 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Long-Form Medical Question Answering
Nov 14, 2024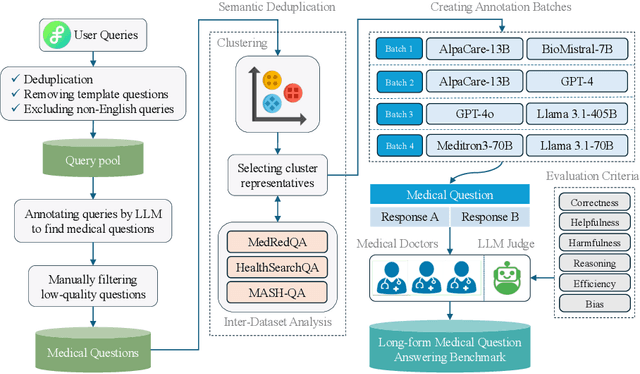

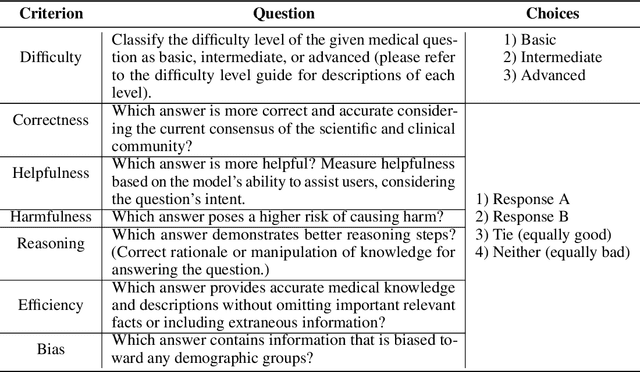
There is a lack of benchmarks for evaluating large language models (LLMs) in long-form medical question answering (QA). Most existing medical QA evaluation benchmarks focus on automatic metrics and multiple-choice questions. While valuable, these benchmarks fail to fully capture or assess the complexities of real-world clinical applications where LLMs are being deployed. Furthermore, existing studies on evaluating long-form answer generation in medical QA are primarily closed-source, lacking access to human medical expert annotations, which makes it difficult to reproduce results and enhance existing baselines. In this work, we introduce a new publicly available benchmark featuring real-world consumer medical questions with long-form answer evaluations annotated by medical doctors. We performed pairwise comparisons of responses from various open and closed-source medical and general-purpose LLMs based on criteria such as correctness, helpfulness, harmfulness, and bias. Additionally, we performed a comprehensive LLM-as-a-judge analysis to study the alignment between human judgments and LLMs. Our preliminary results highlight the strong potential of open LLMs in medical QA compared to leading closed models. Code & Data: https://github.com/lavita-ai/medical-eval-sphere
Proof-of-Contribution-Based Design for Collaborative Machine Learning on Blockchain
Feb 27, 2023
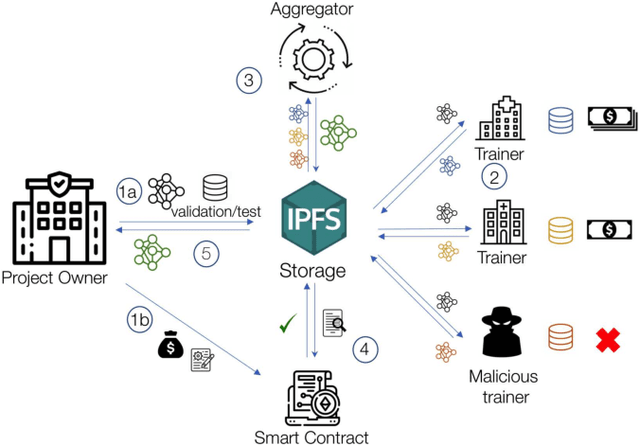
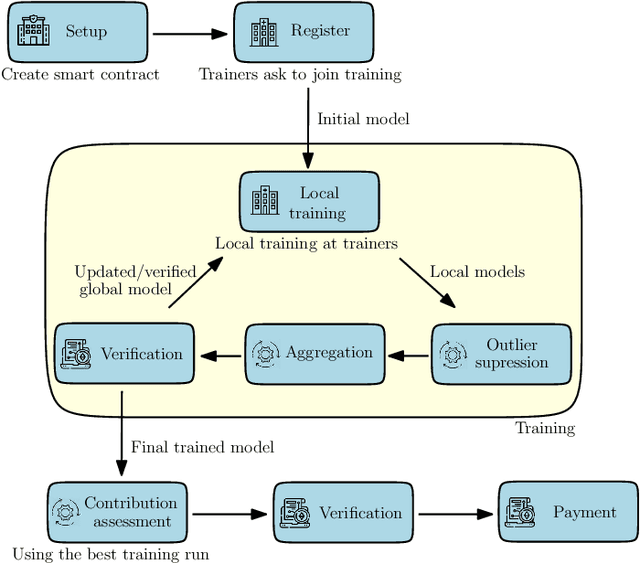
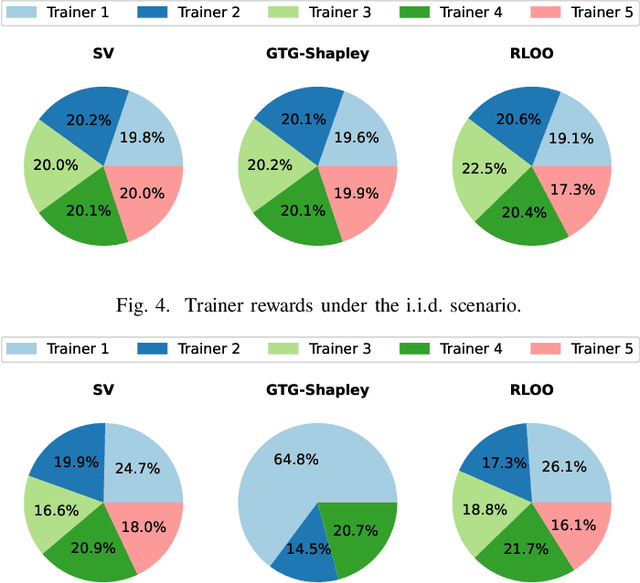
We consider a project (model) owner that would like to train a model by utilizing the local private data and compute power of interested data owners, i.e., trainers. Our goal is to design a data marketplace for such decentralized collaborative/federated learning applications that simultaneously provides i) proof-of-contribution based reward allocation so that the trainers are compensated based on their contributions to the trained model; ii) privacy-preserving decentralized model training by avoiding any data movement from data owners; iii) robustness against malicious parties (e.g., trainers aiming to poison the model); iv) verifiability in the sense that the integrity, i.e., correctness, of all computations in the data market protocol including contribution assessment and outlier detection are verifiable through zero-knowledge proofs; and v) efficient and universal design. We propose a blockchain-based marketplace design to achieve all five objectives mentioned above. In our design, we utilize a distributed storage infrastructure and an aggregator aside from the project owner and the trainers. The aggregator is a processing node that performs certain computations, including assessing trainer contributions, removing outliers, and updating hyper-parameters. We execute the proposed data market through a blockchain smart contract. The deployed smart contract ensures that the project owner cannot evade payment, and honest trainers are rewarded based on their contributions at the end of training. Finally, we implement the building blocks of the proposed data market and demonstrate their applicability in practical scenarios through extensive experiments.