 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEMa-FS: Finite Element Machines for Feature Selection
Dec 05, 2022



Identifying anomalies has become one of the primary strategies towards security and protection procedures in computer networks. In this context, machine learning-based methods emerge as an elegant solution to identify such scenarios and learn irrelevant information so that a reduction in the identification time and possible gain in accuracy can be obtained. This paper proposes a novel feature selection approach called Finite Element Machines for Feature Selection (FEMa-FS), which uses the framework of finite elements to identify the most relevant information from a given dataset. Although FEMa-FS can be applied to any application domain, it has been evaluated in the context of anomaly detection in computer networks. The outcomes over two datasets showed promising results.
ComplexWoundDB: A Database for Automatic Complex Wound Tissue Categorization
Sep 26, 2022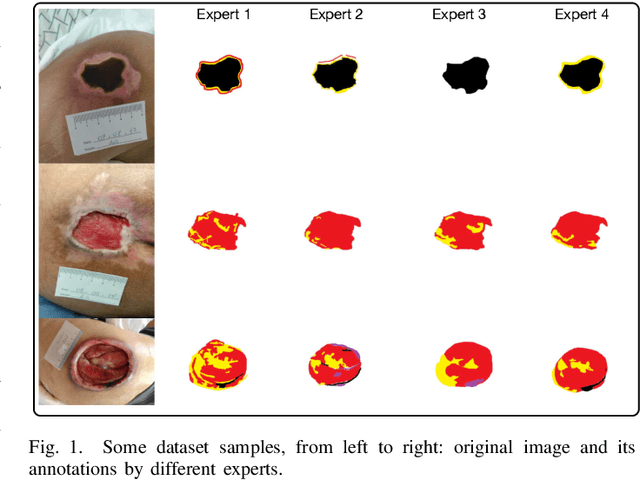
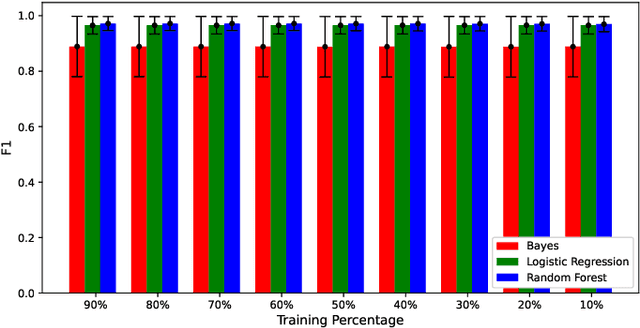
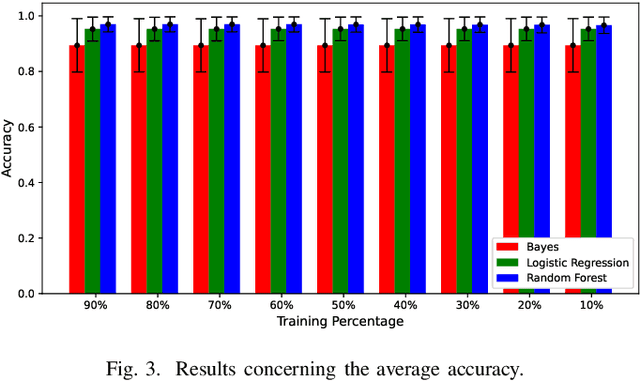
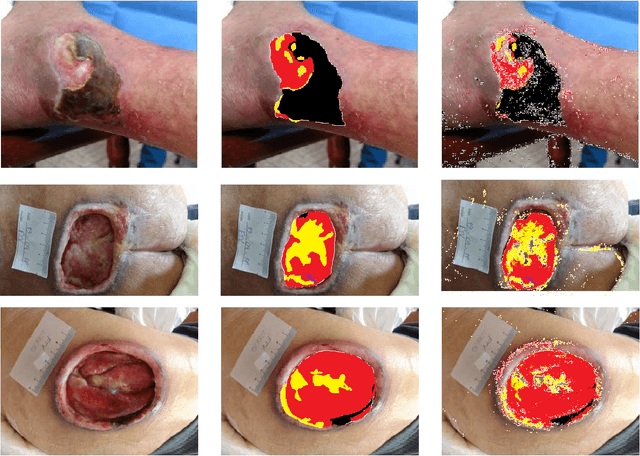
Complex wounds usually face partial or total loss of skin thickness, healing by secondary intention. They can be acute or chronic, figuring infections, ischemia and tissue necrosis, and association with systemic diseases. Research institutes around the globe report countless cases, ending up in a severe public health problem, for they involve human resources (e.g., physicians and health care professionals) and negatively impact life quality. This paper presents a new database for automatically categorizing complex wounds with five categories, i.e., non-wound area, granulation, fibrinoid tissue, and dry necrosis, hematoma. The images comprise different scenarios with complex wounds caused by pressure, vascular ulcers, diabetes, burn, and complications after surgical interventions. The dataset, called ComplexWoundDB, is unique because it figures pixel-level classifications from $27$ images obtained in the wild, i.e., images are collected at the patients' homes, labeled by four health professionals. Further experiments with distinct machine learning techniques evidence the challenges in addressing the problem of computer-aided complex wound tissue categorization. The manuscript sheds light on future directions in the area, with a detailed comparison among other databased widely used in the literature.
A Probabilistic Optimum-Path Forest Classifier for Binary Classification Problems
Sep 04, 2016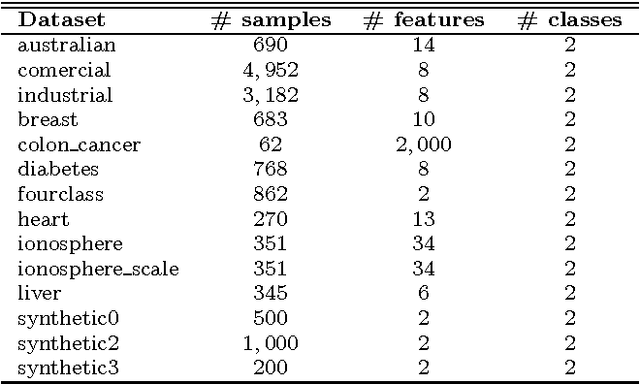
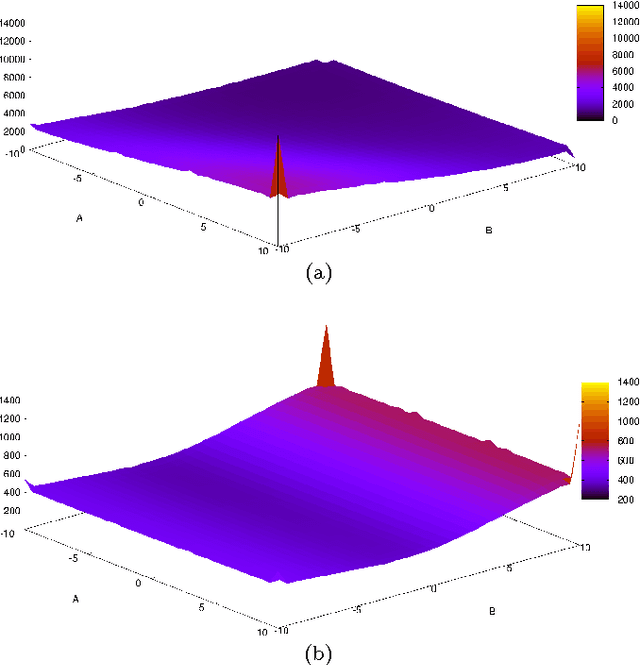
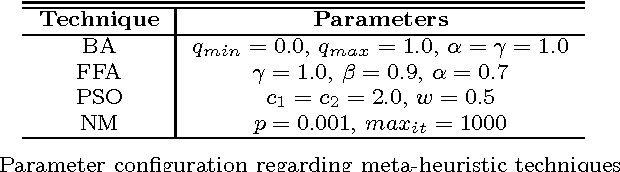
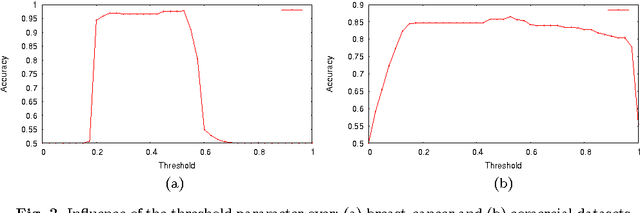
Probabilistic-driven classification techniques extend the role of traditional approaches that output labels (usually integer numbers) only. Such techniques are more fruitful when dealing with problems where one is not interested in recognition/identification only, but also into monitoring the behavior of consumers and/or machines, for instance. Therefore, by means of probability estimates, one can take decisions to work better in a number of scenarios. In this paper, we propose a probabilistic-based Optimum Path Forest (OPF) classifier to handle with binary classification problems, and we show it can be more accurate than naive OPF in a number of datasets. In addition to being just more accurate or not, probabilistic OPF turns to be another useful tool to the scientific community.