 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCroMo-Mixup: Augmenting Cross-Model Representations for Continual Self-Supervised Learning
Jul 16, 2024



Continual self-supervised learning (CSSL) learns a series of tasks sequentially on the unlabeled data. Two main challenges of continual learning are catastrophic forgetting and task confusion. While CSSL problem has been studied to address the catastrophic forgetting challenge, little work has been done to address the task confusion aspect. In this work, we show through extensive experiments that self-supervised learning (SSL) can make CSSL more susceptible to the task confusion problem, particularly in less diverse settings of class incremental learning because different classes belonging to different tasks are not trained concurrently. Motivated by this challenge, we present a novel cross-model feature Mixup (CroMo-Mixup) framework that addresses this issue through two key components: 1) Cross-Task data Mixup, which mixes samples across tasks to enhance negative sample diversity; and 2) Cross-Model feature Mixup, which learns similarities between embeddings obtained from current and old models of the mixed sample and the original images, facilitating cross-task class contrast learning and old knowledge retrieval. We evaluate the effectiveness of CroMo-Mixup to improve both Task-ID prediction and average linear accuracy across all tasks on three datasets, CIFAR10, CIFAR100, and tinyImageNet under different class-incremental learning settings. We validate the compatibility of CroMo-Mixup on four state-of-the-art SSL objectives. Code is available at \url{https://github.com/ErumMushtaq/CroMo-Mixup}.
Do Not Design, Learn: A Trainable Scoring Function for Uncertainty Estimation in Generative LLMs
Jun 17, 2024In this work, we introduce the Learnable Response Scoring Function (LARS) for Uncertainty Estimation (UE) in generative Large Language Models (LLMs). Current scoring functions for probability-based UE, such as length-normalized scoring and semantic contribution-based weighting, are designed to solve specific aspects of the problem but exhibit limitations, including the inability to handle biased probabilities and under-performance in low-resource languages like Turkish. To address these issues, we propose LARS, a scoring function that leverages supervised data to capture complex dependencies between tokens and probabilities, thereby producing more reliable and calibrated response scores in computing the uncertainty of generations. Our extensive experiments across multiple datasets show that LARS substantially outperforms existing scoring functions considering various probability-based UE methods.
MARS: Meaning-Aware Response Scoring for Uncertainty Estimation in Generative LLMs
Feb 20, 2024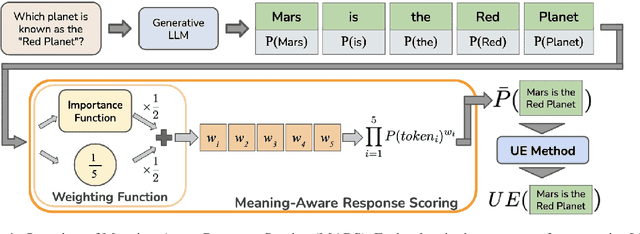
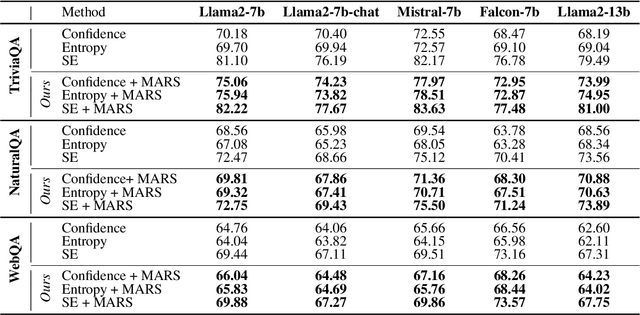
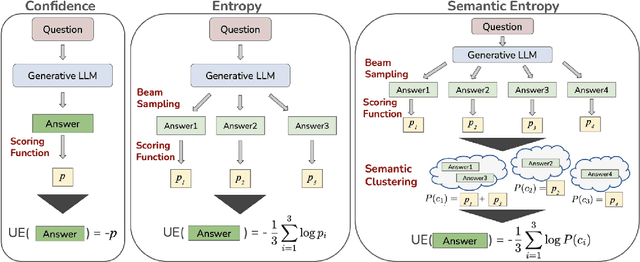
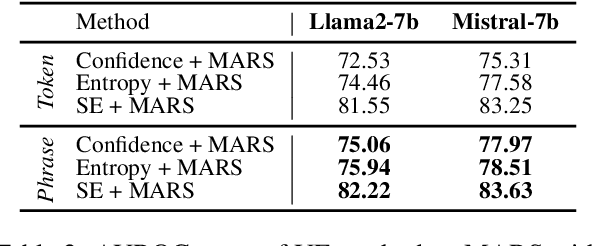
Generative Large Language Models (LLMs) are widely utilized for their excellence in various tasks. However, their tendency to produce inaccurate or misleading outputs poses a potential risk, particularly in high-stakes environments. Therefore, estimating the correctness of generative LLM outputs is an important task for enhanced reliability. Uncertainty Estimation (UE) in generative LLMs is an evolving domain, where SOTA probability-based methods commonly employ length-normalized scoring. In this work, we propose Meaning-Aware Response Scoring (MARS) as an alternative to length-normalized scoring for UE methods. MARS is a novel scoring function that considers the semantic contribution of each token in the generated sequence in the context of the question. We demonstrate that integrating MARS into UE methods results in a universal and significant improvement in UE performance. We conduct experiments using three distinct closed-book question-answering datasets across five popular pre-trained LLMs. Lastly, we validate the efficacy of MARS on a Medical QA dataset. Code can be found https://github.com/Ybakman/LLM_Uncertainity.
On Compositionality and Improved Training of NADO
Jun 20, 2023NeurAlly-Decomposed Oracle (NADO) is a powerful approach for controllable generation with large language models. Differentiating from finetuning/prompt tuning, it has the potential to avoid catastrophic forgetting of the large base model and achieve guaranteed convergence to an entropy-maximized closed-form solution without significantly limiting the model capacity. Despite its success, several challenges arise when applying NADO to more complex scenarios. First, the best practice of using NADO for the composition of multiple control signals is under-explored. Second, vanilla NADO suffers from gradient vanishing for low-probability control signals and is highly reliant on the forward-consistency regularization. In this paper, we study the aforementioned challenges when using NADO theoretically and empirically. We show we can achieve guaranteed compositional generalization of NADO with a certain practice, and propose a novel alternative parameterization of NADO to perfectly guarantee the forward-consistency. We evaluate the improved training of NADO, i.e. NADO++, on CommonGen. Results show that NADO++ improves the effectiveness of the algorithm in multiple aspects.
Unsupervised Melody-to-Lyric Generation
May 30, 2023



Automatic melody-to-lyric generation is a task in which song lyrics are generated to go with a given melody. It is of significant practical interest and more challenging than unconstrained lyric generation as the music imposes additional constraints onto the lyrics. The training data is limited as most songs are copyrighted, resulting in models that underfit the complicated cross-modal relationship between melody and lyrics. In this work, we propose a method for generating high-quality lyrics without training on any aligned melody-lyric data. Specifically, we design a hierarchical lyric generation framework that first generates a song outline and second the complete lyrics. The framework enables disentanglement of training (based purely on text) from inference (melody-guided text generation) to circumvent the shortage of parallel data. We leverage the segmentation and rhythm alignment between melody and lyrics to compile the given melody into decoding constraints as guidance during inference. The two-step hierarchical design also enables content control via the lyric outline, a much-desired feature for democratizing collaborative song creation. Experimental results show that our model can generate high-quality lyrics that are more on-topic, singable, intelligible, and coherent than strong baselines, for example SongMASS, a SOTA model trained on a parallel dataset, with a 24% relative overall quality improvement based on human ratings. O
Unsupervised Melody-Guided Lyrics Generation
May 26, 2023



Automatic song writing is a topic of significant practical interest. However, its research is largely hindered by the lack of training data due to copyright concerns and challenged by its creative nature. Most noticeably, prior works often fall short of modeling the cross-modal correlation between melody and lyrics due to limited parallel data, hence generating lyrics that are less singable. Existing works also lack effective mechanisms for content control, a much desired feature for democratizing song creation for people with limited music background. In this work, we propose to generate pleasantly listenable lyrics without training on melody-lyric aligned data. Instead, we design a hierarchical lyric generation framework that disentangles training (based purely on text) from inference (melody-guided text generation). At inference time, we leverage the crucial alignments between melody and lyrics and compile the given melody into constraints to guide the generation process. Evaluation results show that our model can generate high-quality lyrics that are more singable, intelligible, coherent, and in rhyme than strong baselines including those supervised on parallel data.
PLACES: Prompting Language Models for Social Conversation Synthesis
Feb 17, 2023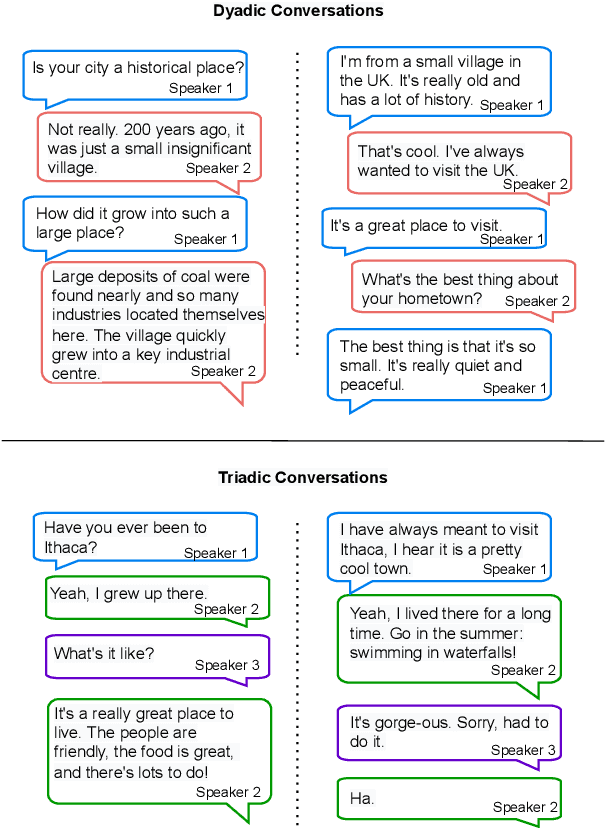
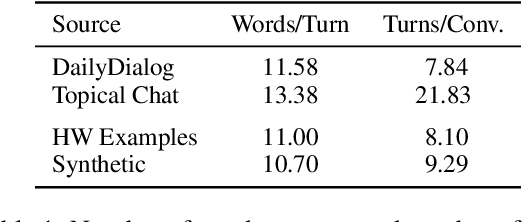
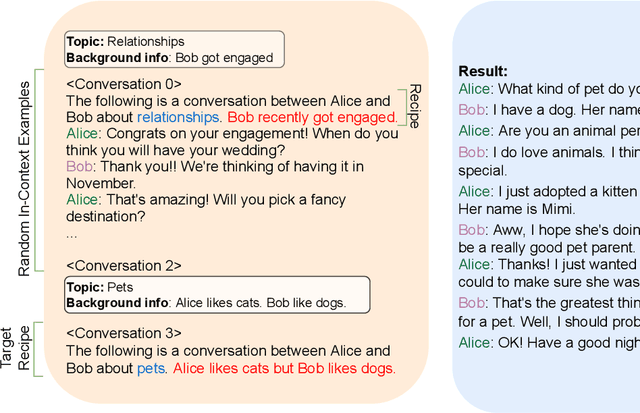
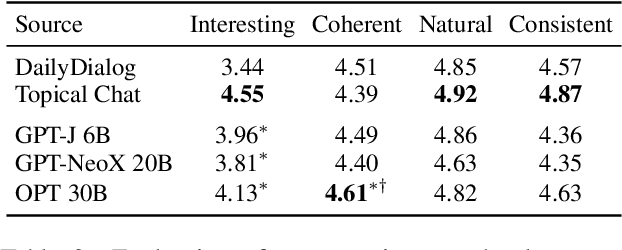
Collecting high quality conversational data can be very expensive for most applications and infeasible for others due to privacy, ethical, or similar concerns. A promising direction to tackle this problem is to generate synthetic dialogues by prompting large language models. In this work, we use a small set of expert-written conversations as in-context examples to synthesize a social conversation dataset using prompting. We perform several thorough evaluations of our synthetic conversations compared to human-collected conversations. This includes various dimensions of conversation quality with human evaluation directly on the synthesized conversations, and interactive human evaluation of chatbots fine-tuned on the synthetically generated dataset. We additionally demonstrate that this prompting approach is generalizable to multi-party conversations, providing potential to create new synthetic data for multi-party tasks. Our synthetic multi-party conversations were rated more favorably across all measured dimensions compared to conversation excerpts sampled from a human-collected multi-party dataset.
Weakly Supervised Data Augmentation Through Prompting for Dialogue Understanding
Nov 02, 2022



Dialogue understanding tasks often necessitate abundant annotated data to achieve good performance and that presents challenges in low-resource settings. To alleviate this barrier, we explore few-shot data augmentation for dialogue understanding by prompting large pre-trained language models and present a novel approach that iterates on augmentation quality by applying weakly-supervised filters. We evaluate our methods on the emotion and act classification tasks in DailyDialog and the intent classification task in Facebook Multilingual Task-Oriented Dialogue. Models fine-tuned on our augmented data mixed with few-shot ground truth data are able to approach or surpass existing state-of-the-art performance on both datasets. For DailyDialog specifically, using 10% of the ground truth data we outperform the current state-of-the-art model which uses 100% of the data.
Finite-Time Consensus Learning for Decentralized Optimization with Nonlinear Gossiping
Nov 13, 2021
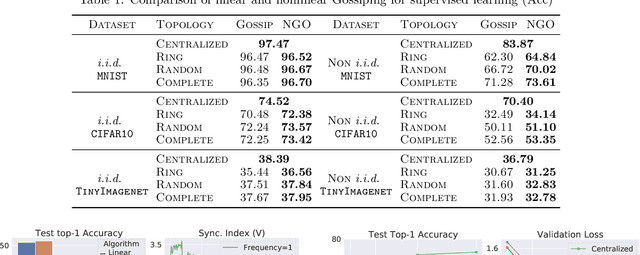
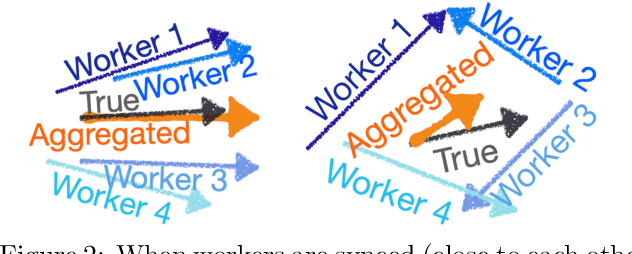

Distributed learning has become an integral tool for scaling up machine learning and addressing the growing need for data privacy. Although more robust to the network topology, decentralized learning schemes have not gained the same level of popularity as their centralized counterparts for being less competitive performance-wise. In this work, we attribute this issue to the lack of synchronization among decentralized learning workers, showing both empirically and theoretically that the convergence rate is tied to the synchronization level among the workers. Such motivated, we present a novel decentralized learning framework based on nonlinear gossiping (NGO), that enjoys an appealing finite-time consensus property to achieve better synchronization. We provide a careful analysis of its convergence and discuss its merits for modern distributed optimization applications, such as deep neural networks. Our analysis on how communication delay and randomized chats affect learning further enables the derivation of practical variants that accommodate asynchronous and randomized communications. To validate the effectiveness of our proposal, we benchmark NGO against competing solutions through an extensive set of tests, with encouraging results reported.
Variational Inference with Holder Bounds
Nov 13, 2021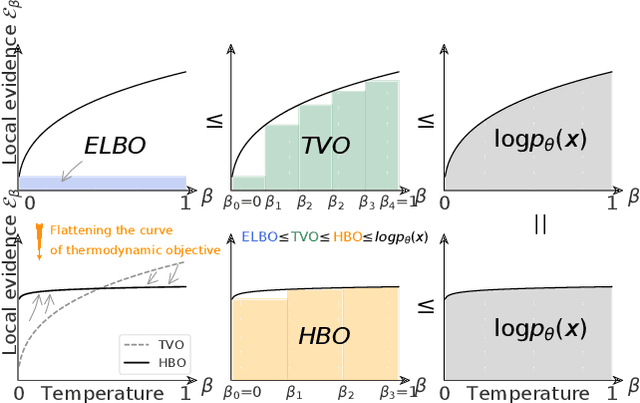
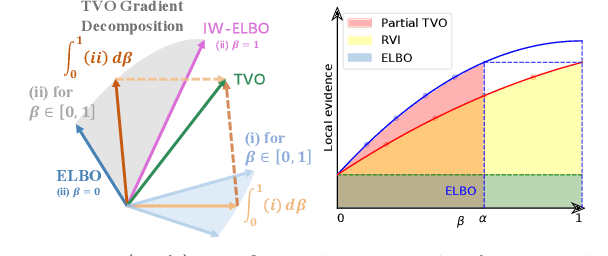
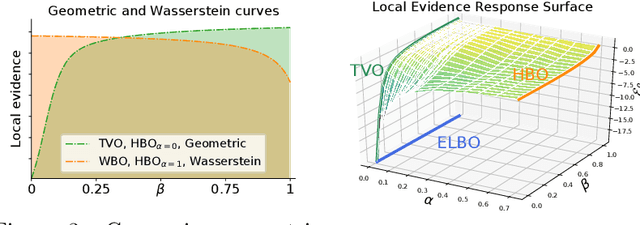
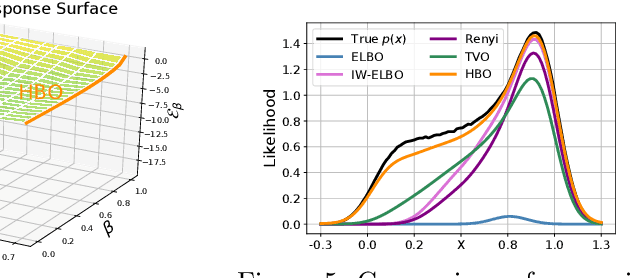
The recent introduction of thermodynamic integration techniques has provided a new framework for understanding and improving variational inference (VI). In this work, we present a careful analysis of the thermodynamic variational objective (TVO), bridging the gap between existing variational objectives and shedding new insights to advance the field. In particular, we elucidate how the TVO naturally connects the three key variational schemes, namely the importance-weighted VI, Renyi-VI, and MCMC-VI, which subsumes most VI objectives employed in practice. To explain the performance gap between theory and practice, we reveal how the pathological geometry of thermodynamic curves negatively affects TVO. By generalizing the integration path from the geometric mean to the weighted Holder mean, we extend the theory of TVO and identify new opportunities for improving VI. This motivates our new VI objectives, named the Holder bounds, which flatten the thermodynamic curves and promise to achieve a one-step approximation of the exact marginal log-likelihood. A comprehensive discussion on the choices of numerical estimators is provided. We present strong empirical evidence on both synthetic and real-world datasets to support our claims.