 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection and Hyperparameter Fine-tuning in Artificial Neural Networks for Wood Quality Classification
Oct 20, 2023Quality classification of wood boards is an essential task in the sawmill industry, which is still usually performed by human operators in small to median companies in developing countries. Machine learning algorithms have been successfully employed to investigate the problem, offering a more affordable alternative compared to other solutions. However, such approaches usually present some drawbacks regarding the proper selection of their hyperparameters. Moreover, the models are susceptible to the features extracted from wood board images, which influence the induction of the model and, consequently, its generalization power. Therefore, in this paper, we investigate the problem of simultaneously tuning the hyperparameters of an artificial neural network (ANN) as well as selecting a subset of characteristics that better describes the wood board quality. Experiments were conducted over a private dataset composed of images obtained from a sawmill industry and described using different feature descriptors. The predictive performance of the model was compared against five baseline methods as well as a random search, performing either ANN hyperparameter tuning and feature selection. Experimental results suggest that hyperparameters should be adjusted according to the feature set, or the features should be selected considering the hyperparameter values. In summary, the best predictive performance, i.e., a balanced accuracy of $0.80$, was achieved in two distinct scenarios: (i) performing only feature selection, and (ii) performing both tasks concomitantly. Thus, we suggest that at least one of the two approaches should be considered in the context of industrial applications.
Rethinking Default Values: a Low Cost and Efficient Strategy to Define Hyperparameters
Aug 19, 2020
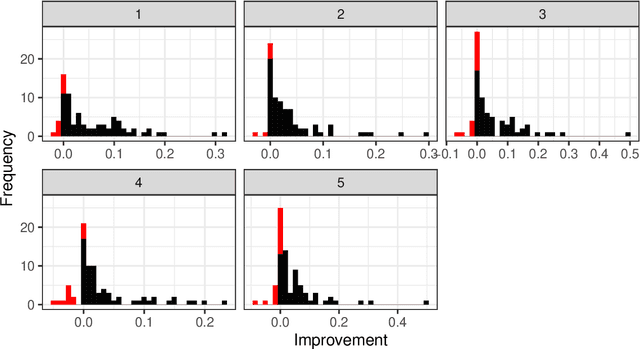
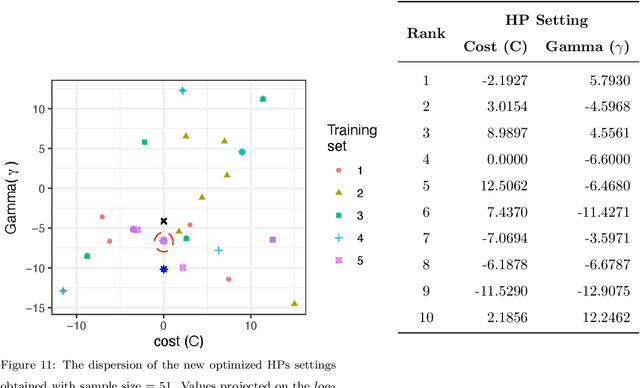
Machine Learning (ML) algorithms have been successfully employed by a vast range of practitioners with different backgrounds. One of the reasons for ML popularity is the capability to consistently delivers accurate results, which can be further boosted by adjusting hyperparameters (HP). However, part of practitioners has limited knowledge about the algorithms and does not take advantage of suitable HP settings. In general, HP values are defined by trial and error, tuning, or by using default values. Trial and error is very subjective, time costly and dependent on the user experience. Tuning techniques search for HP values able to maximize the predictive performance of induced models for a given dataset, but with the drawback of a high computational cost and target specificity. To avoid tuning costs, practitioners use default values suggested by the algorithm developer or by tools implementing the algorithm. Although default values usually result in models with acceptable predictive performance, different implementations of the same algorithm can suggest distinct default values. To maintain a balance between tuning and using default values, we propose a strategy to generate new optimized default values. Our approach is grounded on a small set of optimized values able to obtain predictive performance values better than default settings provided by popular tools. The HP candidates are estimated through a pool of promising values tuned from a small and informative set of datasets. After performing a large experiment and a careful analysis of the results, we concluded that our approach delivers better default values. Besides, it leads to competitive solutions when compared with the use of tuned values, being easier to use and having a lower cost.Based on our results, we also extracted simple rules to guide practitioners in deciding whether using our new methodology or a tuning approach.
A meta-learning recommender system for hyperparameter tuning: predicting when tuning improves SVM classifiers
Jun 11, 2019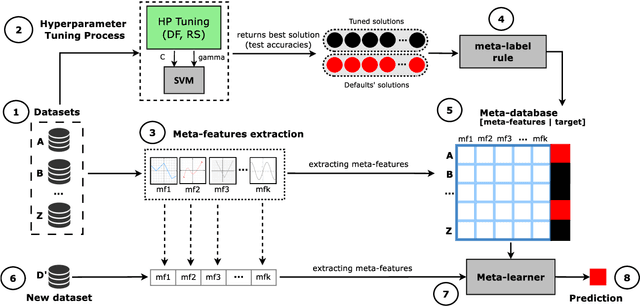
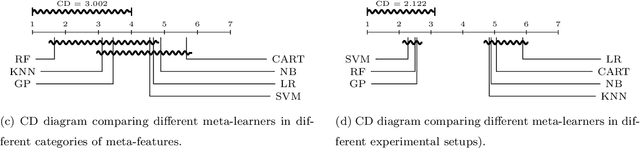
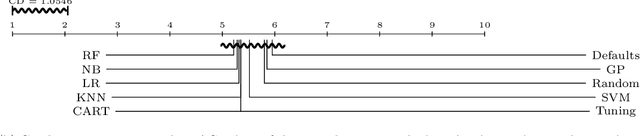
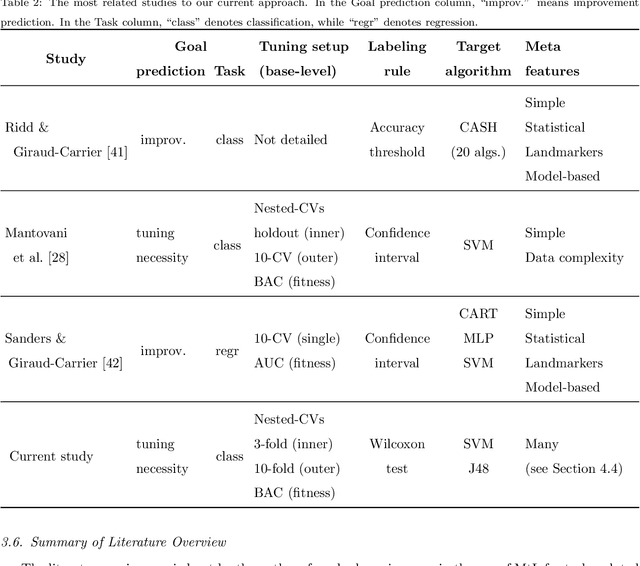
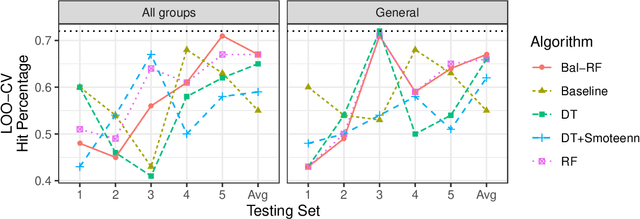
For many machine learning algorithms, predictive performance is critically affected by the hyperparameter values used to train them. However, tuning these hyperparameters can come at a high computational cost, especially on larger datasets, while the tuned settings do not always significantly outperform the default values. This paper proposes a recommender system based on meta-learning to identify exactly when it is better to use default values and when to tune hyperparameters for each new dataset. Besides, an in-depth analysis is performed to understand what they take into account for their decisions, providing useful insights. An extensive analysis of different categories of meta-features, meta-learners, and setups across 156 datasets is performed. Results show that it is possible to accurately predict when tuning will significantly improve the performance of the induced models. The proposed system reduces the time spent on optimization processes, without reducing the predictive performance of the induced models (when compared with the ones obtained using tuned hyperparameters). We also explain the decision-making process of the meta-learners in terms of linear separability-based hypotheses. Although this analysis is focused on the tuning of Support Vector Machines, it can also be applied to other algorithms, as shown in experiments performed with decision trees.
* 49 pages, 11 figures