 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Long-Form Medical Question Answering
Nov 14, 2024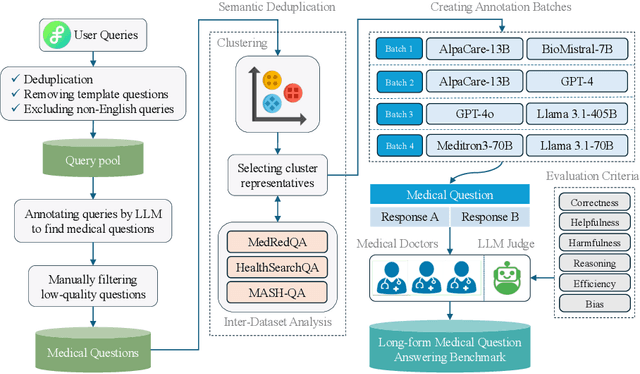

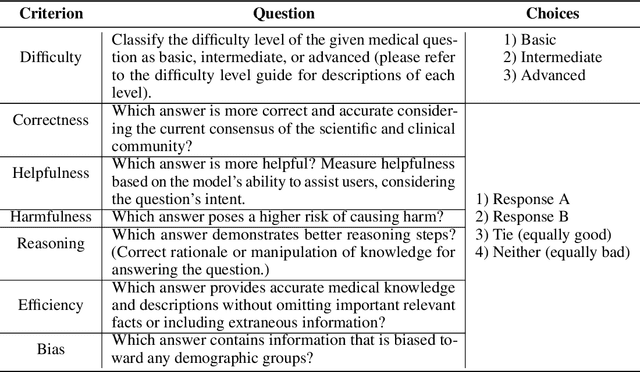
There is a lack of benchmarks for evaluating large language models (LLMs) in long-form medical question answering (QA). Most existing medical QA evaluation benchmarks focus on automatic metrics and multiple-choice questions. While valuable, these benchmarks fail to fully capture or assess the complexities of real-world clinical applications where LLMs are being deployed. Furthermore, existing studies on evaluating long-form answer generation in medical QA are primarily closed-source, lacking access to human medical expert annotations, which makes it difficult to reproduce results and enhance existing baselines. In this work, we introduce a new publicly available benchmark featuring real-world consumer medical questions with long-form answer evaluations annotated by medical doctors. We performed pairwise comparisons of responses from various open and closed-source medical and general-purpose LLMs based on criteria such as correctness, helpfulness, harmfulness, and bias. Additionally, we performed a comprehensive LLM-as-a-judge analysis to study the alignment between human judgments and LLMs. Our preliminary results highlight the strong potential of open LLMs in medical QA compared to leading closed models. Code & Data: https://github.com/lavita-ai/medical-eval-sphere
GisPy: A Tool for Measuring Gist Inference Score in Text
May 25, 2022



Decision making theories such as Fuzzy-Trace Theory (FTT) suggest that individuals tend to rely on gist, or bottom-line meaning, in the text when making decisions. In this work, we delineate the process of developing GisPy, an open-source tool in Python for measuring the Gist Inference Score (GIS) in text. Evaluation of GisPy on documents in three benchmarks from the news and scientific text domains demonstrates that scores generated by our tool significantly distinguish low vs. high gist documents. Our tool is publicly available to use at: https://github.com/phosseini/GisPy.
Commonsense Knowledge-Augmented Pretrained Language Models for Causal Reasoning Classification
Dec 16, 2021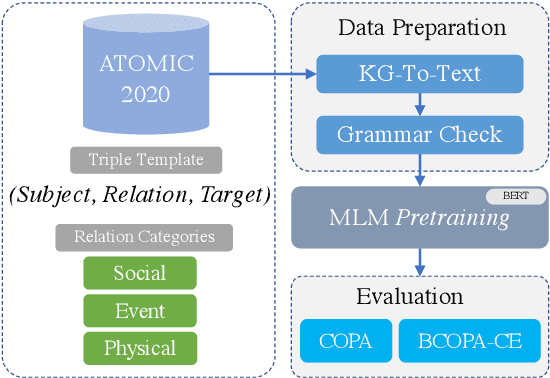
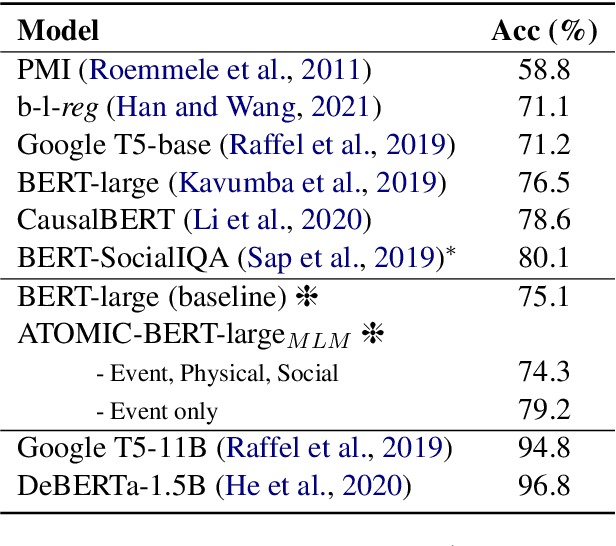
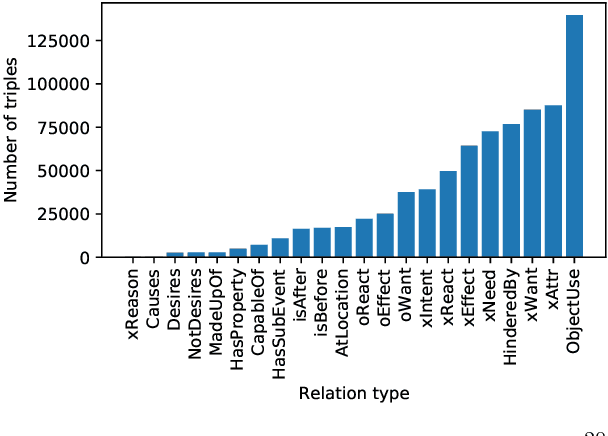
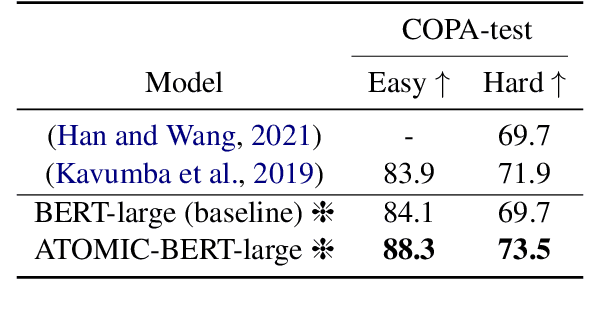
Commonsense knowledge can be leveraged for identifying causal relations in text. In this work, we verbalize triples in ATOMIC2020, a wide coverage commonsense reasoning knowledge graph, to natural language text and continually pretrain a BERT pretrained language model. We evaluate the resulting model on answering commonsense reasoning questions. Our results show that a continually pretrained language model augmented with commonsense reasoning knowledge outperforms our baseline on two commonsense causal reasoning benchmarks, COPA and BCOPA-CE, without additional improvement on the base model or using quality-enhanced data for fine-tuning.
Predicting Directionality in Causal Relations in Text
Mar 25, 2021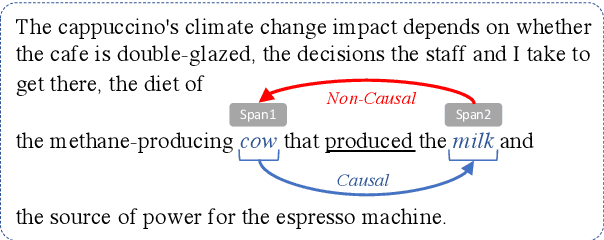
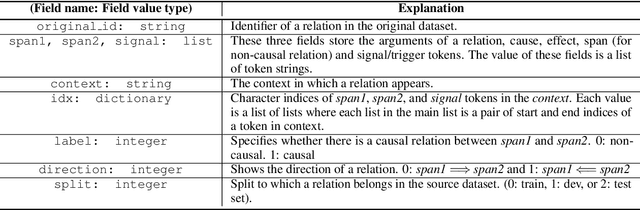
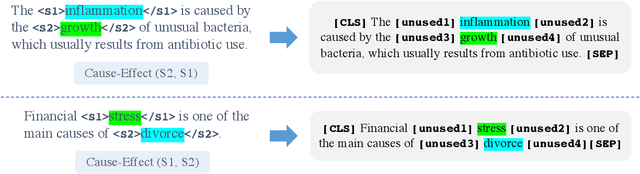
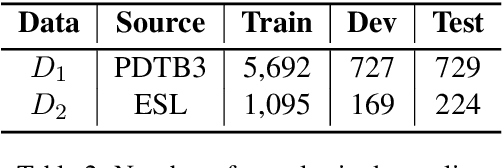
In this work, we test the performance of two bidirectional transformer-based language models, BERT and SpanBERT, on predicting directionality in causal pairs in the textual content. Our preliminary results show that predicting direction for inter-sentence and implicit causal relations is more challenging. And, SpanBERT performs better than BERT on causal samples with longer span length. We also introduce CREST which is a framework for unifying a collection of scattered datasets of causal relations.
ParsiNLU: A Suite of Language Understanding Challenges for Persian
Dec 11, 2020
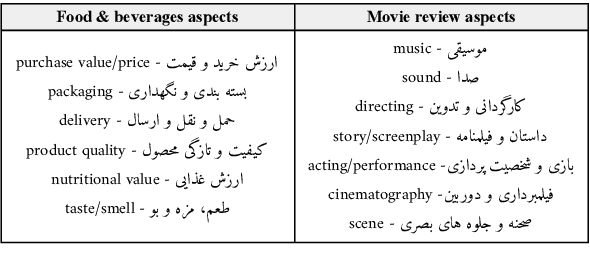
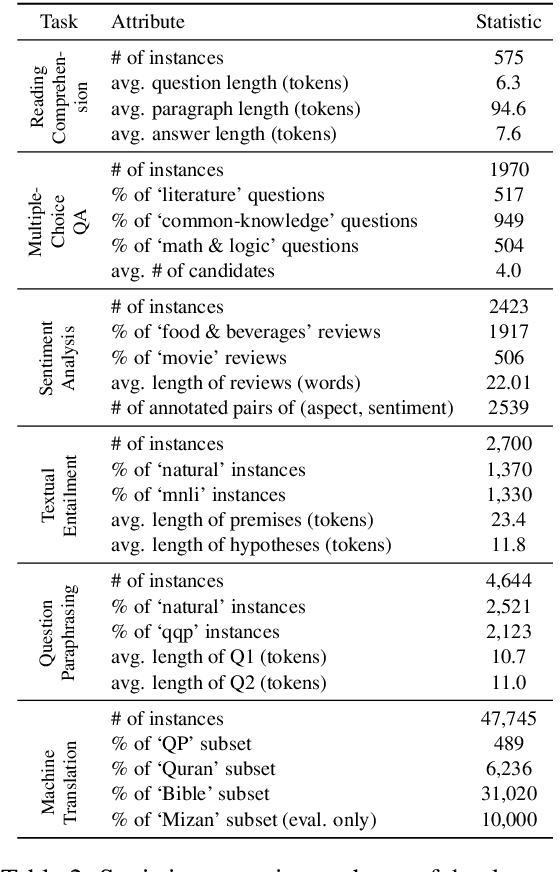
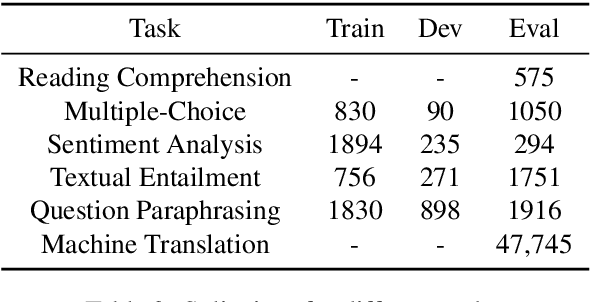
Despite the progress made in recent years in addressing natural language understanding (NLU) challenges, the majority of this progress remains to be concentrated on resource-rich languages like English. This work focuses on Persian language, one of the widely spoken languages in the world, and yet there are few NLU datasets available for this rich language. The availability of high-quality evaluation datasets is a necessity for reliable assessment of the progress on different NLU tasks and domains. We introduce ParsiNLU, the first benchmark in Persian language that includes a range of high-level tasks -- Reading Comprehension, Textual Entailment, etc. These datasets are collected in a multitude of ways, often involving manual annotations by native speakers. This results in over 14.5$k$ new instances across 6 distinct NLU tasks. Besides, we present the first results on state-of-the-art monolingual and multi-lingual pre-trained language-models on this benchmark and compare them with human performance, which provides valuable insights into our ability to tackle natural language understanding challenges in Persian. We hope ParsiNLU fosters further research and advances in Persian language understanding.
A Multi-Modal Method for Satire Detection using Textual and Visual Cues
Oct 13, 2020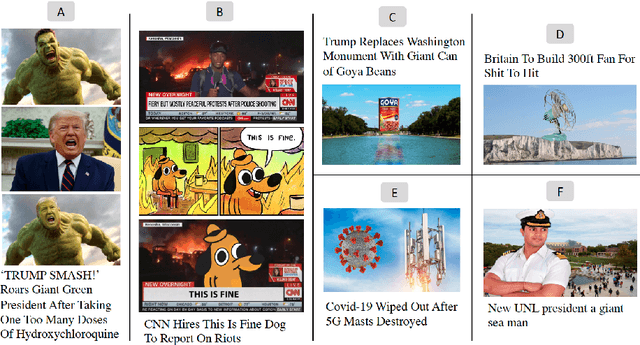
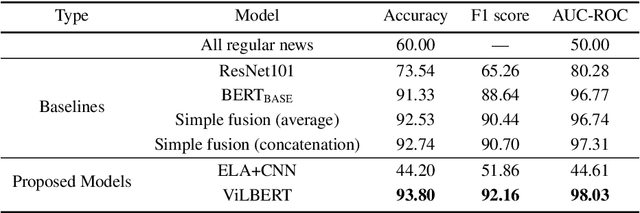

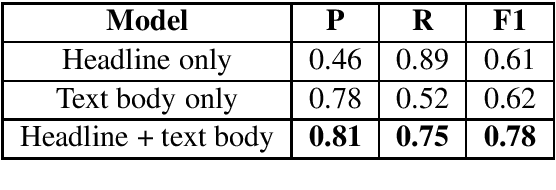
Satire is a form of humorous critique, but it is sometimes misinterpreted by readers as legitimate news, which can lead to harmful consequences. We observe that the images used in satirical news articles often contain absurd or ridiculous content and that image manipulation is used to create fictional scenarios. While previous work have studied text-based methods, in this work we propose a multi-modal approach based on state-of-the-art visiolinguistic model ViLBERT. To this end, we create a new dataset consisting of images and headlines of regular and satirical news for the task of satire detection. We fine-tune ViLBERT on the dataset and train a convolutional neural network that uses an image forensics technique. Evaluation on the dataset shows that our proposed multi-modal approach outperforms image-only, text-only, and simple fusion baselines.
Content analysis of Persian/Farsi Tweets during COVID-19 pandemic in Iran using NLP
May 17, 2020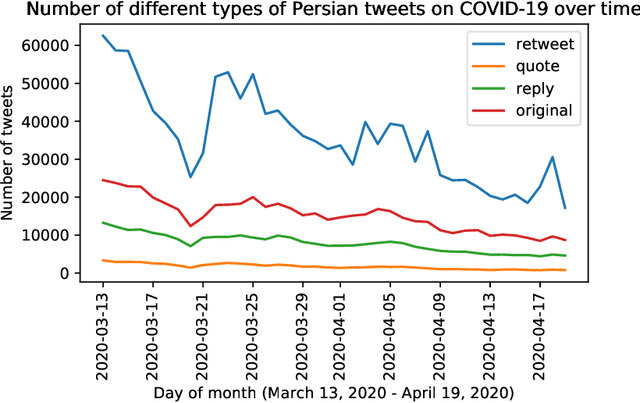
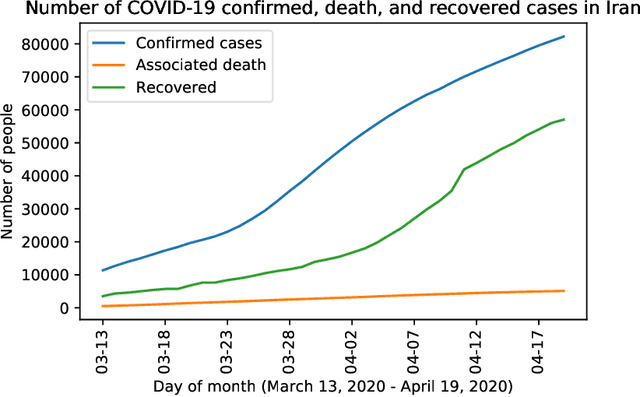


Iran, along with China, South Korea, and Italy was among the countries that were hit hard in the first wave of the COVID-19 spread. Twitter is one of the widely-used online platforms by Iranians inside and abroad for sharing their opinion, thoughts, and feelings about a wide range of issues. In this study, using more than 530,000 original tweets in Persian/Farsi on COVID-19, we analyzed the topics discussed among users, who are mainly Iranians, to gauge and track the response to the pandemic and how it evolved over time. We applied a combination of manual annotation of a random sample of tweets and topic modeling tools to classify the contents and frequency of each category of topics. We identified the top 25 topics among which living experience under home quarantine emerged as a major talking point. We additionally categorized broader content of tweets that shows satire, followed by news, is the dominant tweet type among the Iranian users. While this framework and methodology can be used to track public response to ongoing developments related to COVID-19, a generalization of this framework can become a useful framework to gauge Iranian public reaction to ongoing policy measures or events locally and internationally.
LexiPers: An ontology based sentiment lexicon for Persian
Nov 13, 2019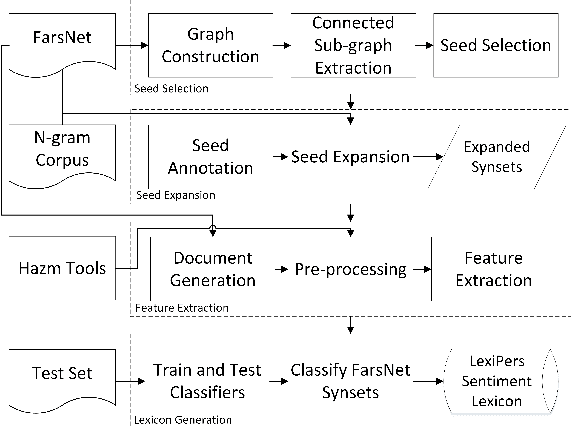
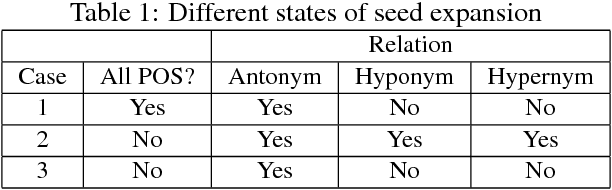

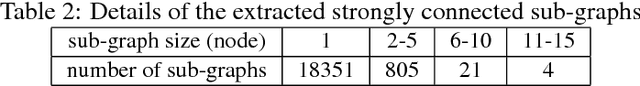
Sentiment analysis refers to the use of natural language processing to identify and extract subjective information from textual resources. One approach for sentiment extraction is using a sentiment lexicon. A sentiment lexicon is a set of words associated with the sentiment orientation that they express. In this paper, we describe the process of generating a general purpose sentiment lexicon for Persian. A new graph-based method is introduced for seed selection and expansion based on an ontology. Sentiment lexicon generation is then mapped to a document classification problem. We used the K-nearest neighbors and nearest centroid methods for classification. These classifiers have been evaluated based on a set of hand labeled synsets. The final sentiment lexicon has been generated by the best classifier. The results show an acceptable performance in terms of accuracy and F-measure in the generated sentiment lexicon.
Identifying Nuances in Fake News vs. Satire: Using Semantic and Linguistic Cues
Nov 05, 2019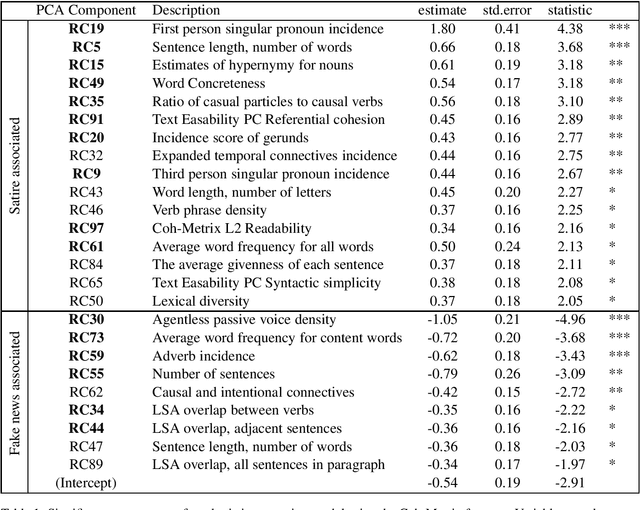
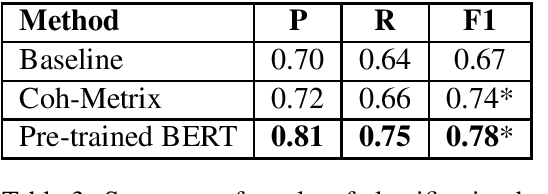
The blurry line between nefarious fake news and protected-speech satire has been a notorious struggle for social media platforms. Further to the efforts of reducing exposure to misinformation on social media, purveyors of fake news have begun to masquerade as satire sites to avoid being demoted. In this work, we address the challenge of automatically classifying fake news versus satire. Previous work have studied whether fake news and satire can be distinguished based on language differences. Contrary to fake news, satire stories are usually humorous and carry some political or social message. We hypothesize that these nuances could be identified using semantic and linguistic cues. Consequently, we train a machine learning method using semantic representation, with a state-of-the-art contextual language model, and with linguistic features based on textual coherence metrics. Empirical evaluation attests to the merits of our approach compared to the language-based baseline and sheds light on the nuances between fake news and satire. As avenues for future work, we consider studying additional linguistic features related to the humor aspect, and enriching the data with current news events, to help identify a political or social message.
SentiPers: A Sentiment Analysis Corpus for Persian
Jan 23, 2018
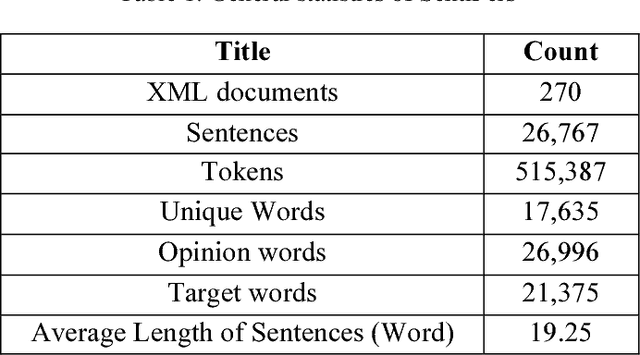
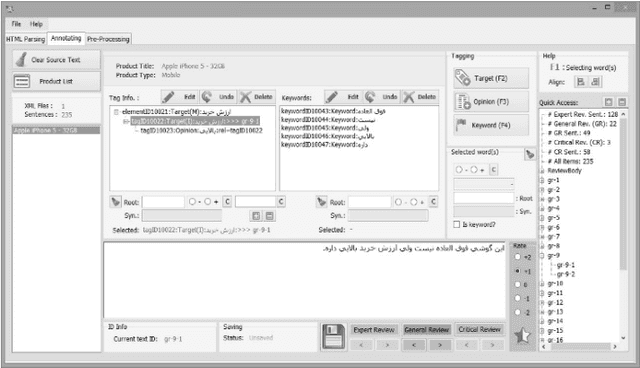
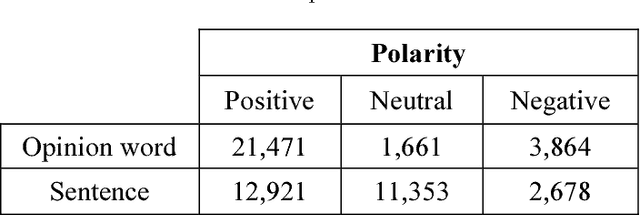
Sentiment Analysis (SA) is a major field of study in natural language processing, computational linguistics and information retrieval. Interest in SA has been constantly growing in both academia and industry over the recent years. Moreover, there is an increasing need for generating appropriate resources and datasets in particular for low resource languages including Persian. These datasets play an important role in designing and developing appropriate opinion mining platforms using supervised, semi-supervised or unsupervised methods. In this paper, we outline the entire process of developing a manually annotated sentiment corpus, SentiPers, which covers formal and informal written contemporary Persian. To the best of our knowledge, SentiPers is a unique sentiment corpus with such a rich annotation in three different levels including document-level, sentence-level, and entity/aspect-level for Persian. The corpus contains more than 26000 sentences of users opinions from digital product domain and benefits from special characteristics such as quantifying the positiveness or negativity of an opinion through assigning a number within a specific range to any given sentence. Furthermore, we present statistics on various components of our corpus as well as studying the inter-annotator agreement among the annotators. Finally, some of the challenges that we faced during the annotation process will be discussed as well.