyperparameter values used to train them. However, tuning these hyperparameters can come at a high computational cost, especially on larger datasets, while the tuned settings do not always significantly outperform the default values. This paper proposes a recommender system based on meta-learning to identify exactly when it is better to use default values and when to tune hyperparameters for each new dataset. Besides, an in-depth analysis is performed to understand what they take into account for their decisions, providing useful insights. An extensive analysis of different categories of meta-features, meta-learners, and setups across 156 datasets is performed. Results show that it is possible to accurately predict when tuning will significantly improve the performance of the induced models. The proposed system reduces the time spent on optimization processes, without reducing the predictive performance of the induced models (when compared with the ones obtained using tuned hyperparameters). We also explain the decision-making process of the meta-learners in terms of linear separability-based hypotheses. Although this analysis is focused on the tuning of Support Vector Machines, it can also be applied to other algorithms, as shown in experiments performed with decision trees.
* 49 pages, 11 figures
Online Multi-target regression trees with stacked leaf models
Mar 29, 2019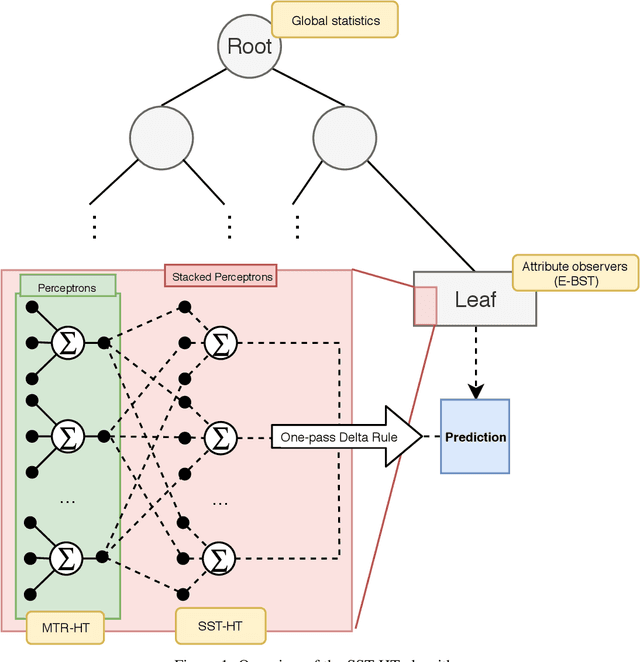
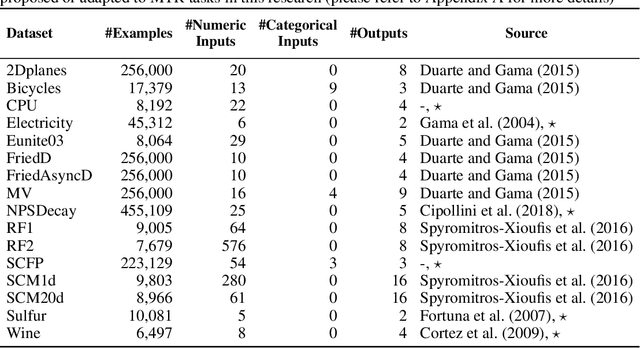

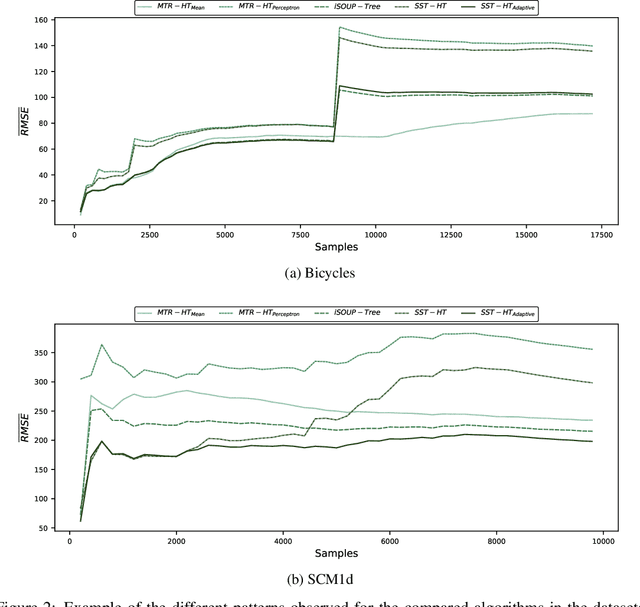
The amount of available data raises at large steps. Developing machine learning strategies to cope with the high throughput and changing data streams is a scope of high relevance. Among the prediction tasks in online machine learning, multi-target regression has gained increased attention due to its high applicability and relation with real-world problems. While reliable and effective solutions have been proposed for batch multi-target regression, the few existing solutions in the online scenario present gaps which should be further investigated. Among these problems, none of the existing solutions consider the occurrence of inter-target correlations when making predictions. In this work, we propose an extension to existing decision tree based solutions in online multi-target regression which tackles the problem mentioned above. Our proposal, called Stacked Single-target Hoeffding Tree (SST-HT) uses the inter-target dependencies as an additional information source to enhance accuracy. Throughout an extensive experimental setup, we evaluate our proposal against state-of-the-art decision tree-based solutions for online multi-target regression tasks on sixteen datasets. Our observations show that SST-HT is capable of achieving significantly smaller errors than the other methods, whereas only increasing the needed time and memory requirements in small amounts.
An empirical study on hyperparameter tuning of decision trees
Dec 05, 2018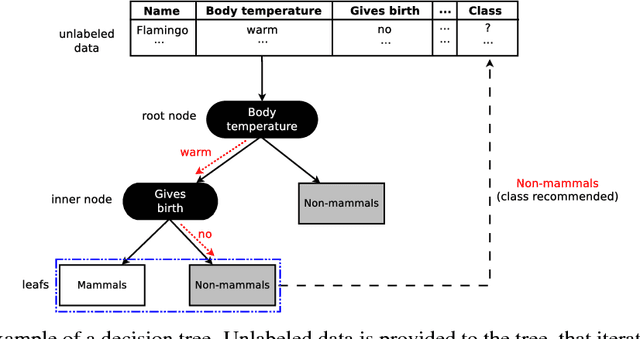
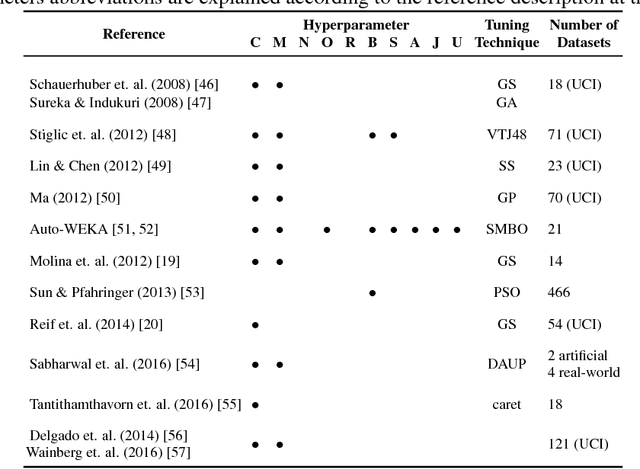
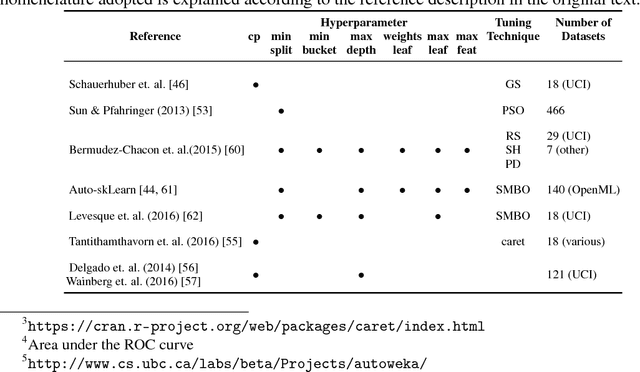
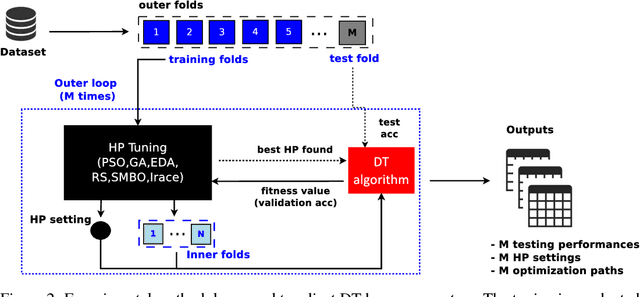
Machine learning algorithms often contain many hyperparameters whose values affect the predictive performance of the induced models in intricate ways. Due to the high number of possibilities for these hyperparameter configurations, and their complex interactions, it is common to use optimization techniques to find settings that lead to high predictive accuracy. However, we lack insight into how to efficiently explore this vast space of configurations: which are the best optimization techniques, how should we use them, and how significant is their effect on predictive or runtime performance? This paper provides a comprehensive approach for investigating the effects of hyperparameter tuning on three Decision Tree induction algorithms, CART, C4.5 and CTree. These algorithms were selected because they are based on similar principles, have presented a high predictive performance in several previous works and induce interpretable classification models. Additionally, they contain many interacting hyperparameters to be adjusted. Experiments were carried out with different tuning strategies to induce models and evaluate the relevance of hyperparameters using 94 classification datasets from OpenML. Experimental results indicate that hyperparameter tuning provides statistically significant improvements for C4.5 and CTree in only one-third of the datasets, and in most of the datasets for CART. Different tree algorithms may present different tuning scenarios, but in general, the tuning techniques required relatively few iterations to find accurate solutions. Furthermore, the best technique for all the algorithms was the Irace. Finally, we find that tuning a specific small subset of hyperparameters contributes most of the achievable optimal predictive performance.
Strict Very Fast Decision Tree: a memory conservative algorithm for data stream mining
May 17, 2018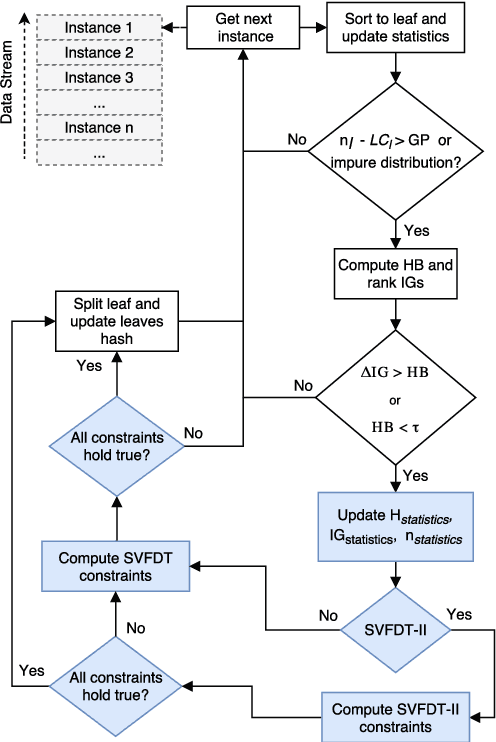
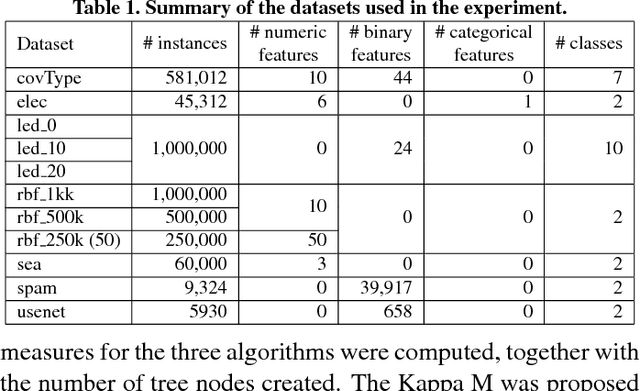

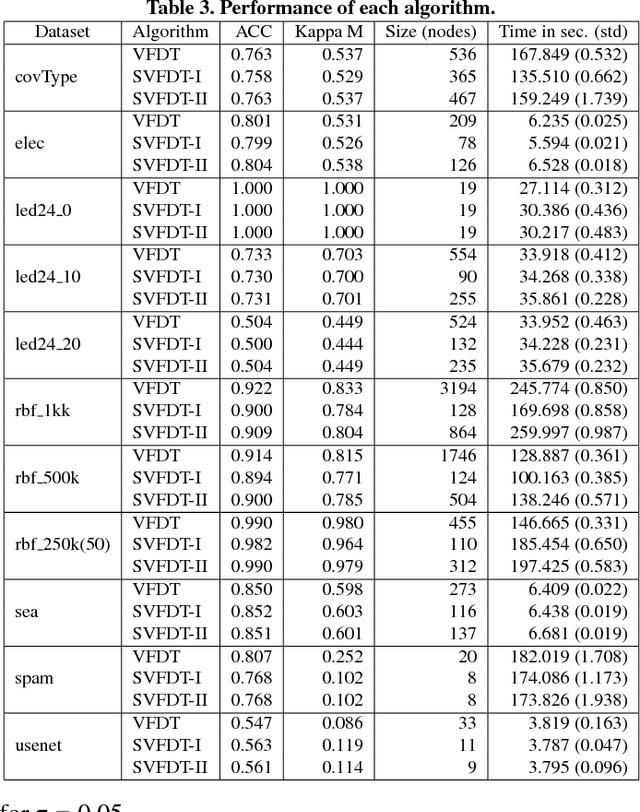
Dealing with memory and time constraints are current challenges when learning from data streams with a massive amount of data. Many algorithms have been proposed to handle these difficulties, among them, the Very Fast Decision Tree (VFDT) algorithm. Although the VFDT has been widely used in data stream mining, in the last years, several authors have suggested modifications to increase its performance, putting aside memory concerns by proposing memory-costly solutions. Besides, most data stream mining solutions have been centred around ensembles, which combine the memory costs of their weak learners, usually VFDTs. To reduce the memory cost, keeping the predictive performance, this study proposes the Strict VFDT (SVFDT), a novel algorithm based on the VFDT. The SVFDT algorithm minimises unnecessary tree growth, substantially reducing memory usage and keeping competitive predictive performance. Moreover, since it creates much more shallow trees than VFDT, SVFDT can achieve a shorter processing time. Experiments were carried out comparing the SVFDT with the VFDT in 11 benchmark data stream datasets. This comparison assessed the trade-off between accuracy, memory, and processing time. Statistical analysis showed that the proposed algorithm obtained similar predictive performance and significantly reduced processing time and memory use. Thus, SVFDT is a suitable option for data stream mining with memory and time limitations, recommended as a weak learner in ensemble-based solutions.