 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Hyper-To-Real Space Projections Through Euclidean Norm Meta-Heuristic Optimization
Jan 31, 2023The continuous computational power growth in the last decades has made solving several optimization problems significant to humankind a tractable task; however, tackling some of them remains a challenge due to the overwhelming amount of candidate solutions to be evaluated, even by using sophisticated algorithms. In such a context, a set of nature-inspired stochastic methods, called meta-heuristic optimization, can provide robust approximate solutions to different kinds of problems with a small computational burden, such as derivative-free real function optimization. Nevertheless, these methods may converge to inadequate solutions if the function landscape is too harsh, e.g., enclosing too many local optima. Previous works addressed this issue by employing a hypercomplex representation of the search space, like quaternions, where the landscape becomes smoother and supposedly easier to optimize. Under this approach, meta-heuristic computations happen in the hypercomplex space, whereas variables are mapped back to the real domain before function evaluation. Despite this latter operation being performed by the Euclidean norm, we have found that after the optimization procedure has finished, it is usually possible to obtain even better solutions by employing the Minkowski $p$-norm instead and fine-tuning $p$ through an auxiliary sub-problem with neglecting additional cost and no hyperparameters. Such behavior was observed in eight well-established benchmarking functions, thus fostering a new research direction for hypercomplex meta-heuristic optimization.
Scene Change Detection Using Multiscale Cascade Residual Convolutional Neural Networks
Dec 20, 2022



Scene change detection is an image processing problem related to partitioning pixels of a digital image into foreground and background regions. Mostly, visual knowledge-based computer intelligent systems, like traffic monitoring, video surveillance, and anomaly detection, need to use change detection techniques. Amongst the most prominent detection methods, there are the learning-based ones, which besides sharing similar training and testing protocols, differ from each other in terms of their architecture design strategies. Such architecture design directly impacts on the quality of the detection results, and also in the device resources capacity, like memory. In this work, we propose a novel Multiscale Cascade Residual Convolutional Neural Network that integrates multiscale processing strategy through a Residual Processing Module, with a Segmentation Convolutional Neural Network. Experiments conducted on two different datasets support the effectiveness of the proposed approach, achieving average overall $\boldsymbol{F\text{-}measure}$ results of $\boldsymbol{0.9622}$ and $\boldsymbol{0.9664}$ over Change Detection 2014 and PetrobrasROUTES datasets respectively, besides comprising approximately eight times fewer parameters. Such obtained results place the proposed technique amongst the top four state-of-the-art scene change detection methods.
DDIPNet and DDIPNet+: Discriminant Deep Image Prior Networks for Remote Sensing Image Classification
Dec 20, 2022Research on remote sensing image classification significantly impacts essential human routine tasks such as urban planning and agriculture. Nowadays, the rapid advance in technology and the availability of many high-quality remote sensing images create a demand for reliable automation methods. The current paper proposes two novel deep learning-based architectures for image classification purposes, i.e., the Discriminant Deep Image Prior Network and the Discriminant Deep Image Prior Network+, which combine Deep Image Prior and Triplet Networks learning strategies. Experiments conducted over three well-known public remote sensing image datasets achieved state-of-the-art results, evidencing the effectiveness of using deep image priors for remote sensing image classification.
Video Segmentation Learning Using Cascade Residual Convolutional Neural Network
Dec 20, 2022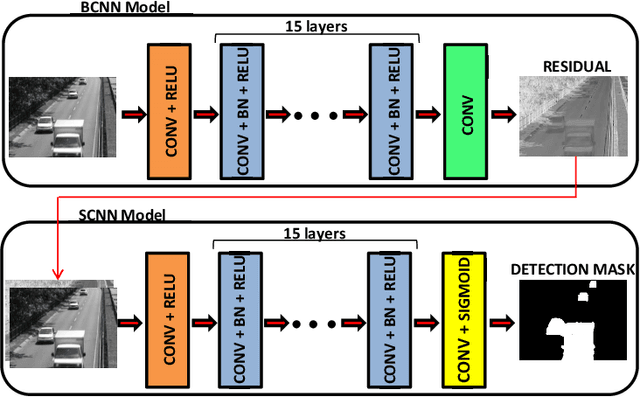

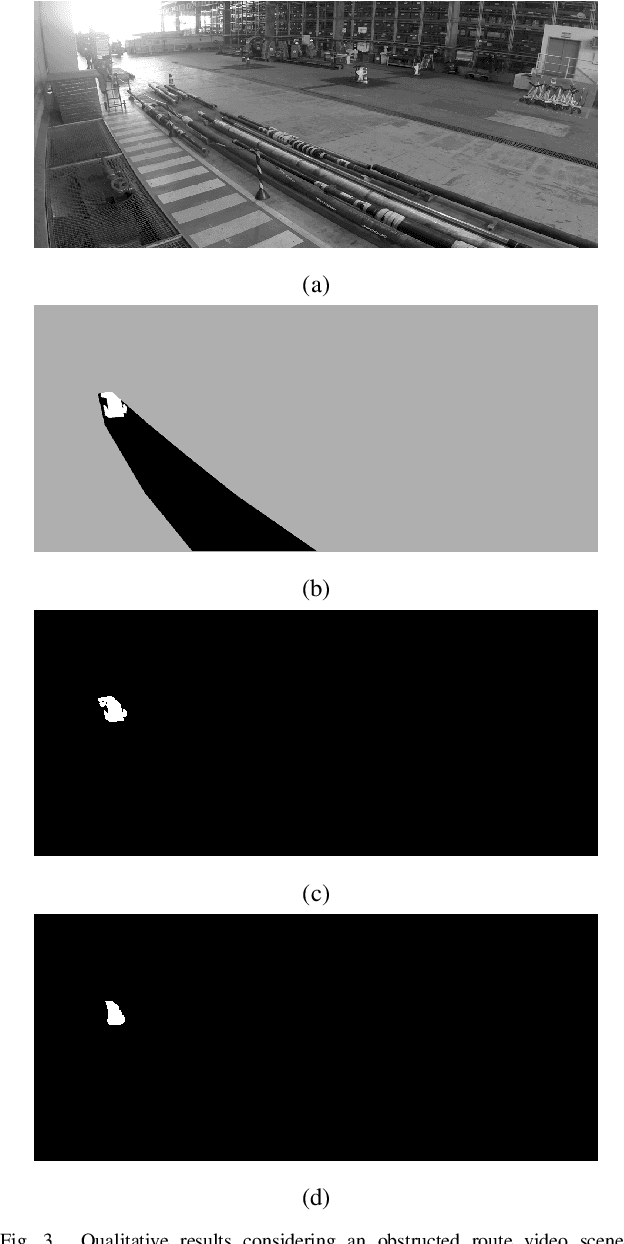

Video segmentation consists of a frame-by-frame selection process of meaningful areas related to foreground moving objects. Some applications include traffic monitoring, human tracking, action recognition, efficient video surveillance, and anomaly detection. In these applications, it is not rare to face challenges such as abrupt changes in weather conditions, illumination issues, shadows, subtle dynamic background motions, and also camouflage effects. In this work, we address such shortcomings by proposing a novel deep learning video segmentation approach that incorporates residual information into the foreground detection learning process. The main goal is to provide a method capable of generating an accurate foreground detection given a grayscale video. Experiments conducted on the Change Detection 2014 and on the private dataset PetrobrasROUTES from Petrobras support the effectiveness of the proposed approach concerning some state-of-the-art video segmentation techniques, with overall F-measures of $\mathbf{0.9535}$ and $\mathbf{0.9636}$ in the Change Detection 2014 and PetrobrasROUTES datasets, respectively. Such a result places the proposed technique amongst the top 3 state-of-the-art video segmentation methods, besides comprising approximately seven times less parameters than its top one counterpart.
FEMa-FS: Finite Element Machines for Feature Selection
Dec 05, 2022



Identifying anomalies has become one of the primary strategies towards security and protection procedures in computer networks. In this context, machine learning-based methods emerge as an elegant solution to identify such scenarios and learn irrelevant information so that a reduction in the identification time and possible gain in accuracy can be obtained. This paper proposes a novel feature selection approach called Finite Element Machines for Feature Selection (FEMa-FS), which uses the framework of finite elements to identify the most relevant information from a given dataset. Although FEMa-FS can be applied to any application domain, it has been evaluated in the context of anomaly detection in computer networks. The outcomes over two datasets showed promising results.
From Actions to Events: A Transfer Learning Approach Using Improved Deep Belief Networks
Nov 30, 2022



In the last decade, exponential data growth supplied machine learning-based algorithms' capacity and enabled their usage in daily-life activities. Additionally, such an improvement is partially explained due to the advent of deep learning techniques, i.e., stacks of simple architectures that end up in more complex models. Although both factors produce outstanding results, they also pose drawbacks regarding the learning process as training complex models over large datasets are expensive and time-consuming. Such a problem is even more evident when dealing with video analysis. Some works have considered transfer learning or domain adaptation, i.e., approaches that map the knowledge from one domain to another, to ease the training burden, yet most of them operate over individual or small blocks of frames. This paper proposes a novel approach to map the knowledge from action recognition to event recognition using an energy-based model, denoted as Spectral Deep Belief Network. Such a model can process all frames simultaneously, carrying spatial and temporal information through the learning process. The experimental results conducted over two public video dataset, the HMDB-51 and the UCF-101, depict the effectiveness of the proposed model and its reduced computational burden when compared to traditional energy-based models, such as Restricted Boltzmann Machines and Deep Belief Networks.
ComplexWoundDB: A Database for Automatic Complex Wound Tissue Categorization
Sep 26, 2022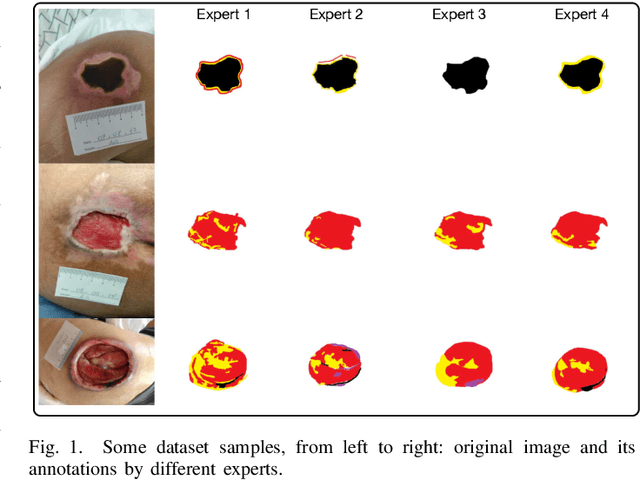
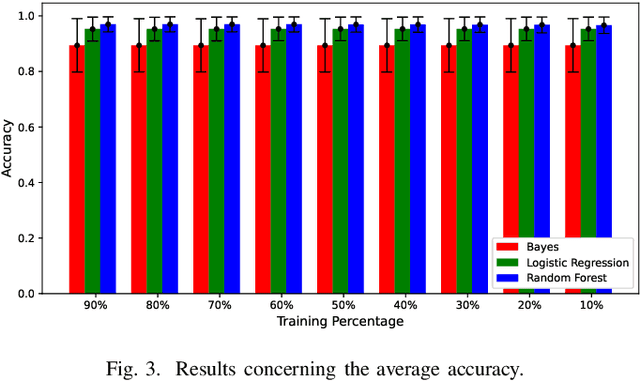
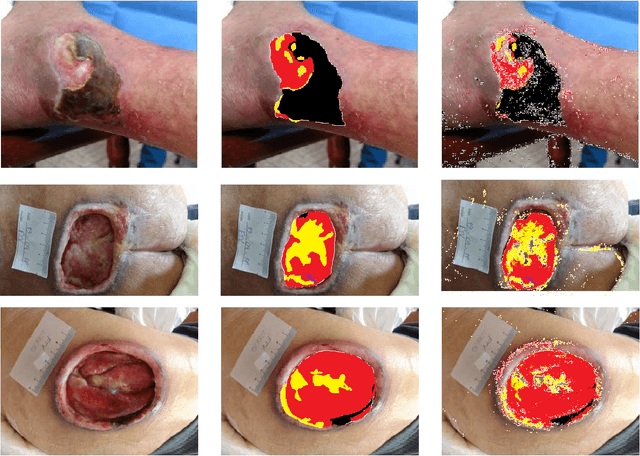
Complex wounds usually face partial or total loss of skin thickness, healing by secondary intention. They can be acute or chronic, figuring infections, ischemia and tissue necrosis, and association with systemic diseases. Research institutes around the globe report countless cases, ending up in a severe public health problem, for they involve human resources (e.g., physicians and health care professionals) and negatively impact life quality. This paper presents a new database for automatically categorizing complex wounds with five categories, i.e., non-wound area, granulation, fibrinoid tissue, and dry necrosis, hematoma. The images comprise different scenarios with complex wounds caused by pressure, vascular ulcers, diabetes, burn, and complications after surgical interventions. The dataset, called ComplexWoundDB, is unique because it figures pixel-level classifications from $27$ images obtained in the wild, i.e., images are collected at the patients' homes, labeled by four health professionals. Further experiments with distinct machine learning techniques evidence the challenges in addressing the problem of computer-aided complex wound tissue categorization. The manuscript sheds light on future directions in the area, with a detailed comparison among other databased widely used in the literature.
A Novel Approach for Optimum-Path Forest Classification Using Fuzzy Logic
Apr 13, 2022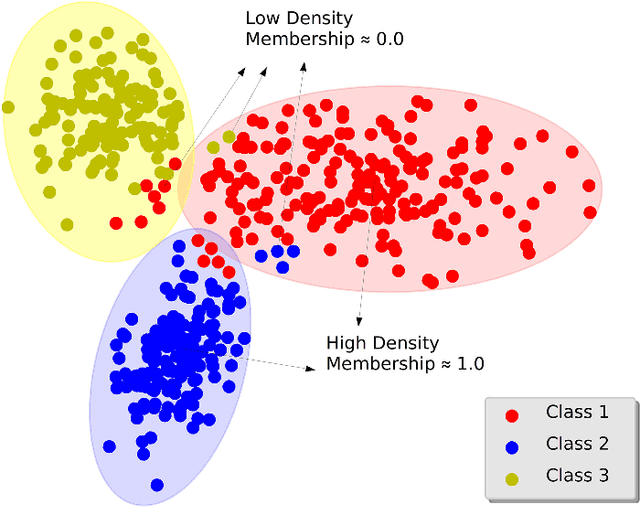
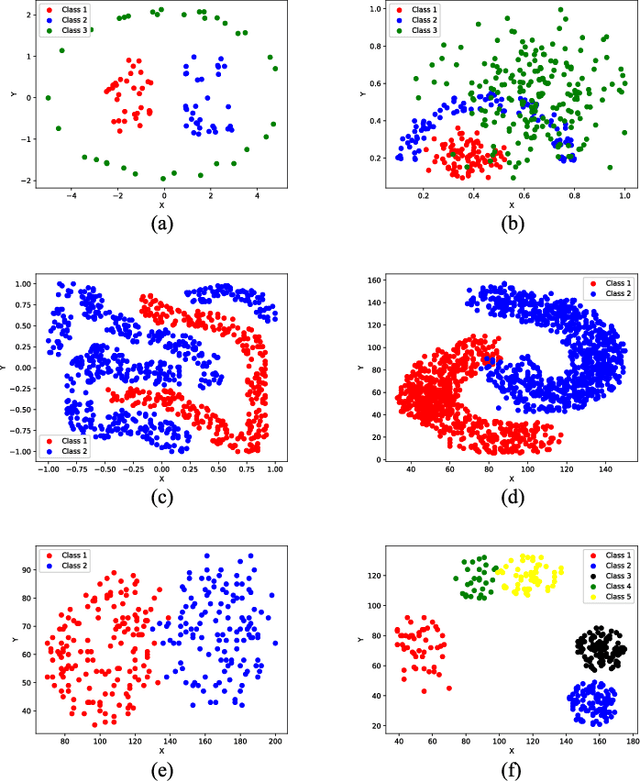

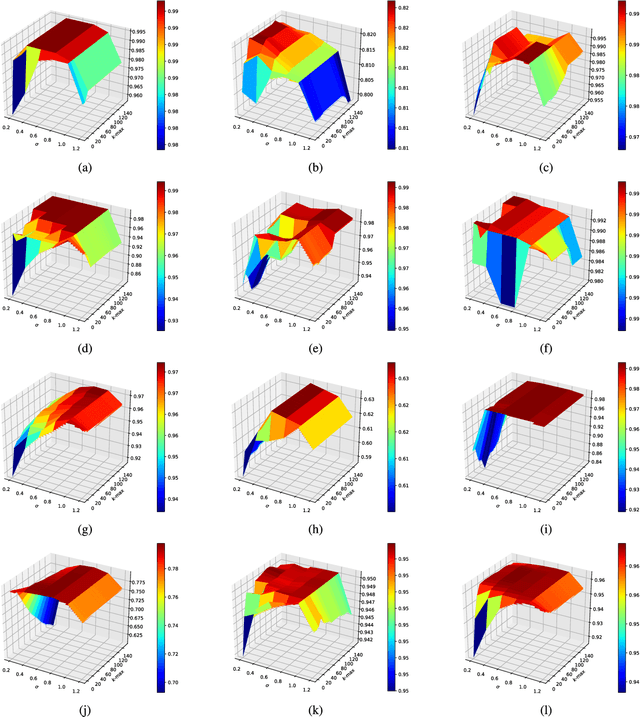
In the past decades, fuzzy logic has played an essential role in many research areas. Alongside, graph-based pattern recognition has shown to be of great importance due to its flexibility in partitioning the feature space using the background from graph theory. Some years ago, a new framework for both supervised, semi-supervised, and unsupervised learning named Optimum-Path Forest (OPF) was proposed with competitive results in several applications, besides comprising a low computational burden. In this paper, we propose the Fuzzy Optimum-Path Forest, an improved version of the standard OPF classifier that learns the samples' membership in an unsupervised fashion, which are further incorporated during supervised training. Such information is used to identify the most relevant training samples, thus improving the classification step. Experiments conducted over twelve public datasets highlight the robustness of the proposed approach, which behaves similarly to standard OPF in worst-case scenarios.
Which Generative Adversarial Network Yields High-Quality Synthetic Medical Images: Investigation Using AMD Image Datasets
Mar 25, 2022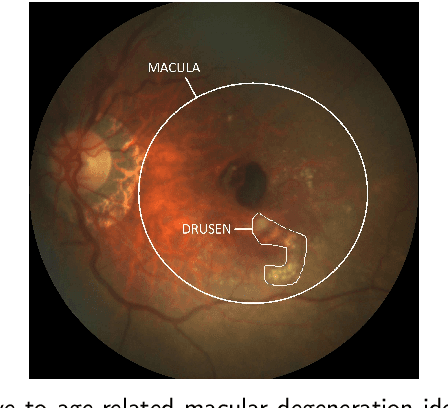
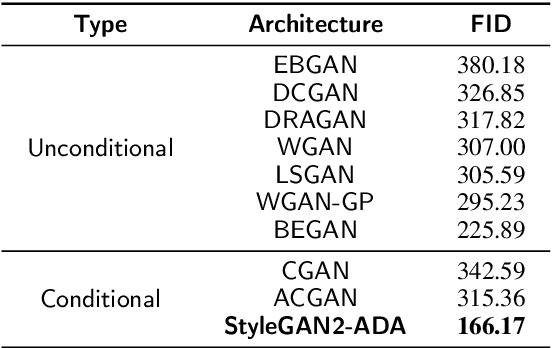

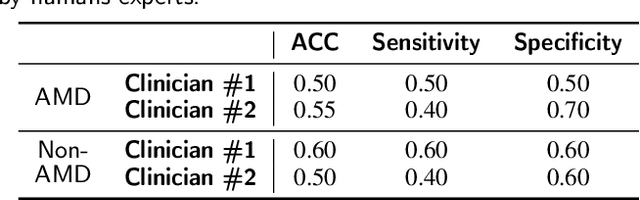
Deep learning has been proposed for the assessment and classification of medical images. However, many medical image databases with appropriately labeled and annotated images are small and imbalanced, and thus unsuitable to train and validate such models. The option is to generate synthetic images and one successful technique has been patented which limits its use for others. We have developed a free-access, alternate method for generating synthetic high-resolution images using Generative Adversarial Networks (GAN) for data augmentation and showed their effectiveness using eye-fundus images for Age-Related Macular Degeneration (AMD) identification. Ten different GAN architectures were compared to generate synthetic eye-fundus images with and without AMD. Data from three public databases were evaluated using the Fr\'echet Inception Distance (FID), two clinical experts and deep-learning classification. The results show that StyleGAN2 reached the lowest FID (166.17), and clinicians could not accurately differentiate between real and synthetic images. ResNet-18 architecture obtained the best performance with 85% accuracy and outperformed the two experts in detecting AMD fundus images, whose average accuracy was 77.5%. These results are similar to a recently patented method, and will provide an alternative to generating high-quality synthetic medical images. Free access has been provided to the entire method to facilitate the further development of this field.
MaxDropoutV2: An Improved Method to Drop out Neurons in Convolutional Neural Networks
Mar 05, 2022
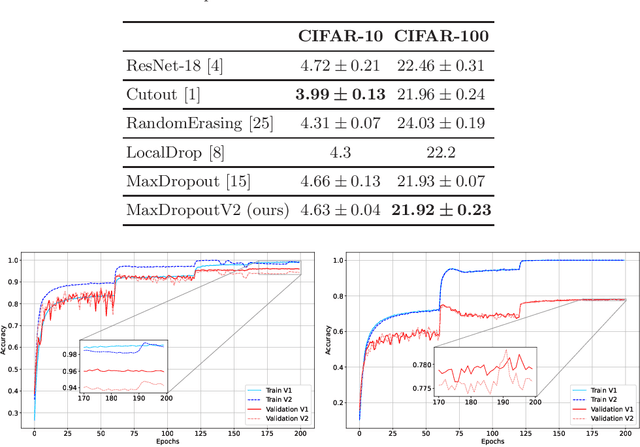
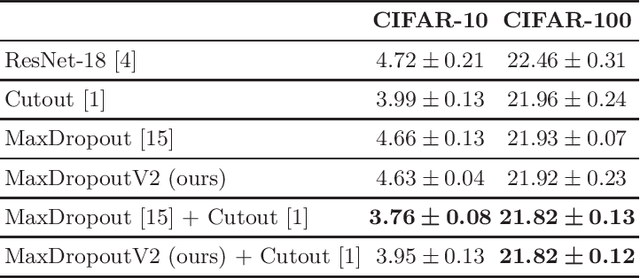

In the last decade, exponential data growth supplied the machine learning-based algorithms' capacity and enabled their usage in daily life activities. Additionally, such an improvement is partially explained due to the advent of deep learning techniques, i.e., stacks of simple architectures that end up in more complex models. Although both factors produce outstanding results, they also pose drawbacks regarding the learning process since training complex models denotes an expensive task and results are prone to overfit the training data. A supervised regularization technique called MaxDropout was recently proposed to tackle the latter, providing several improvements concerning traditional regularization approaches. In this paper, we present its improved version called MaxDropoutV2. Results considering two public datasets show that the model performs faster than the standard version and, in most cases, provides more accurate results.