 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgesyftr: Pareto-Optimal Generative AI
May 26, 2025Retrieval-Augmented Generation (RAG) pipelines are central to applying large language models (LLMs) to proprietary or dynamic data. However, building effective RAG flows is complex, requiring careful selection among vector databases, embedding models, text splitters, retrievers, and synthesizing LLMs. The challenge deepens with the rise of agentic paradigms. Modules like verifiers, rewriters, and rerankers-each with intricate hyperparameter dependencies have to be carefully tuned. Balancing tradeoffs between latency, accuracy, and cost becomes increasingly difficult in performance-sensitive applications. We introduce syftr, a framework that performs efficient multi-objective search over a broad space of agentic and non-agentic RAG configurations. Using Bayesian Optimization, syftr discovers Pareto-optimal flows that jointly optimize task accuracy and cost. A novel early-stopping mechanism further improves efficiency by pruning clearly suboptimal candidates. Across multiple RAG benchmarks, syftr finds flows which are on average approximately 9 times cheaper while preserving most of the accuracy of the most accurate flows on the Pareto-frontier. Furthermore, syftr's ability to design and optimize allows integrating new modules, making it even easier and faster to realize high-performing generative AI pipelines.
Neural Architecture Search: Insights from 1000 Papers
Jan 25, 2023



In the past decade, advances in deep learning have resulted in breakthroughs in a variety of areas, including computer vision, natural language understanding, speech recognition, and reinforcement learning. Specialized, high-performing neural architectures are crucial to the success of deep learning in these areas. Neural architecture search (NAS), the process of automating the design of neural architectures for a given task, is an inevitable next step in automating machine learning and has already outpaced the best human-designed architectures on many tasks. In the past few years, research in NAS has been progressing rapidly, with over 1000 papers released since 2020 (Deng and Lindauer, 2021). In this survey, we provide an organized and comprehensive guide to neural architecture search. We give a taxonomy of search spaces, algorithms, and speedup techniques, and we discuss resources such as benchmarks, best practices, other surveys, and open-source libraries.
What Makes Convolutional Models Great on Long Sequence Modeling?
Oct 17, 2022
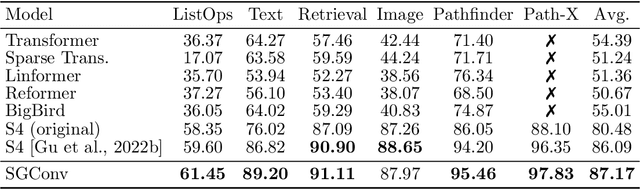
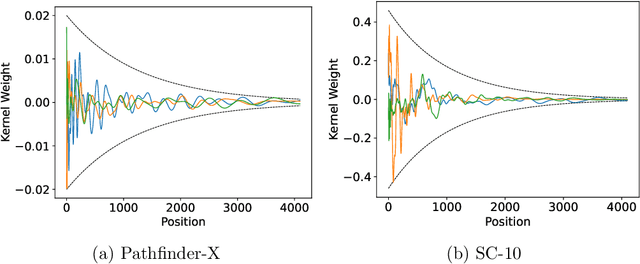
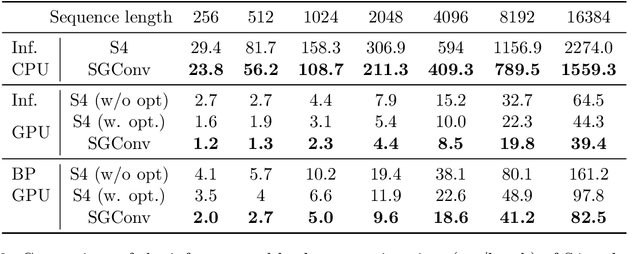
Convolutional models have been widely used in multiple domains. However, most existing models only use local convolution, making the model unable to handle long-range dependency efficiently. Attention overcomes this problem by aggregating global information but also makes the computational complexity quadratic to the sequence length. Recently, Gu et al. [2021] proposed a model called S4 inspired by the state space model. S4 can be efficiently implemented as a global convolutional model whose kernel size equals the input sequence length. S4 can model much longer sequences than Transformers and achieve significant gains over SoTA on several long-range tasks. Despite its empirical success, S4 is involved. It requires sophisticated parameterization and initialization schemes. As a result, S4 is less intuitive and hard to use. Here we aim to demystify S4 and extract basic principles that contribute to the success of S4 as a global convolutional model. We focus on the structure of the convolution kernel and identify two critical but intuitive principles enjoyed by S4 that are sufficient to make up an effective global convolutional model: 1) The parameterization of the convolutional kernel needs to be efficient in the sense that the number of parameters should scale sub-linearly with sequence length. 2) The kernel needs to satisfy a decaying structure that the weights for convolving with closer neighbors are larger than the more distant ones. Based on the two principles, we propose a simple yet effective convolutional model called Structured Global Convolution (SGConv). SGConv exhibits strong empirical performance over several tasks: 1) With faster speed, SGConv surpasses S4 on Long Range Arena and Speech Command datasets. 2) When plugging SGConv into standard language and vision models, it shows the potential to improve both efficiency and performance.
Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints
Oct 06, 2022



Autocomplete is a task where the user inputs a piece of text, termed prompt, which is conditioned by the model to generate semantically coherent continuation. Existing works for this task have primarily focused on datasets (e.g., email, chat) with high frequency user prompt patterns (or focused prompts) where word-based language models have been quite effective. In this work, we study the more challenging setting consisting of low frequency user prompt patterns (or broad prompts, e.g., prompt about 93rd academy awards) and demonstrate the effectiveness of character-based language models. We study this problem under memory-constrained settings (e.g., edge devices and smartphones), where character-based representation is effective in reducing the overall model size (in terms of parameters). We use WikiText-103 benchmark to simulate broad prompts and demonstrate that character models rival word models in exact match accuracy for the autocomplete task, when controlled for the model size. For instance, we show that a 20M parameter character model performs similar to an 80M parameter word model in the vanilla setting. We further propose novel methods to improve character models by incorporating inductive bias in the form of compositional information and representation transfer from large word models.
One Network Doesn't Rule Them All: Moving Beyond Handcrafted Architectures in Self-Supervised Learning
Mar 15, 2022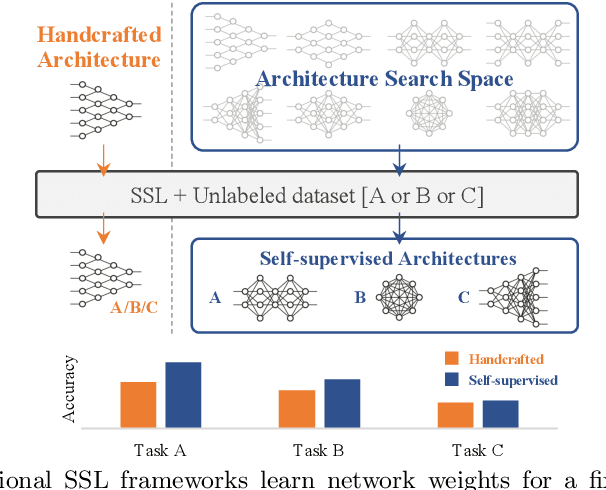
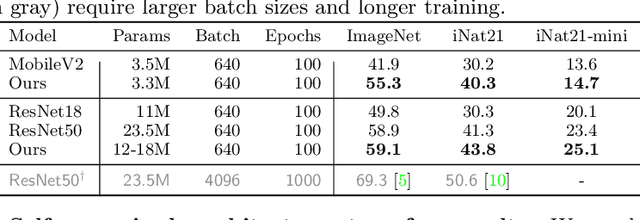
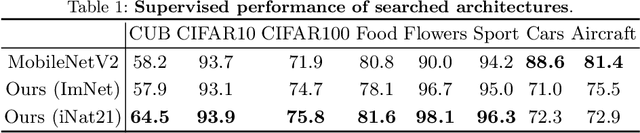
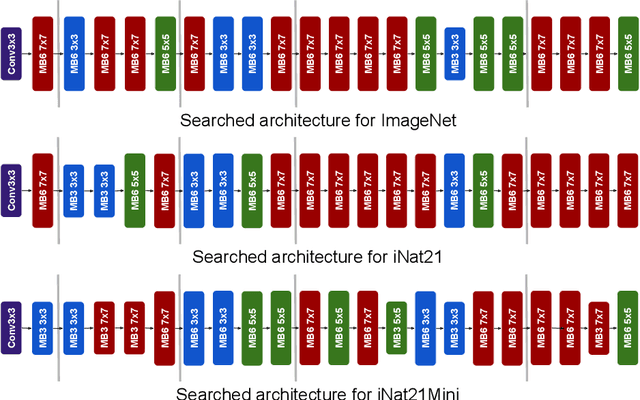
The current literature on self-supervised learning (SSL) focuses on developing learning objectives to train neural networks more effectively on unlabeled data. The typical development process involves taking well-established architectures, e.g., ResNet demonstrated on ImageNet, and using them to evaluate newly developed objectives on downstream scenarios. While convenient, this does not take into account the role of architectures which has been shown to be crucial in the supervised learning literature. In this work, we establish extensive empirical evidence showing that a network architecture plays a significant role in SSL. We conduct a large-scale study with over 100 variants of ResNet and MobileNet architectures and evaluate them across 11 downstream scenarios in the SSL setting. We show that there is no one network that performs consistently well across the scenarios. Based on this, we propose to learn not only network weights but also architecture topologies in the SSL regime. We show that "self-supervised architectures" outperform popular handcrafted architectures (ResNet18 and MobileNetV2) while performing competitively with the larger and computationally heavy ResNet50 on major image classification benchmarks (ImageNet-1K, iNat2021, and more). Our results suggest that it is time to consider moving beyond handcrafted architectures in SSL and start thinking about incorporating architecture search into self-supervised learning objectives.
LiteTransformerSearch: Training-free On-device Search for Efficient Autoregressive Language Models
Mar 04, 2022



The transformer architecture is ubiquitously used as the building block of most large-scale language models. However, it remains a painstaking guessing game of trial and error to set its myriad of architectural hyperparameters, e.g., number of layers, number of attention heads, and inner size of the feed forward network, and find architectures with the optimal trade-off between task performance like perplexity and compute constraints like memory and latency. This challenge is further exacerbated by the proliferation of various hardware. In this work, we leverage the somewhat surprising empirical observation that the number of non-embedding parameters in autoregressive transformers has a high rank correlation with task performance, irrespective of the architectural hyperparameters. Since architectural hyperparameters affect the latency and memory footprint in a hardware-dependent manner, the above observation organically induces a simple search algorithm that can be directly run on target devices. We rigorously show that the latency and perplexity pareto-frontier can be found without need for any model training, using non-embedding parameters as a proxy for perplexity. We evaluate our method, dubbed Lightweight Transformer Search (LTS), on diverse devices from ARM CPUs to Nvidia GPUs and show that the perplexity of Transformer-XL can be achieved with up to 2x lower latency. LTS extracts the pareto-frontier in less than 3 hours while running on a commodity laptop. We effectively remove the carbon footprint of training for hundreds of GPU hours, offering a strong simple baseline for future NAS methods in autoregressive language modeling.
AutoDistil: Few-shot Task-agnostic Neural Architecture Search for Distilling Large Language Models
Jan 29, 2022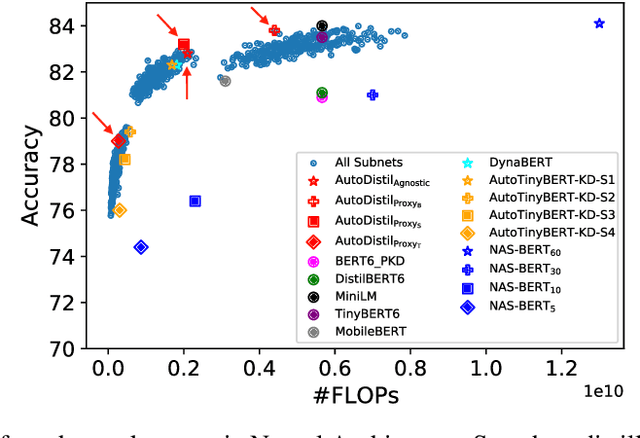
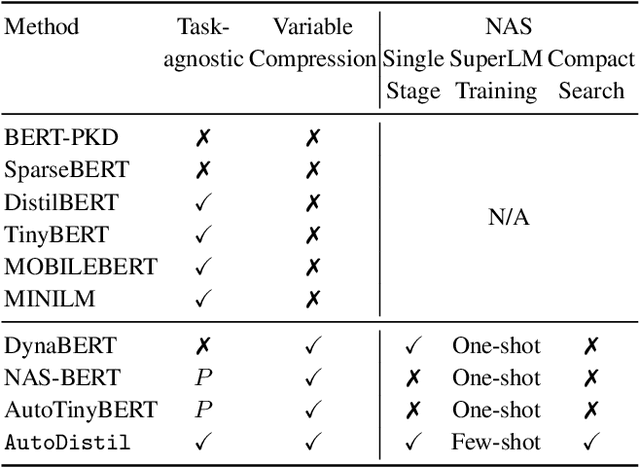
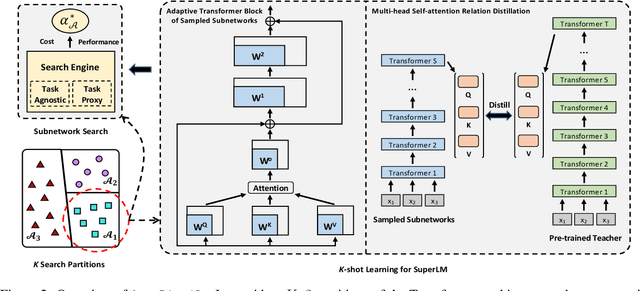

Knowledge distillation (KD) methods compress large models into smaller students with manually-designed student architectures given pre-specified computational cost. This requires several trials to find a viable student, and further repeating the process for each student or computational budget change. We use Neural Architecture Search (NAS) to automatically distill several compressed students with variable cost from a large model. Current works train a single SuperLM consisting of millions of subnetworks with weight-sharing, resulting in interference between subnetworks of different sizes. Our framework AutoDistil addresses above challenges with the following steps: (a) Incorporates inductive bias and heuristics to partition Transformer search space into K compact sub-spaces (K=3 for typical student sizes of base, small and tiny); (b) Trains one SuperLM for each sub-space using task-agnostic objective (e.g., self-attention distillation) with weight-sharing of students; (c) Lightweight search for the optimal student without re-training. Fully task-agnostic training and search allow students to be reused for fine-tuning on any downstream task. Experiments on GLUE benchmark against state-of-the-art KD and NAS methods demonstrate AutoDistil to outperform leading compression techniques with upto 2.7x reduction in computational cost and negligible loss in task performance.
FEAR: A Simple Lightweight Method to Rank Architectures
Jun 07, 2021



The fundamental problem in Neural Architecture Search (NAS) is to efficiently find high-performing architectures from a given search space. We propose a simple but powerful method which we call FEAR, for ranking architectures in any search space. FEAR leverages the viewpoint that neural networks are powerful non-linear feature extractors. First, we train different architectures in the search space to the same training or validation error. Then, we compare the usefulness of the features extracted by each architecture. We do so with a quick training keeping most of the architecture frozen. This gives fast estimates of the relative performance. We validate FEAR on Natsbench topology search space on three different datasets against competing baselines and show strong ranking correlation especially compared to recently proposed zero-cost methods. FEAR particularly excels at ranking high-performance architectures in the search space. When used in the inner loop of discrete search algorithms like random search, FEAR can cut down the search time by approximately 2.4X without losing accuracy. We additionally empirically study very recently proposed zero-cost measures for ranking and find that they breakdown in ranking performance as training proceeds and also that data-agnostic ranking scores which ignore the dataset do not generalize across dissimilar datasets.
Reparameterized Variational Divergence Minimization for Stable Imitation
Jun 18, 2020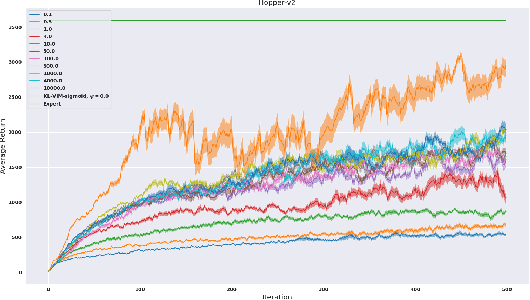

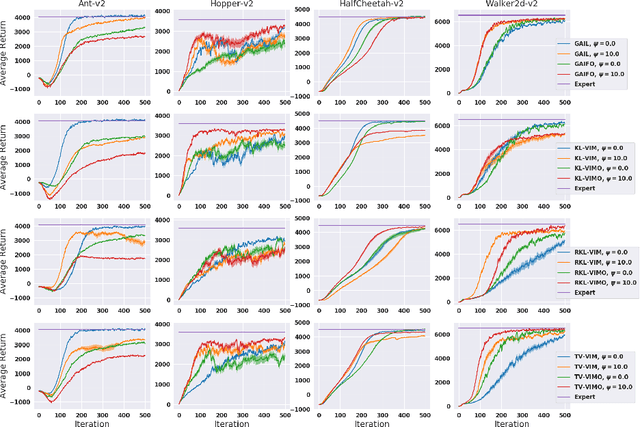
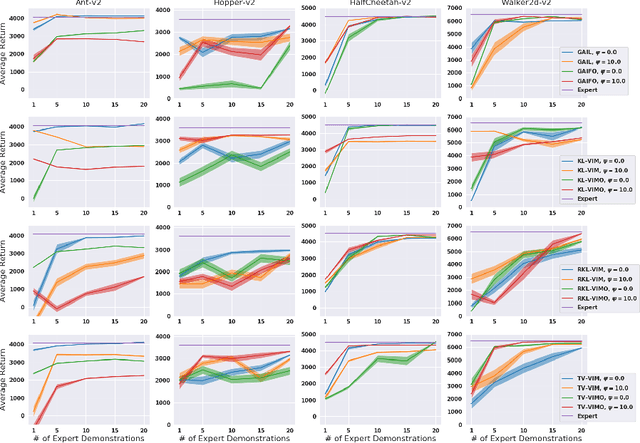
While recent state-of-the-art results for adversarial imitation-learning algorithms are encouraging, recent works exploring the imitation learning from observation (ILO) setting, where trajectories \textit{only} contain expert observations, have not been met with the same success. Inspired by recent investigations of $f$-divergence manipulation for the standard imitation learning setting(Ke et al., 2019; Ghasemipour et al., 2019), we here examine the extent to which variations in the choice of probabilistic divergence may yield more performant ILO algorithms. We unfortunately find that $f$-divergence minimization through reinforcement learning is susceptible to numerical instabilities. We contribute a reparameterization trick for adversarial imitation learning to alleviate the optimization challenges of the promising $f$-divergence minimization framework. Empirically, we demonstrate that our design choices allow for ILO algorithms that outperform baseline approaches and more closely match expert performance in low-dimensional continuous-control tasks.
A Recipe for Creating Multimodal Aligned Datasets for Sequential Tasks
May 19, 2020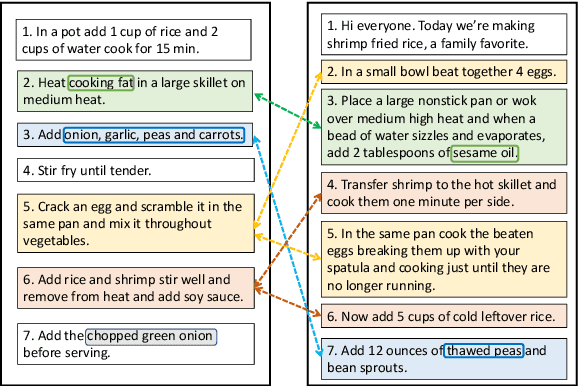
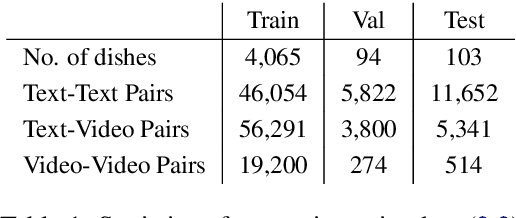
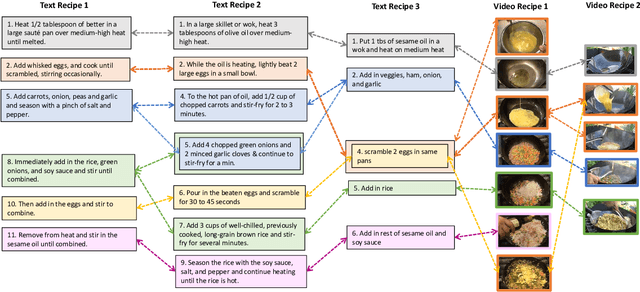
Many high-level procedural tasks can be decomposed into sequences of instructions that vary in their order and choice of tools. In the cooking domain, the web offers many partially-overlapping text and video recipes (i.e. procedures) that describe how to make the same dish (i.e. high-level task). Aligning instructions for the same dish across different sources can yield descriptive visual explanations that are far richer semantically than conventional textual instructions, providing commonsense insight into how real-world procedures are structured. Learning to align these different instruction sets is challenging because: a) different recipes vary in their order of instructions and use of ingredients; and b) video instructions can be noisy and tend to contain far more information than text instructions. To address these challenges, we first use an unsupervised alignment algorithm that learns pairwise alignments between instructions of different recipes for the same dish. We then use a graph algorithm to derive a joint alignment between multiple text and multiple video recipes for the same dish. We release the Microsoft Research Multimodal Aligned Recipe Corpus containing 150K pairwise alignments between recipes across 4,262 dishes with rich commonsense information.
* This paper has been accepted to be published at ACL 2020