 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Pattern, No Recognition: a Survey about Reproducibility and Distortion Issues of Text Clustering and Topic Modeling
Paper and Code
Aug 02, 2022

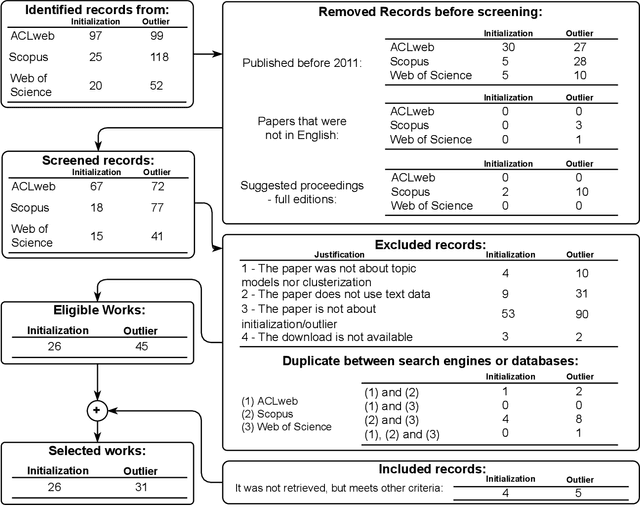

Extracting knowledge from unlabeled texts using machine learning algorithms can be complex. Document categorization and information retrieval are two applications that may benefit from unsupervised learning (e.g., text clustering and topic modeling), including exploratory data analysis. However, the unsupervised learning paradigm poses reproducibility issues. The initialization can lead to variability depending on the machine learning algorithm. Furthermore, the distortions can be misleading when regarding cluster geometry. Amongst the causes, the presence of outliers and anomalies can be a determining factor. Despite the relevance of initialization and outlier issues for text clustering and topic modeling, the authors did not find an in-depth analysis of them. This survey provides a systematic literature review (2011-2022) of these subareas and proposes a common terminology since similar procedures have different terms. The authors describe research opportunities, trends, and open issues. The appendices summarize the theoretical background of the text vectorization, the factorization, and the clustering algorithms that are directly or indirectly related to the reviewed works.