 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4 Technical Report
Dec 12, 2024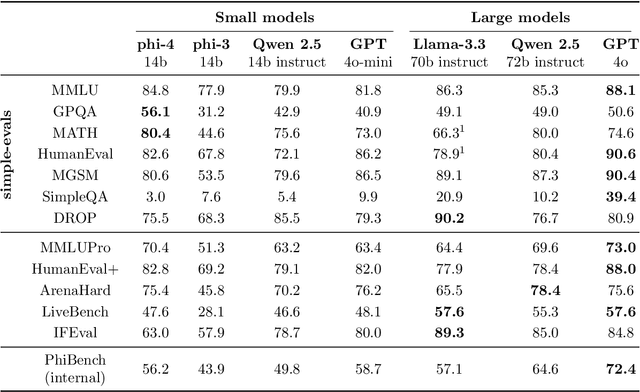
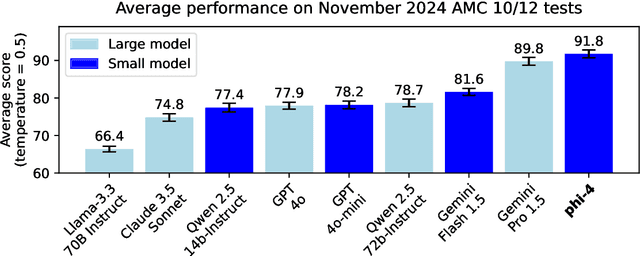

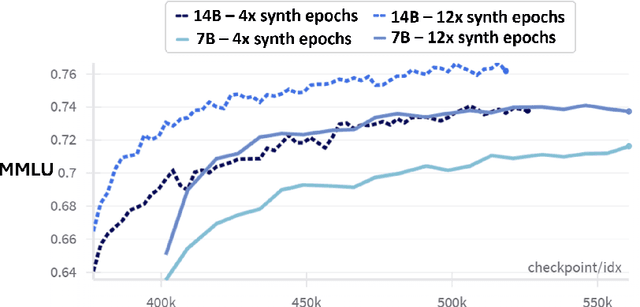
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous models in the Phi family largely distill the capabilities of a teacher model (specifically GPT-4), phi-4 substantially surpasses its teacher model on STEM-focused QA capabilities, giving evidence that our data-generation and post-training techniques go beyond distillation. Despite minimal changes to the phi-3 architecture, phi-4 achieves strong performance relative to its size -- especially on reasoning-focused benchmarks -- due to improved data, training curriculum, and innovations in the post-training scheme.
LiteTransformerSearch: Training-free On-device Search for Efficient Autoregressive Language Models
Mar 04, 2022



The transformer architecture is ubiquitously used as the building block of most large-scale language models. However, it remains a painstaking guessing game of trial and error to set its myriad of architectural hyperparameters, e.g., number of layers, number of attention heads, and inner size of the feed forward network, and find architectures with the optimal trade-off between task performance like perplexity and compute constraints like memory and latency. This challenge is further exacerbated by the proliferation of various hardware. In this work, we leverage the somewhat surprising empirical observation that the number of non-embedding parameters in autoregressive transformers has a high rank correlation with task performance, irrespective of the architectural hyperparameters. Since architectural hyperparameters affect the latency and memory footprint in a hardware-dependent manner, the above observation organically induces a simple search algorithm that can be directly run on target devices. We rigorously show that the latency and perplexity pareto-frontier can be found without need for any model training, using non-embedding parameters as a proxy for perplexity. We evaluate our method, dubbed Lightweight Transformer Search (LTS), on diverse devices from ARM CPUs to Nvidia GPUs and show that the perplexity of Transformer-XL can be achieved with up to 2x lower latency. LTS extracts the pareto-frontier in less than 3 hours while running on a commodity laptop. We effectively remove the carbon footprint of training for hundreds of GPU hours, offering a strong simple baseline for future NAS methods in autoregressive language modeling.