 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection and Hyperparameter Fine-tuning in Artificial Neural Networks for Wood Quality Classification
Oct 20, 2023Quality classification of wood boards is an essential task in the sawmill industry, which is still usually performed by human operators in small to median companies in developing countries. Machine learning algorithms have been successfully employed to investigate the problem, offering a more affordable alternative compared to other solutions. However, such approaches usually present some drawbacks regarding the proper selection of their hyperparameters. Moreover, the models are susceptible to the features extracted from wood board images, which influence the induction of the model and, consequently, its generalization power. Therefore, in this paper, we investigate the problem of simultaneously tuning the hyperparameters of an artificial neural network (ANN) as well as selecting a subset of characteristics that better describes the wood board quality. Experiments were conducted over a private dataset composed of images obtained from a sawmill industry and described using different feature descriptors. The predictive performance of the model was compared against five baseline methods as well as a random search, performing either ANN hyperparameter tuning and feature selection. Experimental results suggest that hyperparameters should be adjusted according to the feature set, or the features should be selected considering the hyperparameter values. In summary, the best predictive performance, i.e., a balanced accuracy of $0.80$, was achieved in two distinct scenarios: (i) performing only feature selection, and (ii) performing both tasks concomitantly. Thus, we suggest that at least one of the two approaches should be considered in the context of industrial applications.
Facial Point Graphs for Amyotrophic Lateral Sclerosis Identification
Jul 22, 2023


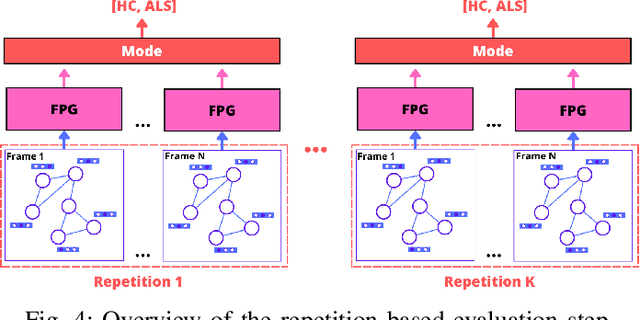
Identifying Amyotrophic Lateral Sclerosis (ALS) in its early stages is essential for establishing the beginning of treatment, enriching the outlook, and enhancing the overall well-being of those affected individuals. However, early diagnosis and detecting the disease's signs is not straightforward. A simpler and cheaper way arises by analyzing the patient's facial expressions through computational methods. When a patient with ALS engages in specific actions, e.g., opening their mouth, the movement of specific facial muscles differs from that observed in a healthy individual. This paper proposes Facial Point Graphs to learn information from the geometry of facial images to identify ALS automatically. The experimental outcomes in the Toronto Neuroface dataset show the proposed approach outperformed state-of-the-art results, fostering promising developments in the area.
Enhancing Hyper-To-Real Space Projections Through Euclidean Norm Meta-Heuristic Optimization
Jan 31, 2023The continuous computational power growth in the last decades has made solving several optimization problems significant to humankind a tractable task; however, tackling some of them remains a challenge due to the overwhelming amount of candidate solutions to be evaluated, even by using sophisticated algorithms. In such a context, a set of nature-inspired stochastic methods, called meta-heuristic optimization, can provide robust approximate solutions to different kinds of problems with a small computational burden, such as derivative-free real function optimization. Nevertheless, these methods may converge to inadequate solutions if the function landscape is too harsh, e.g., enclosing too many local optima. Previous works addressed this issue by employing a hypercomplex representation of the search space, like quaternions, where the landscape becomes smoother and supposedly easier to optimize. Under this approach, meta-heuristic computations happen in the hypercomplex space, whereas variables are mapped back to the real domain before function evaluation. Despite this latter operation being performed by the Euclidean norm, we have found that after the optimization procedure has finished, it is usually possible to obtain even better solutions by employing the Minkowski $p$-norm instead and fine-tuning $p$ through an auxiliary sub-problem with neglecting additional cost and no hyperparameters. Such behavior was observed in eight well-established benchmarking functions, thus fostering a new research direction for hypercomplex meta-heuristic optimization.
Improving Pre-Trained Weights Through Meta-Heuristics Fine-Tuning
Dec 19, 2022



Machine Learning algorithms have been extensively researched throughout the last decade, leading to unprecedented advances in a broad range of applications, such as image classification and reconstruction, object recognition, and text categorization. Nonetheless, most Machine Learning algorithms are trained via derivative-based optimizers, such as the Stochastic Gradient Descent, leading to possible local optimum entrapments and inhibiting them from achieving proper performances. A bio-inspired alternative to traditional optimization techniques, denoted as meta-heuristic, has received significant attention due to its simplicity and ability to avoid local optimums imprisonment. In this work, we propose to use meta-heuristic techniques to fine-tune pre-trained weights, exploring additional regions of the search space, and improving their effectiveness. The experimental evaluation comprises two classification tasks (image and text) and is assessed under four literature datasets. Experimental results show nature-inspired algorithms' capacity in exploring the neighborhood of pre-trained weights, achieving superior results than their counterpart pre-trained architectures. Additionally, a thorough analysis of distinct architectures, such as Multi-Layer Perceptron and Recurrent Neural Networks, attempts to visualize and provide more precise insights into the most critical weights to be fine-tuned in the learning process.
From Actions to Events: A Transfer Learning Approach Using Improved Deep Belief Networks
Nov 30, 2022



In the last decade, exponential data growth supplied machine learning-based algorithms' capacity and enabled their usage in daily-life activities. Additionally, such an improvement is partially explained due to the advent of deep learning techniques, i.e., stacks of simple architectures that end up in more complex models. Although both factors produce outstanding results, they also pose drawbacks regarding the learning process as training complex models over large datasets are expensive and time-consuming. Such a problem is even more evident when dealing with video analysis. Some works have considered transfer learning or domain adaptation, i.e., approaches that map the knowledge from one domain to another, to ease the training burden, yet most of them operate over individual or small blocks of frames. This paper proposes a novel approach to map the knowledge from action recognition to event recognition using an energy-based model, denoted as Spectral Deep Belief Network. Such a model can process all frames simultaneously, carrying spatial and temporal information through the learning process. The experimental results conducted over two public video dataset, the HMDB-51 and the UCF-101, depict the effectiveness of the proposed model and its reduced computational burden when compared to traditional energy-based models, such as Restricted Boltzmann Machines and Deep Belief Networks.
MaxDropoutV2: An Improved Method to Drop out Neurons in Convolutional Neural Networks
Mar 05, 2022
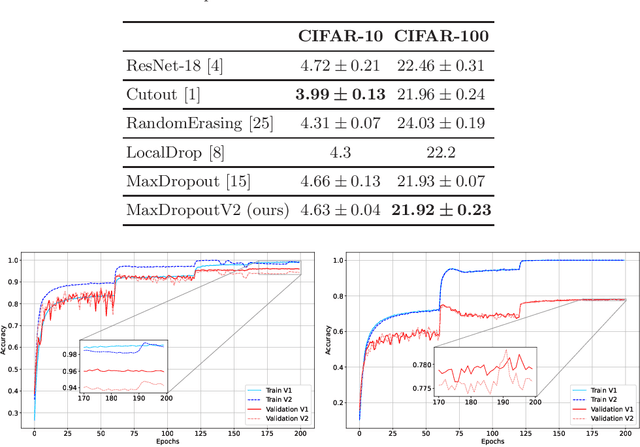
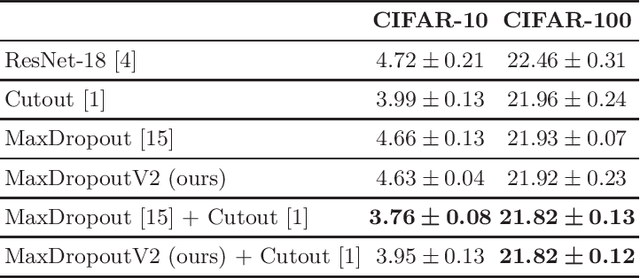

In the last decade, exponential data growth supplied the machine learning-based algorithms' capacity and enabled their usage in daily life activities. Additionally, such an improvement is partially explained due to the advent of deep learning techniques, i.e., stacks of simple architectures that end up in more complex models. Although both factors produce outstanding results, they also pose drawbacks regarding the learning process since training complex models denotes an expensive task and results are prone to overfit the training data. A supervised regularization technique called MaxDropout was recently proposed to tackle the latter, providing several improvements concerning traditional regularization approaches. In this paper, we present its improved version called MaxDropoutV2. Results considering two public datasets show that the model performs faster than the standard version and, in most cases, provides more accurate results.
Comparative Study Between Distance Measures On Supervised Optimum-Path Forest Classification
Feb 08, 2022



Machine Learning has attracted considerable attention throughout the past decade due to its potential to solve far-reaching tasks, such as image classification, object recognition, anomaly detection, and data forecasting. A standard approach to tackle such applications is based on supervised learning, which is assisted by large sets of labeled data and is conducted by the so-called classifiers, such as Logistic Regression, Decision Trees, Random Forests, and Support Vector Machines, among others. An alternative to traditional classifiers is the parameterless Optimum-Path Forest (OPF), which uses a graph-based methodology and a distance measure to create arcs between nodes and hence sets of trees, responsible for conquering the nodes, defining their labels, and shaping the forests. Nevertheless, its performance is strongly associated with an appropriate distance measure, which may vary according to the dataset's nature. Therefore, this work proposes a comparative study over a wide range of distance measures applied to the supervised Optimum-Path Forest classification. The experimental results are conducted using well-known literature datasets and compared across benchmarking classifiers, illustrating OPF's ability to adapt to distinct domains.
Gait Recognition Based on Deep Learning: A Survey
Jan 10, 2022
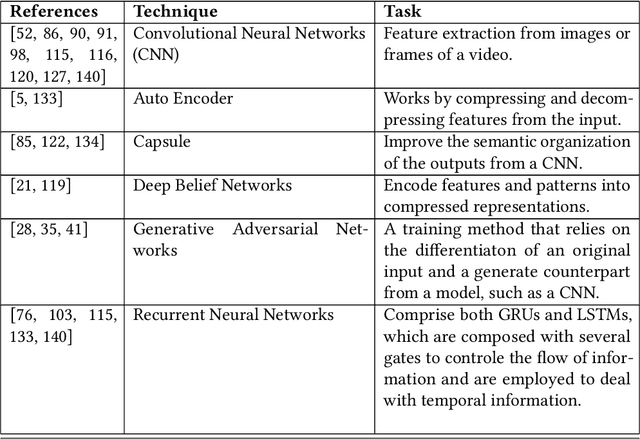
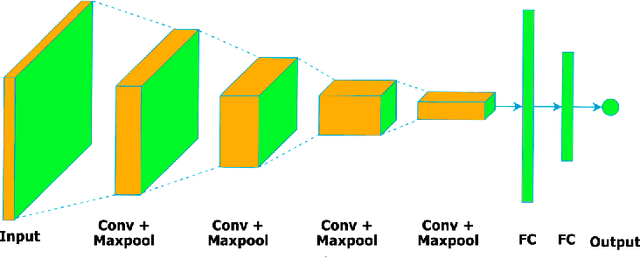
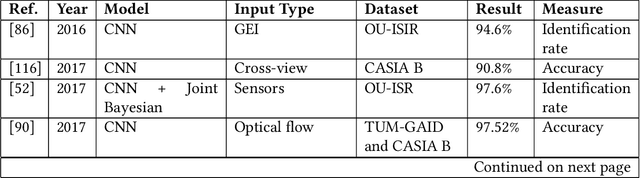
In general, biometry-based control systems may not rely on individual expected behavior or cooperation to operate appropriately. Instead, such systems should be aware of malicious procedures for unauthorized access attempts. Some works available in the literature suggest addressing the problem through gait recognition approaches. Such methods aim at identifying human beings through intrinsic perceptible features, despite dressed clothes or accessories. Although the issue denotes a relatively long-time challenge, most of the techniques developed to handle the problem present several drawbacks related to feature extraction and low classification rates, among other issues. However, deep learning-based approaches recently emerged as a robust set of tools to deal with virtually any image and computer-vision related problem, providing paramount results for gait recognition as well. Therefore, this work provides a surveyed compilation of recent works regarding biometric detection through gait recognition with a focus on deep learning approaches, emphasizing their benefits, and exposing their weaknesses. Besides, it also presents categorized and characterized descriptions of the datasets, approaches, and architectures employed to tackle associated constraints.
A Layer-Wise Information Reinforcement Approach to Improve Learning in Deep Belief Networks
Jan 17, 2021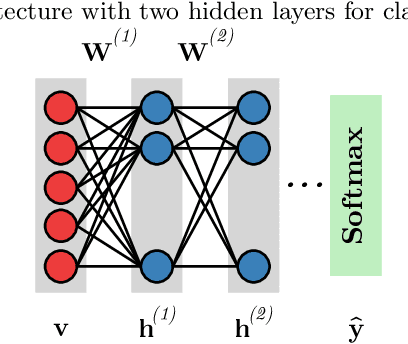

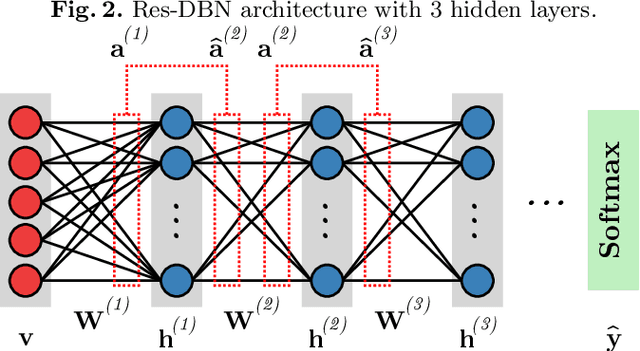
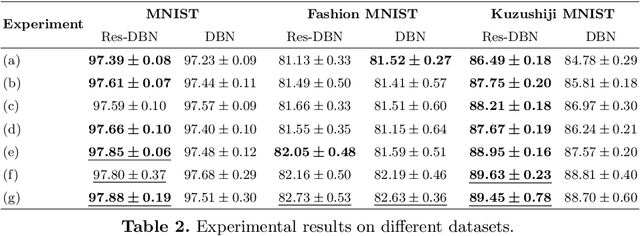
With the advent of deep learning, the number of works proposing new methods or improving existent ones has grown exponentially in the last years. In this scenario, "very deep" models were emerging, once they were expected to extract more intrinsic and abstract features while supporting a better performance. However, such models suffer from the gradient vanishing problem, i.e., backpropagation values become too close to zero in their shallower layers, ultimately causing learning to stagnate. Such an issue was overcome in the context of convolution neural networks by creating "shortcut connections" between layers, in a so-called deep residual learning framework. Nonetheless, a very popular deep learning technique called Deep Belief Network still suffers from gradient vanishing when dealing with discriminative tasks. Therefore, this paper proposes the Residual Deep Belief Network, which considers the information reinforcement layer-by-layer to improve the feature extraction and knowledge retaining, that support better discriminative performance. Experiments conducted over three public datasets demonstrate its robustness concerning the task of binary image classification.
Intestinal Parasites Classification Using Deep Belief Networks
Jan 17, 2021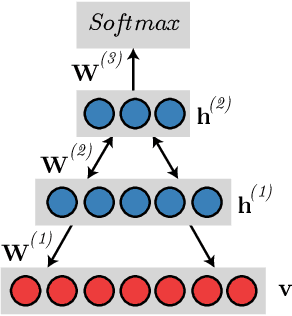

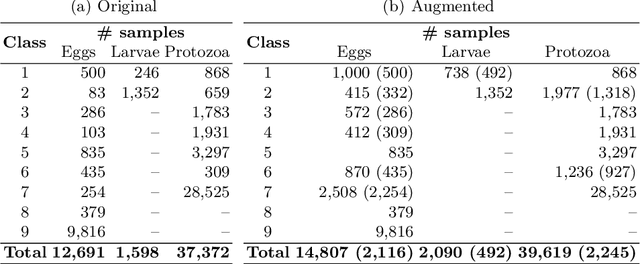
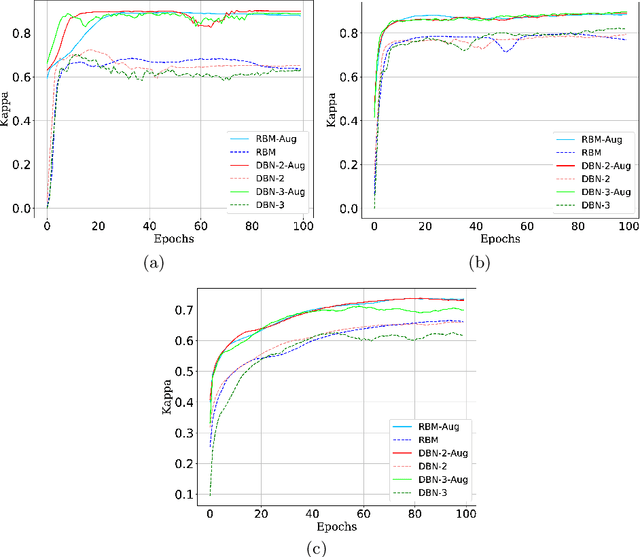
Currently, approximately $4$ billion people are infected by intestinal parasites worldwide. Diseases caused by such infections constitute a public health problem in most tropical countries, leading to physical and mental disorders, and even death to children and immunodeficient individuals. Although subjected to high error rates, human visual inspection is still in charge of the vast majority of clinical diagnoses. In the past years, some works addressed intelligent computer-aided intestinal parasites classification, but they usually suffer from misclassification due to similarities between parasites and fecal impurities. In this paper, we introduce Deep Belief Networks to the context of automatic intestinal parasites classification. Experiments conducted over three datasets composed of eggs, larvae, and protozoa provided promising results, even considering unbalanced classes and also fecal impurities.