 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Long-Form Medical Question Answering
Nov 14, 2024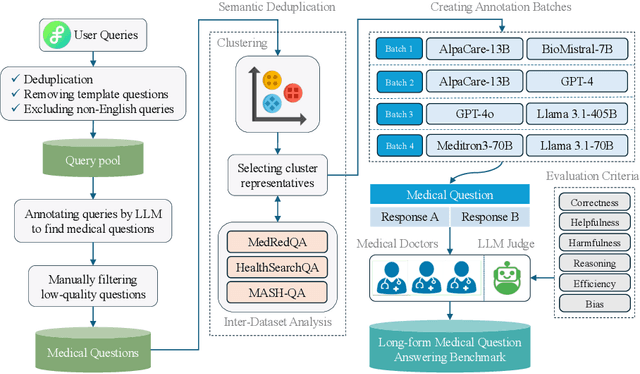

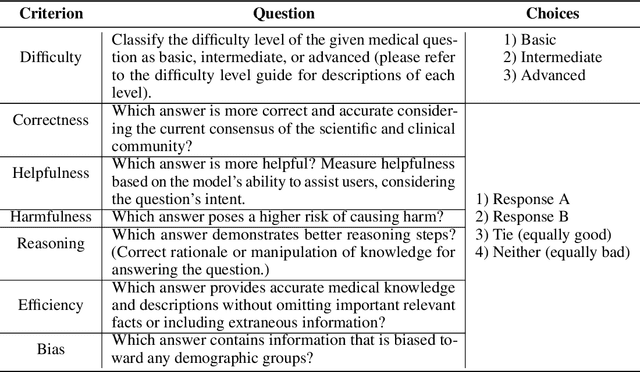
There is a lack of benchmarks for evaluating large language models (LLMs) in long-form medical question answering (QA). Most existing medical QA evaluation benchmarks focus on automatic metrics and multiple-choice questions. While valuable, these benchmarks fail to fully capture or assess the complexities of real-world clinical applications where LLMs are being deployed. Furthermore, existing studies on evaluating long-form answer generation in medical QA are primarily closed-source, lacking access to human medical expert annotations, which makes it difficult to reproduce results and enhance existing baselines. In this work, we introduce a new publicly available benchmark featuring real-world consumer medical questions with long-form answer evaluations annotated by medical doctors. We performed pairwise comparisons of responses from various open and closed-source medical and general-purpose LLMs based on criteria such as correctness, helpfulness, harmfulness, and bias. Additionally, we performed a comprehensive LLM-as-a-judge analysis to study the alignment between human judgments and LLMs. Our preliminary results highlight the strong potential of open LLMs in medical QA compared to leading closed models. Code & Data: https://github.com/lavita-ai/medical-eval-sphere
HetTree: Heterogeneous Tree Graph Neural Network
Feb 21, 2024



The recent past has seen an increasing interest in Heterogeneous Graph Neural Networks (HGNNs) since many real-world graphs are heterogeneous in nature, from citation graphs to email graphs. However, existing methods ignore a tree hierarchy among metapaths, which is naturally constituted by different node types and relation types. In this paper, we present HetTree, a novel heterogeneous tree graph neural network that models both the graph structure and heterogeneous aspects in a scalable and effective manner. Specifically, HetTree builds a semantic tree data structure to capture the hierarchy among metapaths. Existing tree encoding techniques aggregate children nodes by weighting the contribution of children nodes based on similarity to the parent node. However, we find that this tree encoding fails to capture the entire parent-children hierarchy by only considering the parent node. Hence, HetTree uses a novel subtree attention mechanism to emphasize metapaths that are more helpful in encoding parent-children relationships. Moreover, instead of separating feature learning from label learning or treating features and labels equally by projecting them to the same latent space, HetTree proposes to match them carefully based on corresponding metapaths, which provides more accurate and richer information between node features and labels. Our evaluation of HetTree on a variety of real-world datasets demonstrates that it outperforms all existing baselines on open benchmarks and efficiently scales to large real-world graphs with millions of nodes and edges.
Solving Data-centric Tasks using Large Language Models
Feb 18, 2024
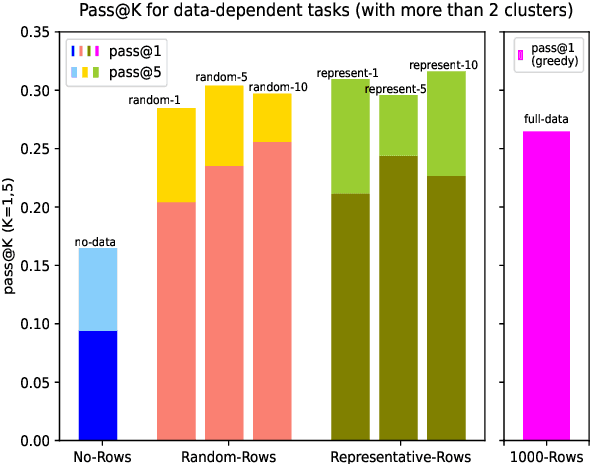
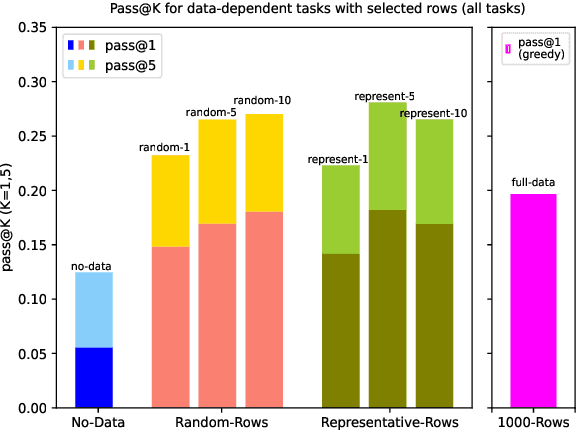
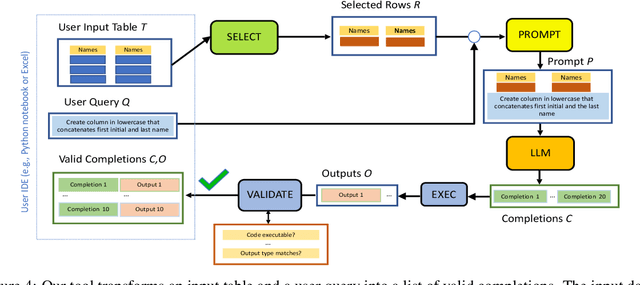
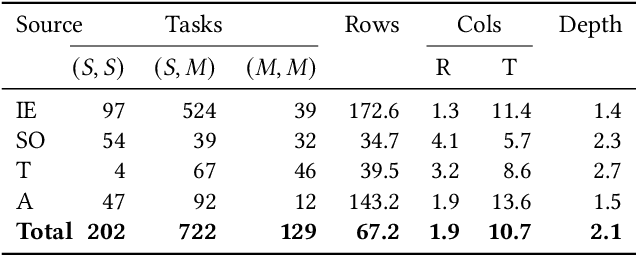
Large language models (LLMs) are rapidly replacing help forums like StackOverflow, and are especially helpful for non-professional programmers and end users. These users are often interested in data-centric tasks, such as spreadsheet manipulation and data wrangling, which are hard to solve if the intent is only communicated using a natural-language description, without including the data. But how do we decide how much data and which data to include in the prompt? This paper makes two contributions towards answering this question. First, we create a dataset of real-world NL-to-code tasks manipulating tabular data, mined from StackOverflow posts. Second, we introduce a cluster-then-select prompting technique, which adds the most representative rows from the input data to the LLM prompt. Our experiments show that LLM performance is indeed sensitive to the amount of data passed in the prompt, and that for tasks with a lot of syntactic variation in the input table, our cluster-then-select technique outperforms a random selection baseline.
FormaT5: Abstention and Examples for Conditional Table Formatting with Natural Language
Nov 01, 2023

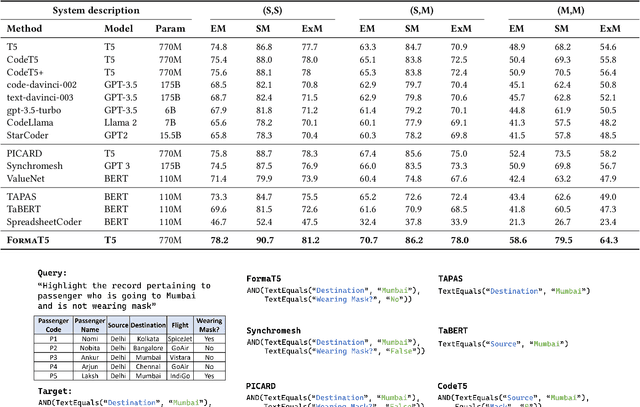
Formatting is an important property in tables for visualization, presentation, and analysis. Spreadsheet software allows users to automatically format their tables by writing data-dependent conditional formatting (CF) rules. Writing such rules is often challenging for users as it requires them to understand and implement the underlying logic. We present FormaT5, a transformer-based model that can generate a CF rule given the target table and a natural language description of the desired formatting logic. We find that user descriptions for these tasks are often under-specified or ambiguous, making it harder for code generation systems to accurately learn the desired rule in a single step. To tackle this problem of under-specification and minimise argument errors, FormaT5 learns to predict placeholders though an abstention objective. These placeholders can then be filled by a second model or, when examples of rows that should be formatted are available, by a programming-by-example system. To evaluate FormaT5 on diverse and real scenarios, we create an extensive benchmark of 1053 CF tasks, containing real-world descriptions collected from four different sources. We release our benchmarks to encourage research in this area. Abstention and filling allow FormaT5 to outperform 8 different neural approaches on our benchmarks, both with and without examples. Our results illustrate the value of building domain-specific learning systems.
InstructExcel: A Benchmark for Natural Language Instruction in Excel
Oct 23, 2023With the evolution of Large Language Models (LLMs) we can solve increasingly more complex NLP tasks across various domains, including spreadsheets. This work investigates whether LLMs can generate code (Excel OfficeScripts, a TypeScript API for executing many tasks in Excel) that solves Excel specific tasks provided via natural language user instructions. To do so we introduce a new large-scale benchmark, InstructExcel, created by leveraging the 'Automate' feature in Excel to automatically generate OfficeScripts from users' actions. Our benchmark includes over 10k samples covering 170+ Excel operations across 2,000 publicly available Excel spreadsheets. Experiments across various zero-shot and few-shot settings show that InstructExcel is a hard benchmark for state of the art models like GPT-4. We observe that (1) using GPT-4 over GPT-3.5, (2) providing more in-context examples, and (3) dynamic prompting can help improve performance on this benchmark.
Learning with Few Labeled Nodes via Augmented Graph Self-Training
Aug 26, 2022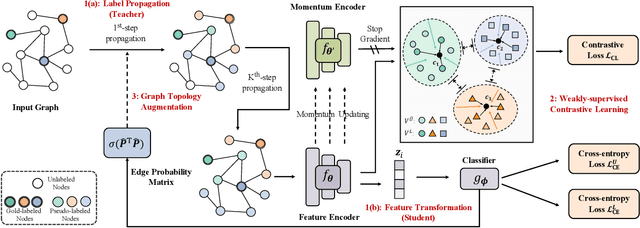
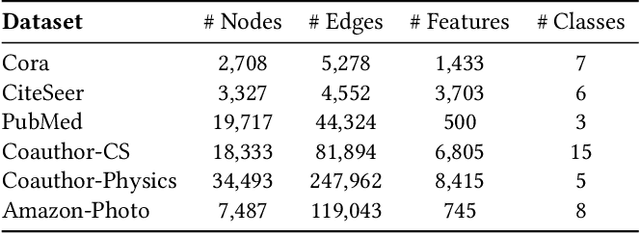
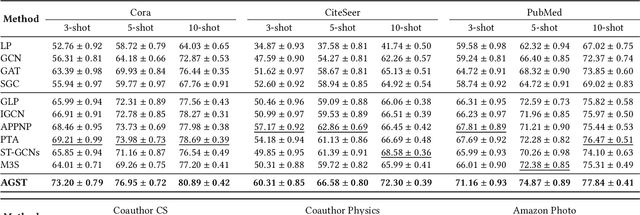
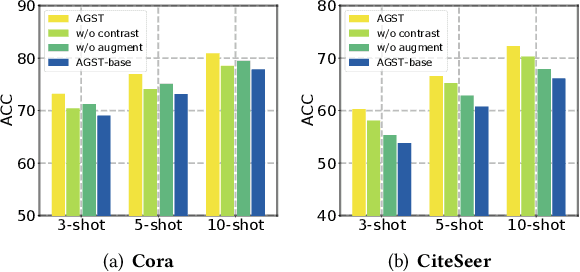
It is well known that the success of graph neural networks (GNNs) highly relies on abundant human-annotated data, which is laborious to obtain and not always available in practice. When only few labeled nodes are available, how to develop highly effective GNNs remains understudied. Though self-training has been shown to be powerful for semi-supervised learning, its application on graph-structured data may fail because (1) larger receptive fields are not leveraged to capture long-range node interactions, which exacerbates the difficulty of propagating feature-label patterns from labeled nodes to unlabeled nodes; and (2) limited labeled data makes it challenging to learn well-separated decision boundaries for different node classes without explicitly capturing the underlying semantic structure. To address the challenges of capturing informative structural and semantic knowledge, we propose a new graph data augmentation framework, AGST (Augmented Graph Self-Training), which is built with two new (i.e., structural and semantic) augmentation modules on top of a decoupled GST backbone. In this work, we investigate whether this novel framework can learn an effective graph predictive model with extremely limited labeled nodes. We conduct comprehensive evaluations on semi-supervised node classification under different scenarios of limited labeled-node data. The experimental results demonstrate the unique contributions of the novel data augmentation framework for node classification with few labeled data.
HELP ME THINK: A Simple Prompting Strategy for Non-experts to Create Customized Content with Models
Aug 17, 2022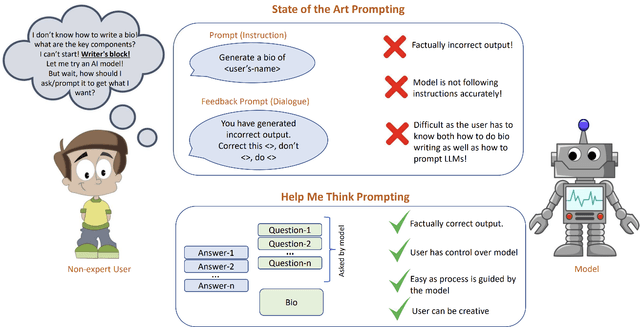
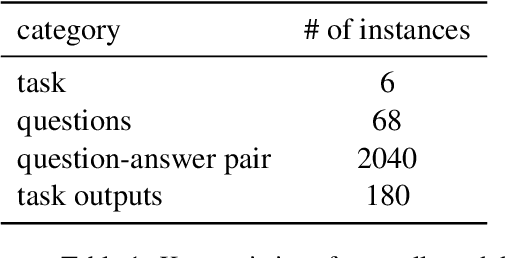

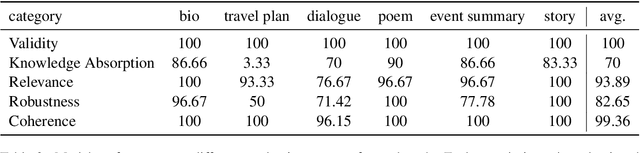
Controlling the text generated by language models and customizing the content has been a long-standing challenge. Existing prompting techniques proposed in pursuit of providing control are task-specific and lack generality; this provides overwhelming choices for non-expert users to find a suitable method for their task. The effort associated with those techniques, such as in writing examples, explanations, instructions, etc. further limits their adoption among non-expert users. In this paper, we propose a simple prompting strategy HELP ME THINK where we encourage GPT3 to help non-expert users by asking a set of relevant questions and leveraging user answers to execute the task. We demonstrate the efficacy of our technique HELP ME THINK on a variety of tasks. Specifically, we focus on tasks that are hard for average humans and require significant thinking to perform. We hope our work will encourage the development of unconventional ways to harness the power of large language models.
GODEL: Large-Scale Pre-Training for Goal-Directed Dialog
Jun 22, 2022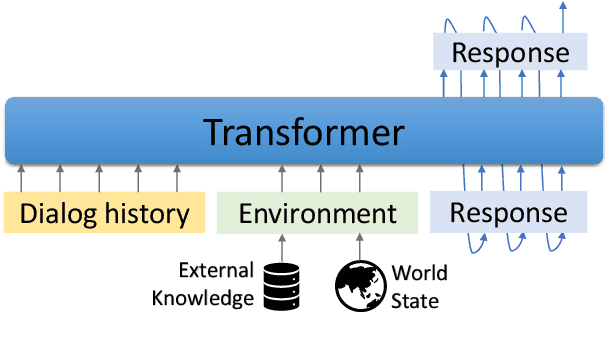
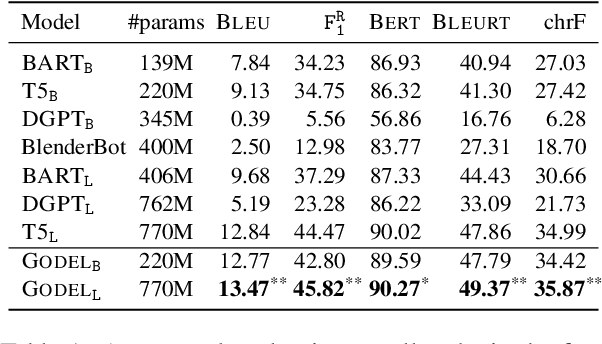

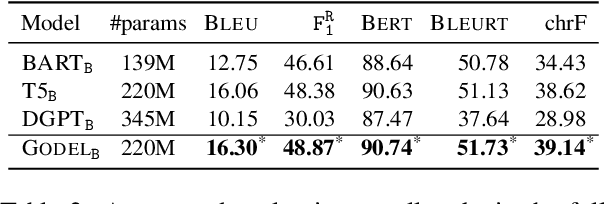
We introduce GODEL (Grounded Open Dialogue Language Model), a large pre-trained language model for dialog. In contrast with earlier models such as DialoGPT, GODEL leverages a new phase of grounded pre-training designed to better support adapting GODEL to a wide range of downstream dialog tasks that require information external to the current conversation (e.g., a database or document) to produce good responses. Experiments against an array of benchmarks that encompass task-oriented dialog, conversational QA, and grounded open-domain dialog show that GODEL outperforms state-of-the-art pre-trained dialog models in few-shot fine-tuning setups, in terms of both human and automatic evaluation. A novel feature of our evaluation methodology is the introduction of a notion of utility that assesses the usefulness of responses (extrinsic evaluation) in addition to their communicative features (intrinsic evaluation). We show that extrinsic evaluation offers improved inter-annotator agreement and correlation with automated metrics. Code and data processing scripts are publicly available.
Reinforcement Guided Multi-Task Learning Framework for Low-Resource Stereotype Detection
Mar 27, 2022
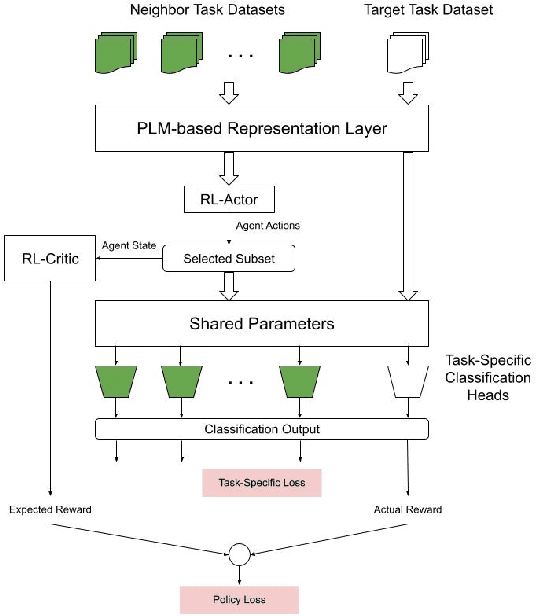

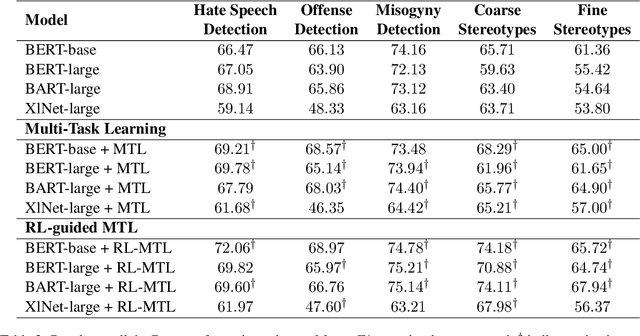
As large Pre-trained Language Models (PLMs) trained on large amounts of data in an unsupervised manner become more ubiquitous, identifying various types of bias in the text has come into sharp focus. Existing "Stereotype Detection" datasets mainly adopt a diagnostic approach toward large PLMs. Blodgett et. al (2021a) show that there are significant reliability issues with the existing benchmark datasets. Annotating a reliable dataset requires a precise understanding of the subtle nuances of how stereotypes manifest in text. In this paper, we annotate a focused evaluation set for "Stereotype Detection" that addresses those pitfalls by de-constructing various ways in which stereotypes manifest in text. Further, we present a multi-task model that leverages the abundance of data-rich neighboring tasks such as hate speech detection, offensive language detection, misogyny detection, etc., to improve the empirical performance on "Stereotype Detection". We then propose a reinforcement-learning agent that guides the multi-task learning model by learning to identify the training examples from the neighboring tasks that help the target task the most. We show that the proposed models achieve significant empirical gains over existing baselines on all the tasks.
Reparameterized Variational Divergence Minimization for Stable Imitation
Jun 18, 2020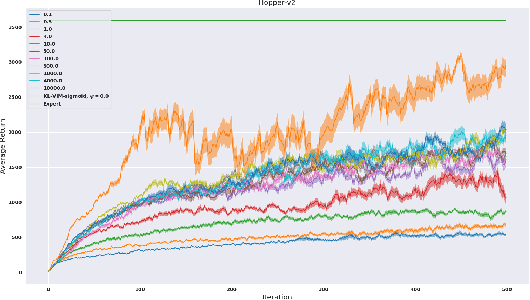

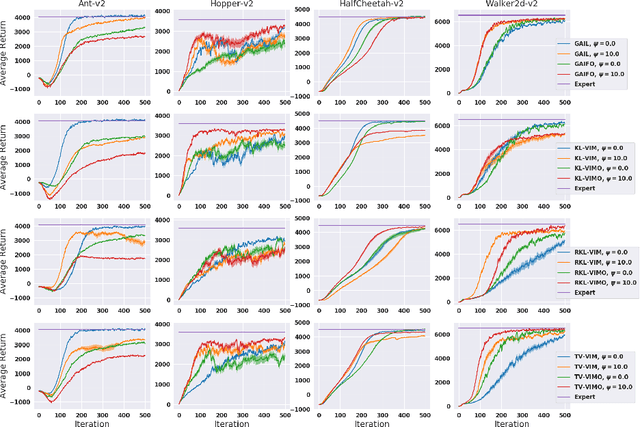
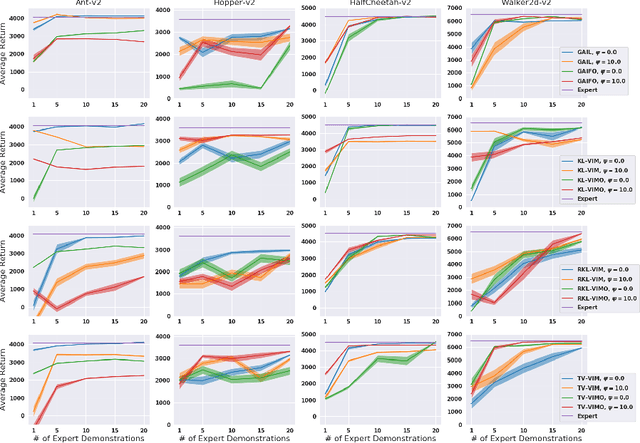
While recent state-of-the-art results for adversarial imitation-learning algorithms are encouraging, recent works exploring the imitation learning from observation (ILO) setting, where trajectories \textit{only} contain expert observations, have not been met with the same success. Inspired by recent investigations of $f$-divergence manipulation for the standard imitation learning setting(Ke et al., 2019; Ghasemipour et al., 2019), we here examine the extent to which variations in the choice of probabilistic divergence may yield more performant ILO algorithms. We unfortunately find that $f$-divergence minimization through reinforcement learning is susceptible to numerical instabilities. We contribute a reparameterization trick for adversarial imitation learning to alleviate the optimization challenges of the promising $f$-divergence minimization framework. Empirically, we demonstrate that our design choices allow for ILO algorithms that outperform baseline approaches and more closely match expert performance in low-dimensional continuous-control tasks.