 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Hyper-To-Real Space Projections Through Euclidean Norm Meta-Heuristic Optimization
Jan 31, 2023The continuous computational power growth in the last decades has made solving several optimization problems significant to humankind a tractable task; however, tackling some of them remains a challenge due to the overwhelming amount of candidate solutions to be evaluated, even by using sophisticated algorithms. In such a context, a set of nature-inspired stochastic methods, called meta-heuristic optimization, can provide robust approximate solutions to different kinds of problems with a small computational burden, such as derivative-free real function optimization. Nevertheless, these methods may converge to inadequate solutions if the function landscape is too harsh, e.g., enclosing too many local optima. Previous works addressed this issue by employing a hypercomplex representation of the search space, like quaternions, where the landscape becomes smoother and supposedly easier to optimize. Under this approach, meta-heuristic computations happen in the hypercomplex space, whereas variables are mapped back to the real domain before function evaluation. Despite this latter operation being performed by the Euclidean norm, we have found that after the optimization procedure has finished, it is usually possible to obtain even better solutions by employing the Minkowski $p$-norm instead and fine-tuning $p$ through an auxiliary sub-problem with neglecting additional cost and no hyperparameters. Such behavior was observed in eight well-established benchmarking functions, thus fostering a new research direction for hypercomplex meta-heuristic optimization.
Improving Pre-Trained Weights Through Meta-Heuristics Fine-Tuning
Dec 19, 2022



Machine Learning algorithms have been extensively researched throughout the last decade, leading to unprecedented advances in a broad range of applications, such as image classification and reconstruction, object recognition, and text categorization. Nonetheless, most Machine Learning algorithms are trained via derivative-based optimizers, such as the Stochastic Gradient Descent, leading to possible local optimum entrapments and inhibiting them from achieving proper performances. A bio-inspired alternative to traditional optimization techniques, denoted as meta-heuristic, has received significant attention due to its simplicity and ability to avoid local optimums imprisonment. In this work, we propose to use meta-heuristic techniques to fine-tune pre-trained weights, exploring additional regions of the search space, and improving their effectiveness. The experimental evaluation comprises two classification tasks (image and text) and is assessed under four literature datasets. Experimental results show nature-inspired algorithms' capacity in exploring the neighborhood of pre-trained weights, achieving superior results than their counterpart pre-trained architectures. Additionally, a thorough analysis of distinct architectures, such as Multi-Layer Perceptron and Recurrent Neural Networks, attempts to visualize and provide more precise insights into the most critical weights to be fine-tuned in the learning process.
From Actions to Events: A Transfer Learning Approach Using Improved Deep Belief Networks
Nov 30, 2022



In the last decade, exponential data growth supplied machine learning-based algorithms' capacity and enabled their usage in daily-life activities. Additionally, such an improvement is partially explained due to the advent of deep learning techniques, i.e., stacks of simple architectures that end up in more complex models. Although both factors produce outstanding results, they also pose drawbacks regarding the learning process as training complex models over large datasets are expensive and time-consuming. Such a problem is even more evident when dealing with video analysis. Some works have considered transfer learning or domain adaptation, i.e., approaches that map the knowledge from one domain to another, to ease the training burden, yet most of them operate over individual or small blocks of frames. This paper proposes a novel approach to map the knowledge from action recognition to event recognition using an energy-based model, denoted as Spectral Deep Belief Network. Such a model can process all frames simultaneously, carrying spatial and temporal information through the learning process. The experimental results conducted over two public video dataset, the HMDB-51 and the UCF-101, depict the effectiveness of the proposed model and its reduced computational burden when compared to traditional energy-based models, such as Restricted Boltzmann Machines and Deep Belief Networks.
LiteTransformerSearch: Training-free On-device Search for Efficient Autoregressive Language Models
Mar 04, 2022



The transformer architecture is ubiquitously used as the building block of most large-scale language models. However, it remains a painstaking guessing game of trial and error to set its myriad of architectural hyperparameters, e.g., number of layers, number of attention heads, and inner size of the feed forward network, and find architectures with the optimal trade-off between task performance like perplexity and compute constraints like memory and latency. This challenge is further exacerbated by the proliferation of various hardware. In this work, we leverage the somewhat surprising empirical observation that the number of non-embedding parameters in autoregressive transformers has a high rank correlation with task performance, irrespective of the architectural hyperparameters. Since architectural hyperparameters affect the latency and memory footprint in a hardware-dependent manner, the above observation organically induces a simple search algorithm that can be directly run on target devices. We rigorously show that the latency and perplexity pareto-frontier can be found without need for any model training, using non-embedding parameters as a proxy for perplexity. We evaluate our method, dubbed Lightweight Transformer Search (LTS), on diverse devices from ARM CPUs to Nvidia GPUs and show that the perplexity of Transformer-XL can be achieved with up to 2x lower latency. LTS extracts the pareto-frontier in less than 3 hours while running on a commodity laptop. We effectively remove the carbon footprint of training for hundreds of GPU hours, offering a strong simple baseline for future NAS methods in autoregressive language modeling.
Speeding Up OPFython with Numba
Jun 22, 2021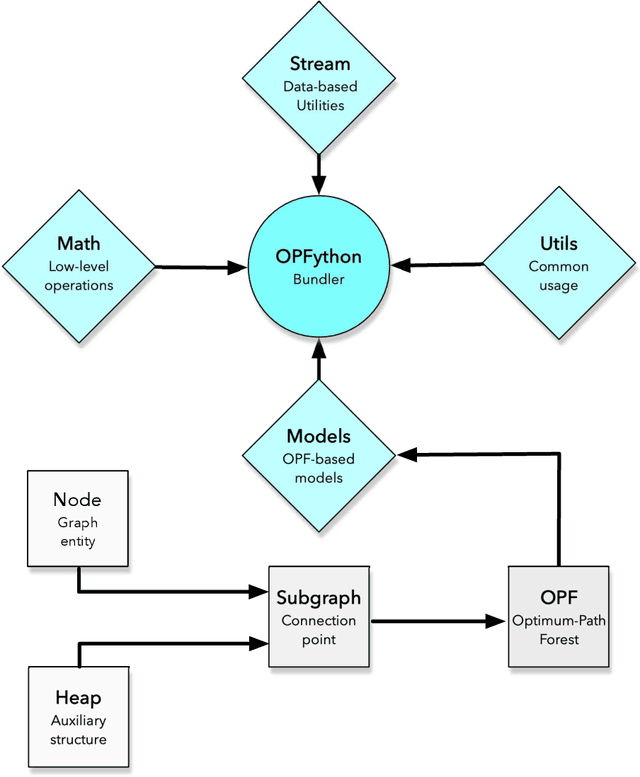
A graph-inspired classifier, known as Optimum-Path Forest (OPF), has proven to be a state-of-the-art algorithm comparable to Logistic Regressors, Support Vector Machines in a wide variety of tasks. Recently, its Python-based version, denoted as OPFython, has been proposed to provide a more friendly framework and a faster prototyping environment. Nevertheless, Python-based algorithms are slower than their counterpart C-based algorithms, impacting their performance when confronted with large amounts of data. Therefore, this paper proposed a simple yet highly efficient speed up using the Numba package, which accelerates Numpy-based calculations and attempts to increase the algorithm's overall performance. Experimental results showed that the proposed approach achieved better results than the na\"ive Python-based OPF and speeded up its distance measurement calculation.
Energy-based Dropout in Restricted Boltzmann Machines: Why not go random
Jan 17, 2021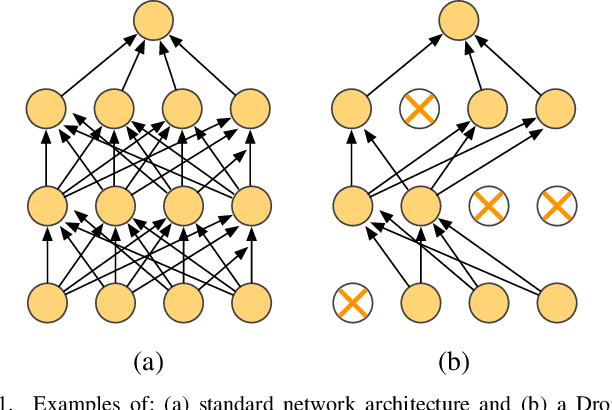
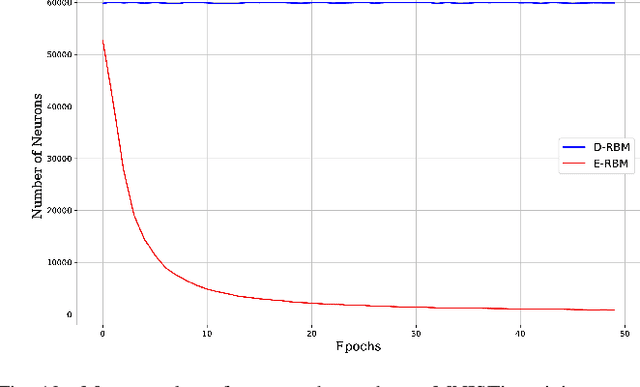
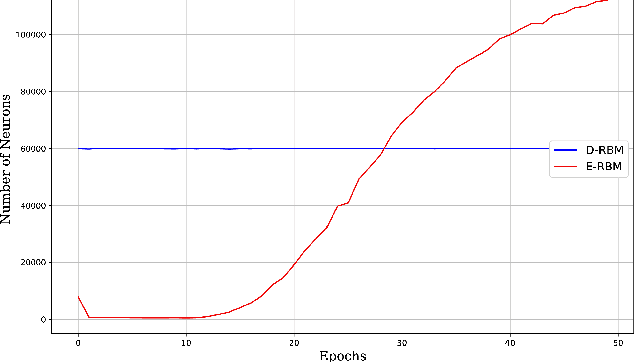
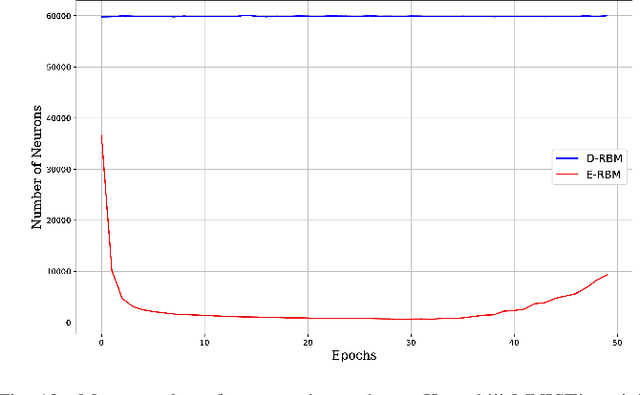
Deep learning architectures have been widely fostered throughout the last years, being used in a wide range of applications, such as object recognition, image reconstruction, and signal processing. Nevertheless, such models suffer from a common problem known as overfitting, which limits the network from predicting unseen data effectively. Regularization approaches arise in an attempt to address such a shortcoming. Among them, one can refer to the well-known Dropout, which tackles the problem by randomly shutting down a set of neurons and their connections according to a certain probability. Therefore, this approach does not consider any additional knowledge to decide which units should be disconnected. In this paper, we propose an energy-based Dropout (E-Dropout) that makes conscious decisions whether a neuron should be dropped or not. Specifically, we design this regularization method by correlating neurons and the model's energy as an importance level for further applying it to energy-based models, such as Restricted Boltzmann Machines (RBMs). The experimental results over several benchmark datasets revealed the proposed approach's suitability compared to the traditional Dropout and the standard RBMs.
A Nature-Inspired Feature Selection Approach based on Hypercomplex Information
Jan 14, 2021
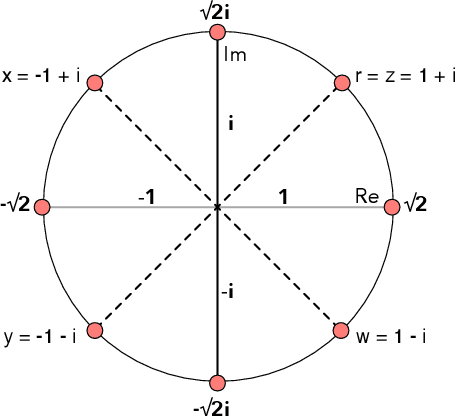

Feature selection for a given model can be transformed into an optimization task. The essential idea behind it is to find the most suitable subset of features according to some criterion. Nature-inspired optimization can mitigate this problem by producing compelling yet straightforward solutions when dealing with complicated fitness functions. Additionally, new mathematical representations, such as quaternions and octonions, are being used to handle higher-dimensional spaces. In this context, we are introducing a meta-heuristic optimization framework in a hypercomplex-based feature selection, where hypercomplex numbers are mapped to real-valued solutions and then transferred onto a boolean hypercube by a sigmoid function. The intended hypercomplex feature selection is tested for several meta-heuristic algorithms and hypercomplex representations, achieving results comparable to some state-of-the-art approaches. The good results achieved by the proposed approach make it a promising tool amongst feature selection research.
* 17 pages, 7 figures
Fast Ensemble Learning Using Adversarially-Generated Restricted Boltzmann Machines
Jan 04, 2021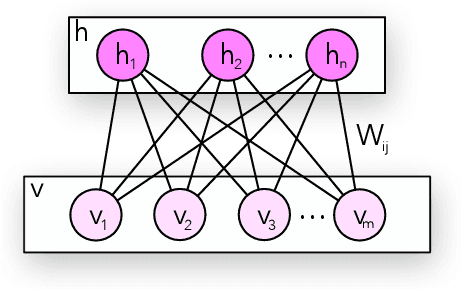
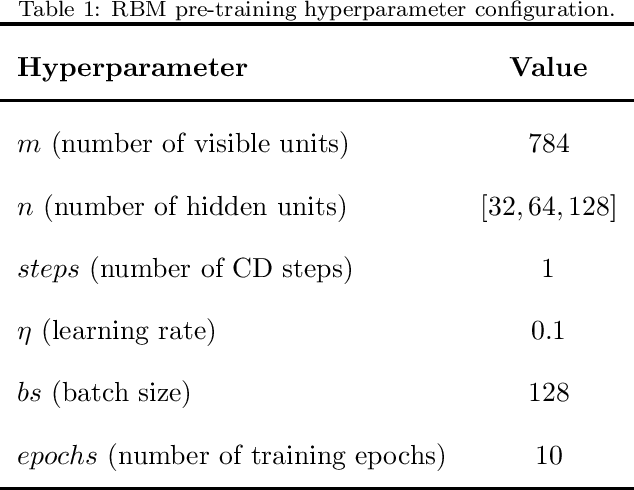
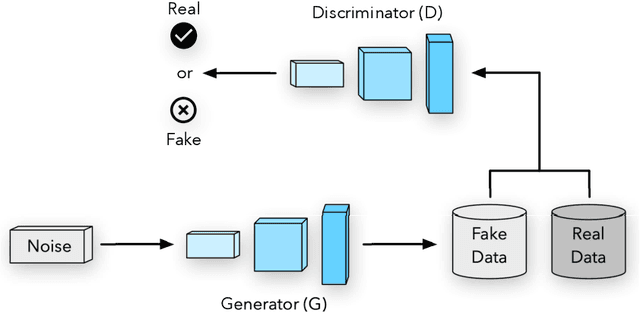
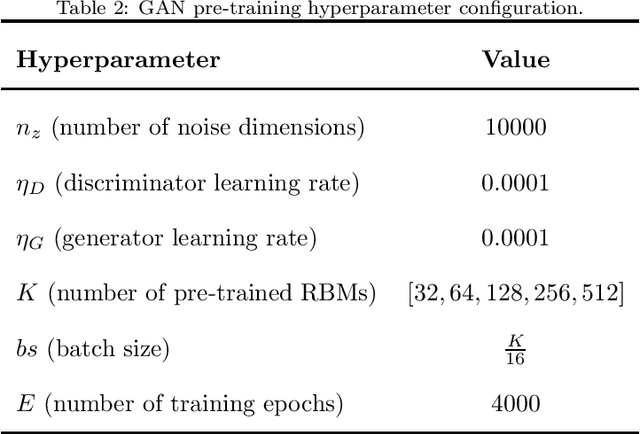
Machine Learning has been applied in a wide range of tasks throughout the last years, ranging from image classification to autonomous driving and natural language processing. Restricted Boltzmann Machine (RBM) has received recent attention and relies on an energy-based structure to model data probability distributions. Notwithstanding, such a technique is susceptible to adversarial manipulation, i.e., slightly or profoundly modified data. An alternative to overcome the adversarial problem lies in the Generative Adversarial Networks (GAN), capable of modeling data distributions and generating adversarial data that resemble the original ones. Therefore, this work proposes to artificially generate RBMs using Adversarial Learning, where pre-trained weight matrices serve as the GAN inputs. Furthermore, it proposes to sample copious amounts of matrices and combine them into ensembles, alleviating the burden of training new models'. Experimental results demonstrate the suitability of the proposed approach under image reconstruction and image classification tasks, and describe how artificial-based ensembles are alternatives to pre-training vast amounts of RBMs.
Opytimizer: A Nature-Inspired Python Optimizer
Dec 30, 2019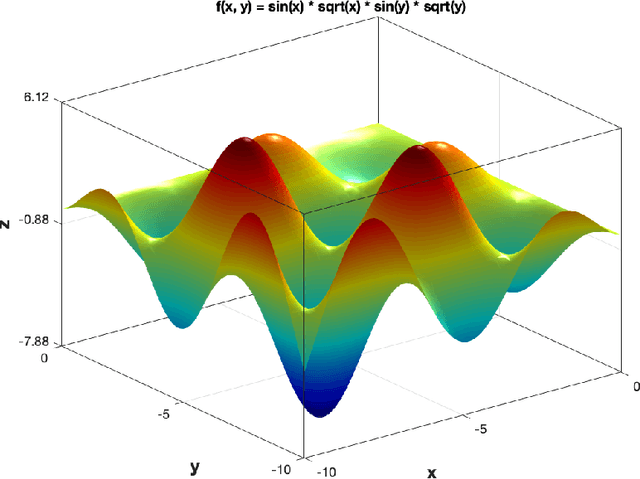
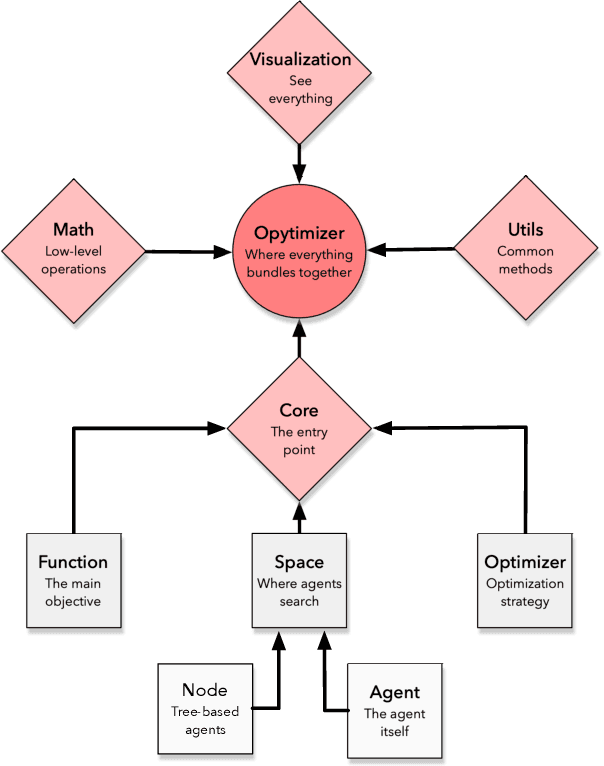
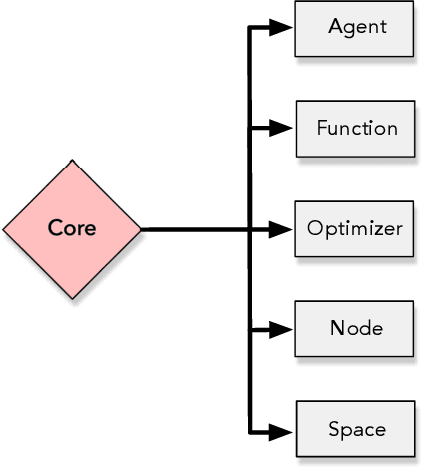
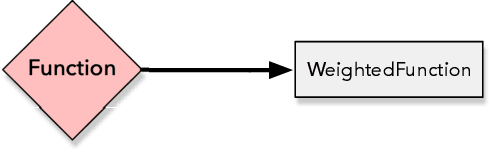
Optimization aims at selecting a feasible set of parameters in an attempt to solve a particular problem, being applied in a wide range of applications, such as operations research, machine learning fine-tuning, and control engineering, among others. Nevertheless, traditional iterative optimization methods use the evaluation of gradients and Hessians to find their solutions, not being practical due to their computational burden and when working with non-convex functions. Recent biological-inspired methods, known as meta-heuristics, have arisen in an attempt to fulfill these problems. Even though they do not guarantee to find optimal solutions, they usually find a suitable solution. In this paper, we proposed a Python-based meta-heuristic optimization framework denoted as Opytimizer. Several methods and classes are implemented to provide a user-friendly workspace among diverse meta-heuristics, ranging from evolutionary- to swarm-based techniques.