 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Artificial Intelligence for Drug Discovery and Development -- A Comprehensive Survey
Sep 21, 2023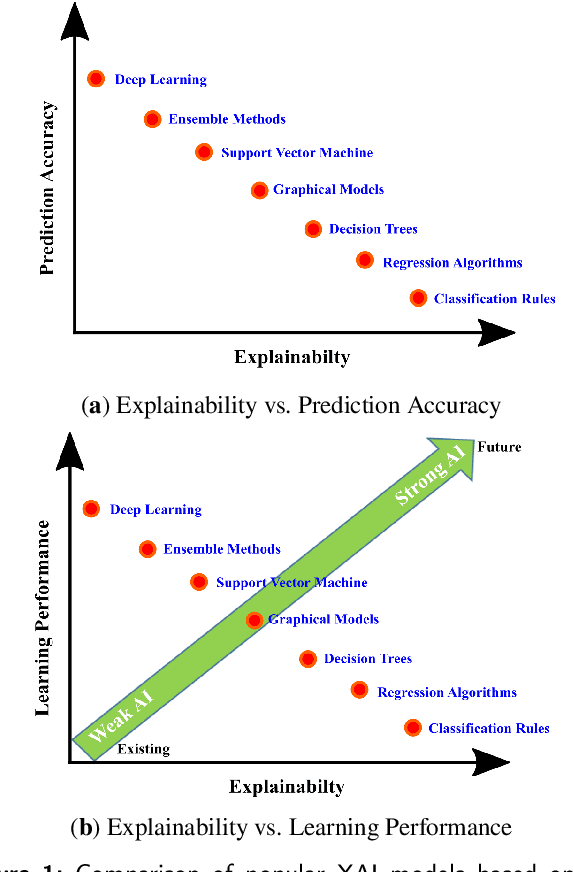
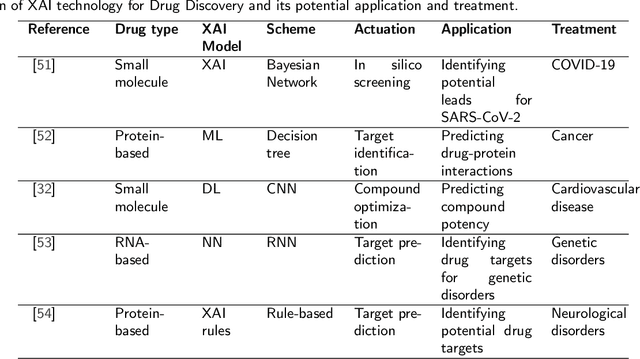
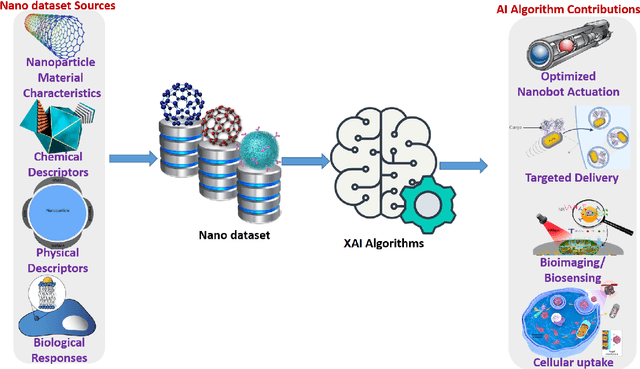
The field of drug discovery has experienced a remarkable transformation with the advent of artificial intelligence (AI) and machine learning (ML) technologies. However, as these AI and ML models are becoming more complex, there is a growing need for transparency and interpretability of the models. Explainable Artificial Intelligence (XAI) is a novel approach that addresses this issue and provides a more interpretable understanding of the predictions made by machine learning models. In recent years, there has been an increasing interest in the application of XAI techniques to drug discovery. This review article provides a comprehensive overview of the current state-of-the-art in XAI for drug discovery, including various XAI methods, their application in drug discovery, and the challenges and limitations of XAI techniques in drug discovery. The article also covers the application of XAI in drug discovery, including target identification, compound design, and toxicity prediction. Furthermore, the article suggests potential future research directions for the application of XAI in drug discovery. The aim of this review article is to provide a comprehensive understanding of the current state of XAI in drug discovery and its potential to transform the field.
A Novel Approach for Optimum-Path Forest Classification Using Fuzzy Logic
Apr 13, 2022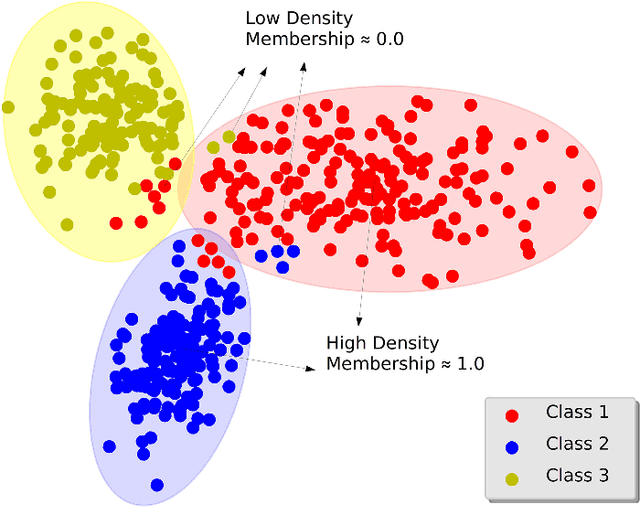
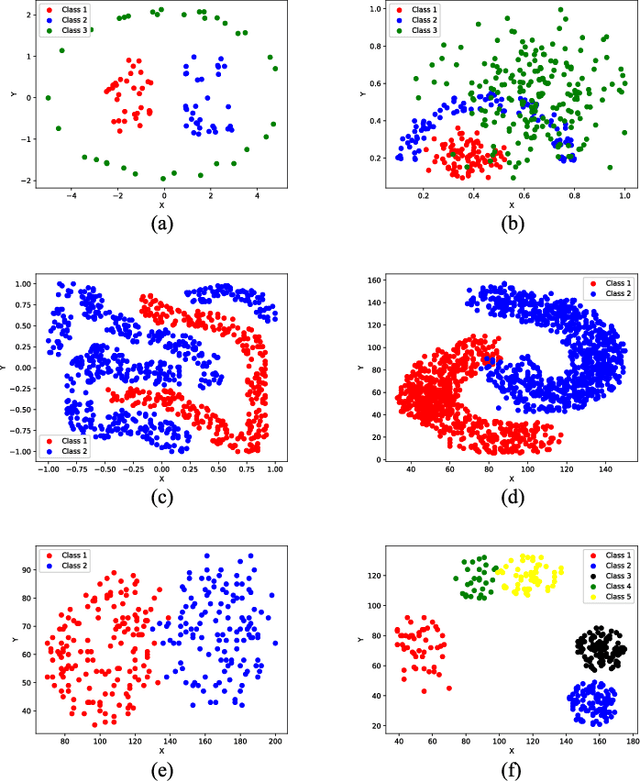

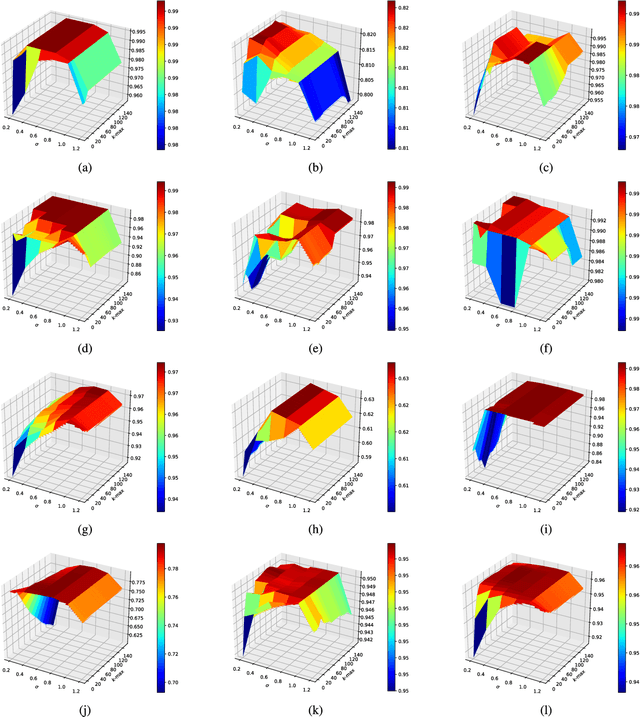
In the past decades, fuzzy logic has played an essential role in many research areas. Alongside, graph-based pattern recognition has shown to be of great importance due to its flexibility in partitioning the feature space using the background from graph theory. Some years ago, a new framework for both supervised, semi-supervised, and unsupervised learning named Optimum-Path Forest (OPF) was proposed with competitive results in several applications, besides comprising a low computational burden. In this paper, we propose the Fuzzy Optimum-Path Forest, an improved version of the standard OPF classifier that learns the samples' membership in an unsupervised fashion, which are further incorporated during supervised training. Such information is used to identify the most relevant training samples, thus improving the classification step. Experiments conducted over twelve public datasets highlight the robustness of the proposed approach, which behaves similarly to standard OPF in worst-case scenarios.
Energy-based Dropout in Restricted Boltzmann Machines: Why not go random
Jan 17, 2021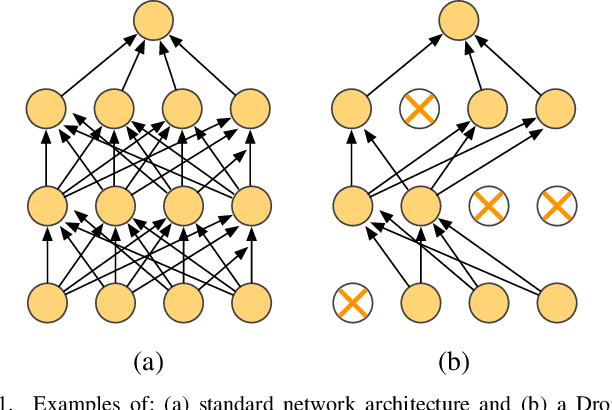
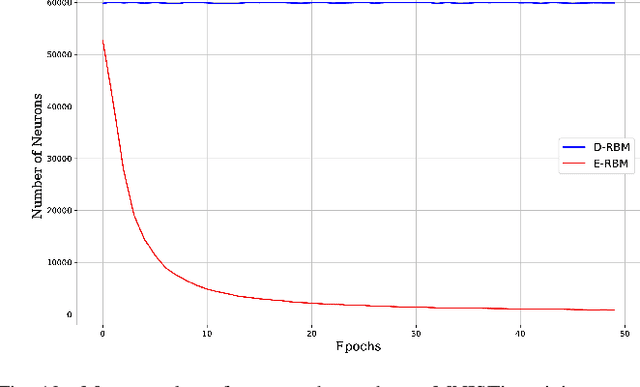
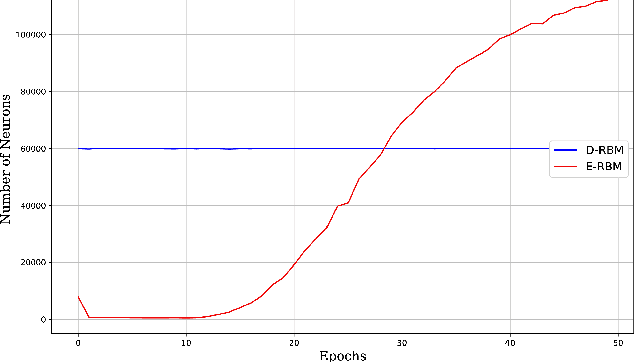
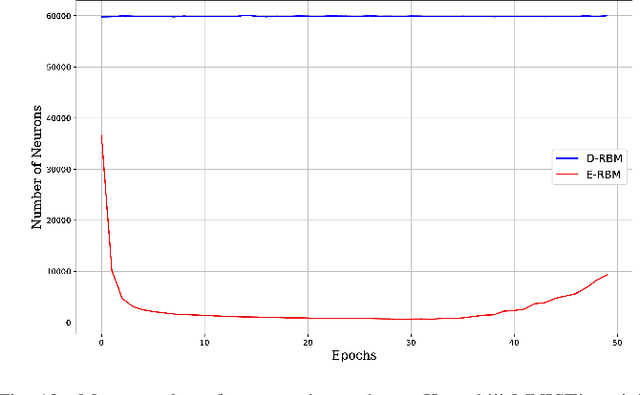
Deep learning architectures have been widely fostered throughout the last years, being used in a wide range of applications, such as object recognition, image reconstruction, and signal processing. Nevertheless, such models suffer from a common problem known as overfitting, which limits the network from predicting unseen data effectively. Regularization approaches arise in an attempt to address such a shortcoming. Among them, one can refer to the well-known Dropout, which tackles the problem by randomly shutting down a set of neurons and their connections according to a certain probability. Therefore, this approach does not consider any additional knowledge to decide which units should be disconnected. In this paper, we propose an energy-based Dropout (E-Dropout) that makes conscious decisions whether a neuron should be dropped or not. Specifically, we design this regularization method by correlating neurons and the model's energy as an importance level for further applying it to energy-based models, such as Restricted Boltzmann Machines (RBMs). The experimental results over several benchmark datasets revealed the proposed approach's suitability compared to the traditional Dropout and the standard RBMs.