 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Not Design, Learn: A Trainable Scoring Function for Uncertainty Estimation in Generative LLMs
Jun 17, 2024In this work, we introduce the Learnable Response Scoring Function (LARS) for Uncertainty Estimation (UE) in generative Large Language Models (LLMs). Current scoring functions for probability-based UE, such as length-normalized scoring and semantic contribution-based weighting, are designed to solve specific aspects of the problem but exhibit limitations, including the inability to handle biased probabilities and under-performance in low-resource languages like Turkish. To address these issues, we propose LARS, a scoring function that leverages supervised data to capture complex dependencies between tokens and probabilities, thereby producing more reliable and calibrated response scores in computing the uncertainty of generations. Our extensive experiments across multiple datasets show that LARS substantially outperforms existing scoring functions considering various probability-based UE methods.
Maverick-Aware Shapley Valuation for Client Selection in Federated Learning
May 21, 2024



Federated Learning (FL) allows clients to train a model collaboratively without sharing their private data. One key challenge in practical FL systems is data heterogeneity, particularly in handling clients with rare data, also referred to as Mavericks. These clients own one or more data classes exclusively, and the model performance becomes poor without their participation. Thus, utilizing Mavericks throughout training is crucial. In this paper, we first design a Maverick-aware Shapley valuation that fairly evaluates the contribution of Mavericks. The main idea is to compute the clients' Shapley values (SV) class-wise, i.e., per label. Next, we propose FedMS, a Maverick-Shapley client selection mechanism for FL that intelligently selects the clients that contribute the most in each round, by employing our Maverick-aware SV-based contribution score. We show that, compared to an extensive list of baselines, FedMS achieves better model performance and fairer Shapley Rewards distribution.
MARS: Meaning-Aware Response Scoring for Uncertainty Estimation in Generative LLMs
Feb 20, 2024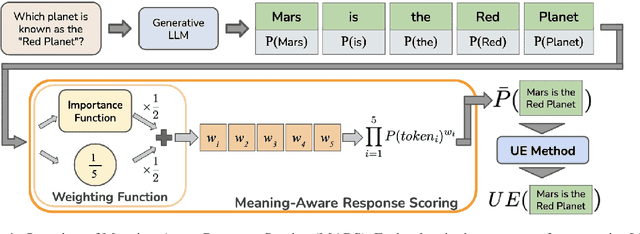
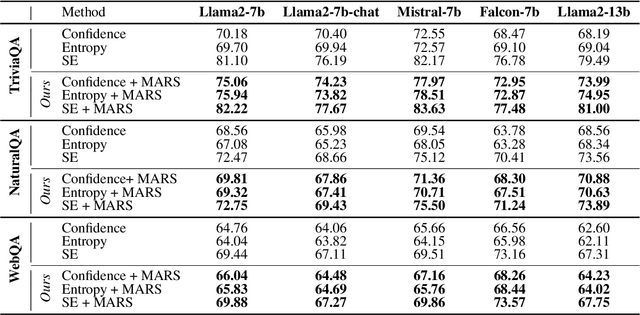
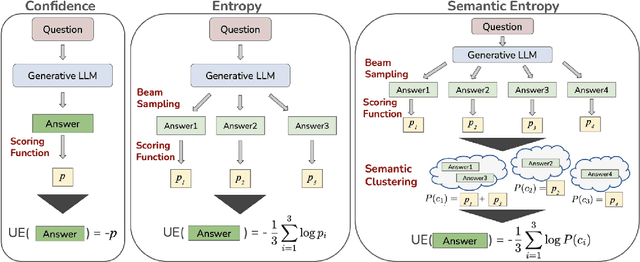
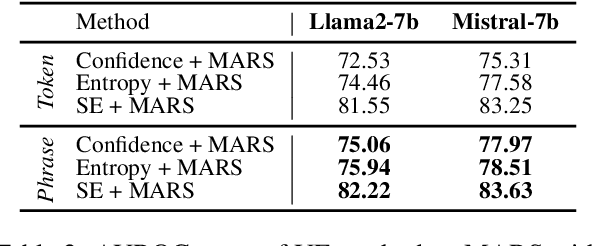
Generative Large Language Models (LLMs) are widely utilized for their excellence in various tasks. However, their tendency to produce inaccurate or misleading outputs poses a potential risk, particularly in high-stakes environments. Therefore, estimating the correctness of generative LLM outputs is an important task for enhanced reliability. Uncertainty Estimation (UE) in generative LLMs is an evolving domain, where SOTA probability-based methods commonly employ length-normalized scoring. In this work, we propose Meaning-Aware Response Scoring (MARS) as an alternative to length-normalized scoring for UE methods. MARS is a novel scoring function that considers the semantic contribution of each token in the generated sequence in the context of the question. We demonstrate that integrating MARS into UE methods results in a universal and significant improvement in UE performance. We conduct experiments using three distinct closed-book question-answering datasets across five popular pre-trained LLMs. Lastly, we validate the efficacy of MARS on a Medical QA dataset. Code can be found https://github.com/Ybakman/LLM_Uncertainity.
Kick Bad Guys Out! Zero-Knowledge-Proof-Based Anomaly Detection in Federated Learning
Oct 06, 2023

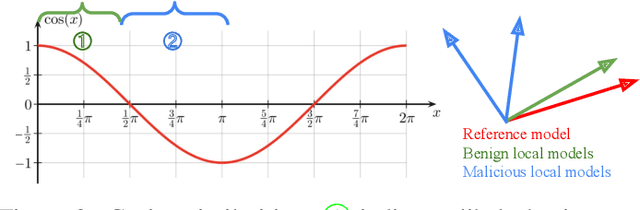
Federated learning (FL) systems are vulnerable to malicious clients that submit poisoned local models to achieve their adversarial goals, such as preventing the convergence of the global model or inducing the global model to misclassify some data. Many existing defense mechanisms are impractical in real-world FL systems, as they require prior knowledge of the number of malicious clients or rely on re-weighting or modifying submissions. This is because adversaries typically do not announce their intentions before attacking, and re-weighting might change aggregation results even in the absence of attacks. To address these challenges in real FL systems, this paper introduces a cutting-edge anomaly detection approach with the following features: i) Detecting the occurrence of attacks and performing defense operations only when attacks happen; ii) Upon the occurrence of an attack, further detecting the malicious client models and eliminating them without harming the benign ones; iii) Ensuring honest execution of defense mechanisms at the server by leveraging a zero-knowledge proof mechanism. We validate the superior performance of the proposed approach with extensive experiments.
FedMLSecurity: A Benchmark for Attacks and Defenses in Federated Learning and LLMs
Jun 08, 2023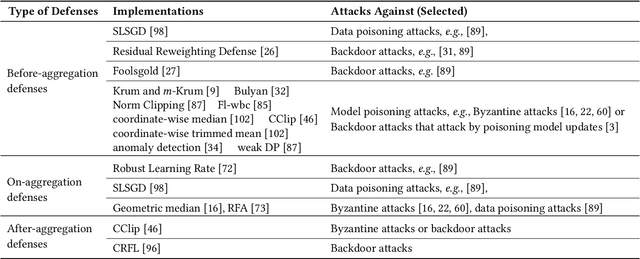

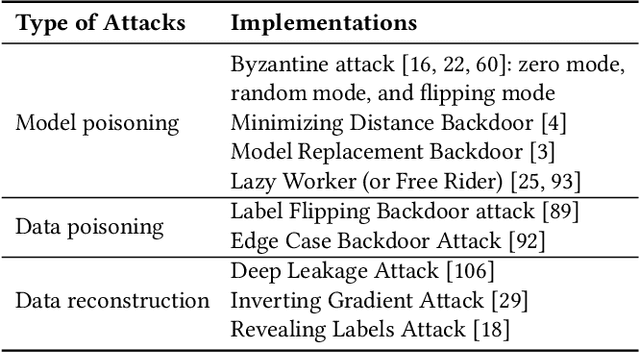
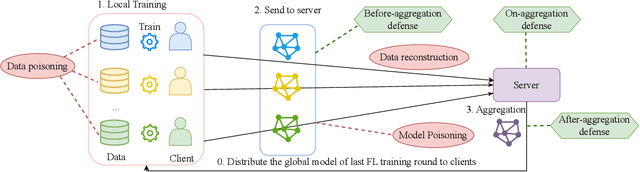
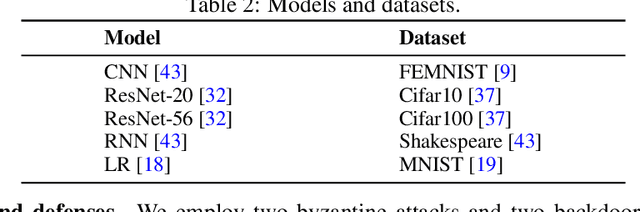
This paper introduces FedMLSecurity, a benchmark that simulates adversarial attacks and corresponding defense mechanisms in Federated Learning (FL). As an integral module of the open-sourced library FedML that facilitates FL algorithm development and performance comparison, FedMLSecurity enhances the security assessment capacity of FedML. FedMLSecurity comprises two principal components: FedMLAttacker, which simulates attacks injected into FL training, and FedMLDefender, which emulates defensive strategies designed to mitigate the impacts of the attacks. FedMLSecurity is open-sourced 1 and is customizable to a wide range of machine learning models (e.g., Logistic Regression, ResNet, GAN, etc.) and federated optimizers (e.g., FedAVG, FedOPT, FedNOVA, etc.). Experimental evaluations in this paper also demonstrate the ease of application of FedMLSecurity to Large Language Models (LLMs), further reinforcing its versatility and practical utility in various scenarios.
Proof-of-Contribution-Based Design for Collaborative Machine Learning on Blockchain
Feb 27, 2023
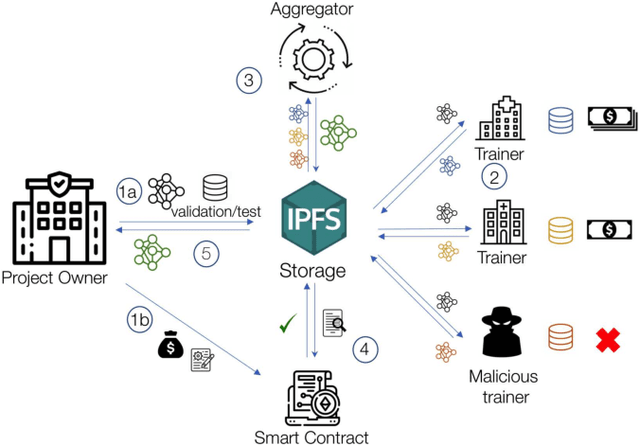
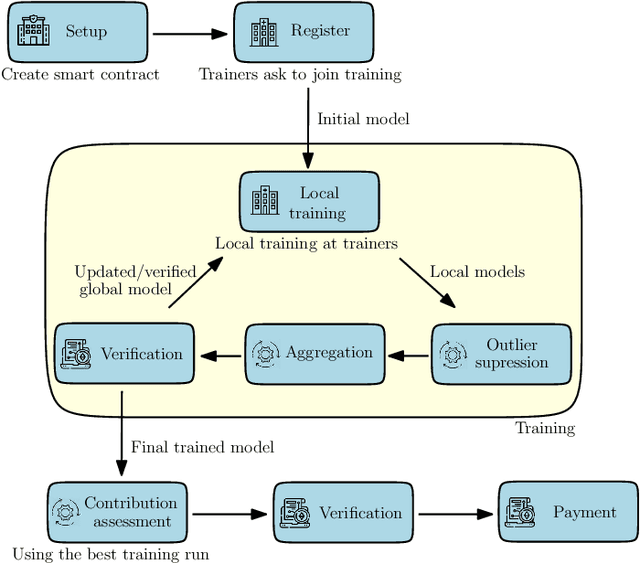
We consider a project (model) owner that would like to train a model by utilizing the local private data and compute power of interested data owners, i.e., trainers. Our goal is to design a data marketplace for such decentralized collaborative/federated learning applications that simultaneously provides i) proof-of-contribution based reward allocation so that the trainers are compensated based on their contributions to the trained model; ii) privacy-preserving decentralized model training by avoiding any data movement from data owners; iii) robustness against malicious parties (e.g., trainers aiming to poison the model); iv) verifiability in the sense that the integrity, i.e., correctness, of all computations in the data market protocol including contribution assessment and outlier detection are verifiable through zero-knowledge proofs; and v) efficient and universal design. We propose a blockchain-based marketplace design to achieve all five objectives mentioned above. In our design, we utilize a distributed storage infrastructure and an aggregator aside from the project owner and the trainers. The aggregator is a processing node that performs certain computations, including assessing trainer contributions, removing outliers, and updating hyper-parameters. We execute the proposed data market through a blockchain smart contract. The deployed smart contract ensures that the project owner cannot evade payment, and honest trainers are rewarded based on their contributions at the end of training. Finally, we implement the building blocks of the proposed data market and demonstrate their applicability in practical scenarios through extensive experiments.
Secure Federated Clustering
May 31, 2022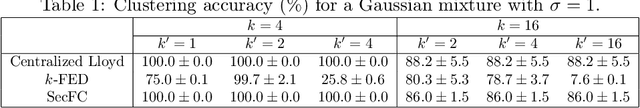
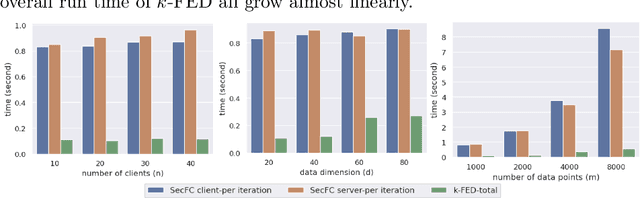

We consider a foundational unsupervised learning task of $k$-means data clustering, in a federated learning (FL) setting consisting of a central server and many distributed clients. We develop SecFC, which is a secure federated clustering algorithm that simultaneously achieves 1) universal performance: no performance loss compared with clustering over centralized data, regardless of data distribution across clients; 2) data privacy: each client's private data and the cluster centers are not leaked to other clients and the server. In SecFC, the clients perform Lagrange encoding on their local data and share the coded data in an information-theoretically private manner; then leveraging the algebraic structure of the coding, the FL network exactly executes the Lloyd's $k$-means heuristic over the coded data to obtain the final clustering. Experiment results on synthetic and real datasets demonstrate the universally superior performance of SecFC for different data distributions across clients, and its computational practicality for various combinations of system parameters. Finally, we propose an extension of SecFC to further provide membership privacy for all data points.
Version Age of Information in Clustered Gossip Networks
Sep 17, 2021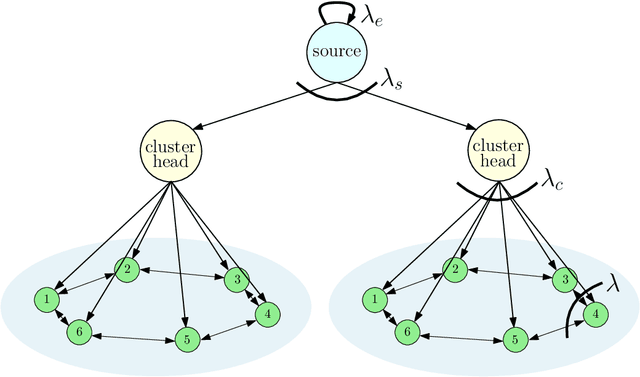



We consider a network consisting of a single source and $n$ receiver nodes that are grouped into equal-sized clusters. We use cluster heads in each cluster to facilitate communication between the source and the nodes within that cluster. Inside clusters, nodes are connected to each other according to a given network topology. Based on the connectivity among the nodes, each node relays its current stored version of the source update to its neighboring nodes by $local$ $gossiping$. We use the $version$ $age$ metric to assess information freshness at the nodes. We consider disconnected, ring, and fully connected network topologies for each cluster. For each network topology, we characterize the average version age at each node and find the average version age scaling as a function of the network size $n$. Our results indicate that per node average version age scalings of $O(\sqrt{n})$, $O(n^{\frac{1}{3}})$, and $O(\log n)$ are achievable in disconnected, ring, and fully connected cluster models, respectively. Next, we increase connectivity in the network and allow gossiping among the cluster heads to improve version age at the nodes. With that, we show that when the cluster heads form a ring network among themselves, we obtain per node average version age scalings of $O(n^{\frac{1}{3}})$, $O(n^{\frac{1}{4}})$, and $O(\log n)$ in disconnected, ring, and fully connected cluster models, respectively. Next, focusing on a ring network topology in each cluster, we introduce hierarchy to the considered clustered gossip network model and show that when we employ two levels of hierarchy, we can achieve the same $O(n^{\frac{1}{4}})$ scaling without using dedicated cluster heads. We generalize this result for $h$ levels of hierarchy and show that per user average version age scaling of $O(n^{\frac{1}{2h}})$ is achievable in the case of a ring network in each cluster across all hierarchy levels.
Gossiping with Binary Freshness Metric
Jul 29, 2021


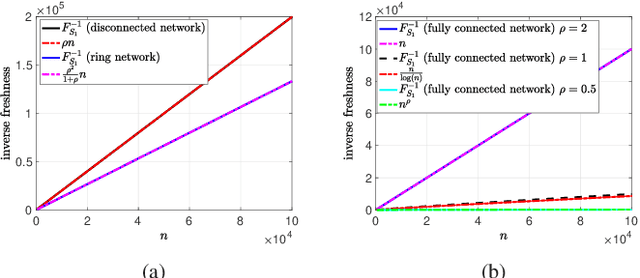
We consider the binary freshness metric for gossip networks that consist of a single source and $n$ end-nodes, where the end-nodes are allowed to share their stored versions of the source information with the other nodes. We develop recursive equations that characterize binary freshness in arbitrarily connected gossip networks using the stochastic hybrid systems (SHS) approach. Next, we study binary freshness in several structured gossip networks, namely disconnected, ring and fully connected networks. We show that for both disconnected and ring network topologies, when the number of nodes gets large, the binary freshness of a node decreases down to 0 as $n^{-1}$, but the freshness is strictly larger for the ring topology. We also show that for the fully connected topology, the rate of decrease to 0 is slower, and it takes the form of $n^{-\rho}$ for a $\rho$ smaller than 1, when the update rates of the source and the end-nodes are sufficiently large. Finally, we study the binary freshness metric for clustered gossip networks, where multiple clusters of structured gossip networks are connected to the source node through designated access nodes, i.e., cluster heads. We characterize the binary freshness in such networks and numerically study how the optimal cluster sizes change with respect to the update rates in the system.
Age of Gossip in Networks with Community Structure
May 06, 2021


We consider a network consisting of a single source and $n$ receiver nodes that are grouped into $m$ equal size communities, i.e., clusters, where each cluster includes $k$ nodes and is served by a dedicated cluster head. The source node keeps versions of an observed process and updates each cluster through the associated cluster head. Nodes within each cluster are connected to each other according to a given network topology. Based on this topology, each node relays its current update to its neighboring nodes by $local$ $gossiping$. We use the $version$ $age$ metric to quantify information timeliness at the receiver nodes. We consider disconnected, ring, and fully connected network topologies for each cluster. For each of these network topologies, we characterize the average version age at each node and find the version age scaling as a function of the network size $n$. Our results indicate that per node version age scalings of $O(\sqrt{n})$, $O(n^{\frac{1}{3}})$, and $O(\log n)$ are achievable in disconnected, ring, and fully connected networks, respectively. Finally, through numerical evaluations, we determine the version age-optimum $(m,k)$ pairs as a function of the source, cluster head, and node update rates.