 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Sustainable Continual Learning: Detection and Knowledge Repurposing of Similar Tasks
Oct 11, 2022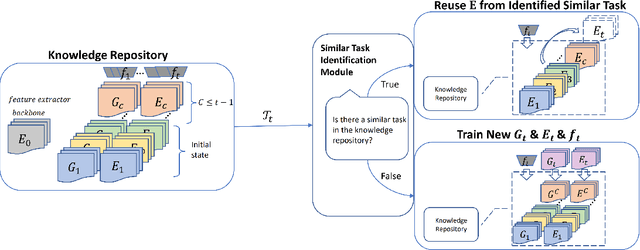

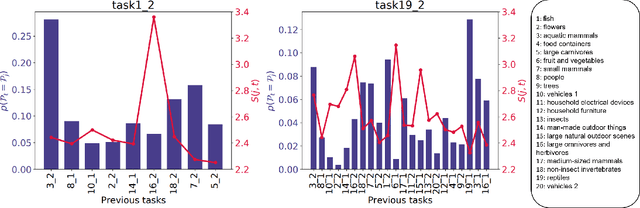
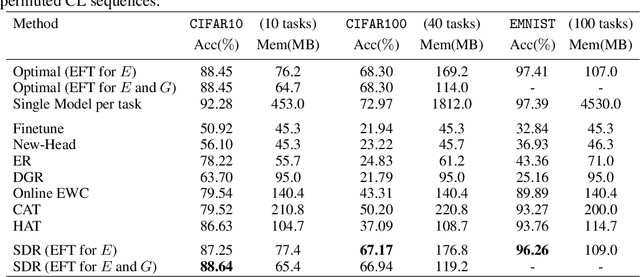
Most existing works on continual learning (CL) focus on overcoming the catastrophic forgetting (CF) problem, with dynamic models and replay methods performing exceptionally well. However, since current works tend to assume exclusivity or dissimilarity among learning tasks, these methods require constantly accumulating task-specific knowledge in memory for each task. This results in the eventual prohibitive expansion of the knowledge repository if we consider learning from a long sequence of tasks. In this work, we introduce a paradigm where the continual learner gets a sequence of mixed similar and dissimilar tasks. We propose a new continual learning framework that uses a task similarity detection function that does not require additional learning, with which we analyze whether there is a specific task in the past that is similar to the current task. We can then reuse previous task knowledge to slow down parameter expansion, ensuring that the CL system expands the knowledge repository sublinearly to the number of learned tasks. Our experiments show that the proposed framework performs competitively on widely used computer vision benchmarks such as CIFAR10, CIFAR100, and EMNIST.
Finite-Time Consensus Learning for Decentralized Optimization with Nonlinear Gossiping
Nov 13, 2021
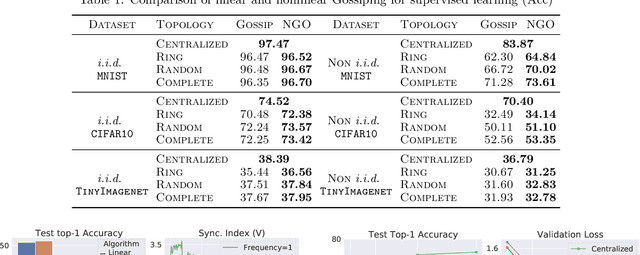
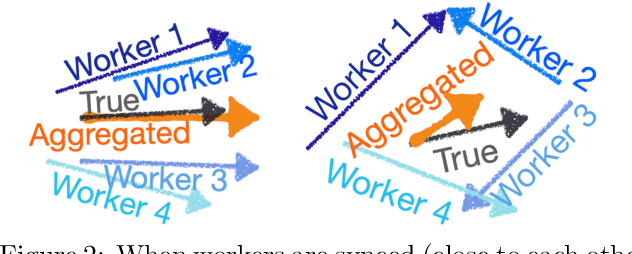

Distributed learning has become an integral tool for scaling up machine learning and addressing the growing need for data privacy. Although more robust to the network topology, decentralized learning schemes have not gained the same level of popularity as their centralized counterparts for being less competitive performance-wise. In this work, we attribute this issue to the lack of synchronization among decentralized learning workers, showing both empirically and theoretically that the convergence rate is tied to the synchronization level among the workers. Such motivated, we present a novel decentralized learning framework based on nonlinear gossiping (NGO), that enjoys an appealing finite-time consensus property to achieve better synchronization. We provide a careful analysis of its convergence and discuss its merits for modern distributed optimization applications, such as deep neural networks. Our analysis on how communication delay and randomized chats affect learning further enables the derivation of practical variants that accommodate asynchronous and randomized communications. To validate the effectiveness of our proposal, we benchmark NGO against competing solutions through an extensive set of tests, with encouraging results reported.
Variational Inference with Holder Bounds
Nov 13, 2021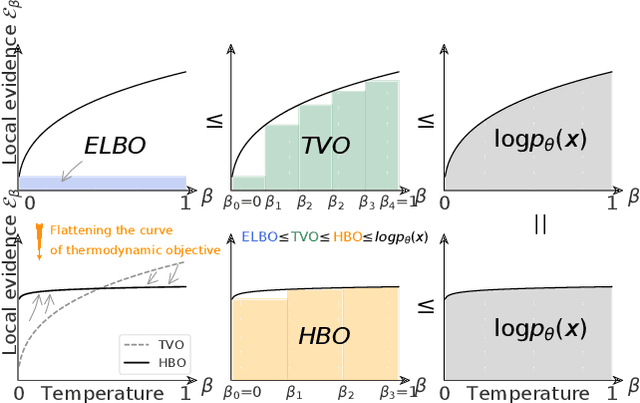
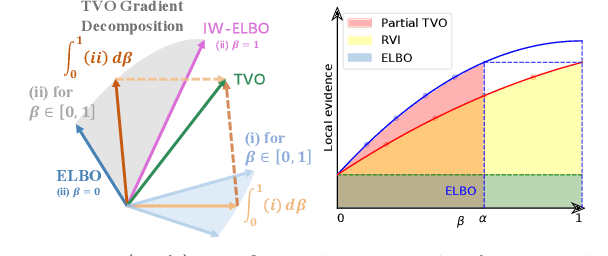
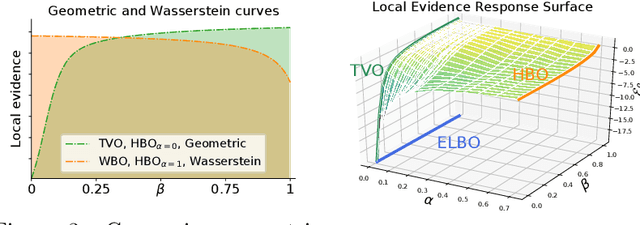
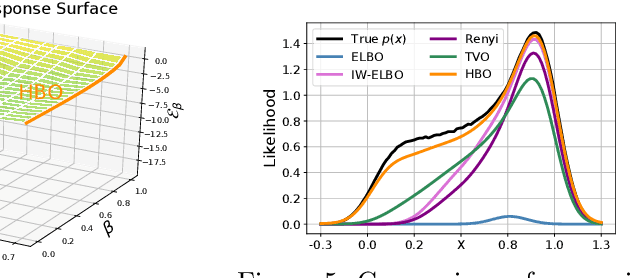
The recent introduction of thermodynamic integration techniques has provided a new framework for understanding and improving variational inference (VI). In this work, we present a careful analysis of the thermodynamic variational objective (TVO), bridging the gap between existing variational objectives and shedding new insights to advance the field. In particular, we elucidate how the TVO naturally connects the three key variational schemes, namely the importance-weighted VI, Renyi-VI, and MCMC-VI, which subsumes most VI objectives employed in practice. To explain the performance gap between theory and practice, we reveal how the pathological geometry of thermodynamic curves negatively affects TVO. By generalizing the integration path from the geometric mean to the weighted Holder mean, we extend the theory of TVO and identify new opportunities for improving VI. This motivates our new VI objectives, named the Holder bounds, which flatten the thermodynamic curves and promise to achieve a one-step approximation of the exact marginal log-likelihood. A comprehensive discussion on the choices of numerical estimators is provided. We present strong empirical evidence on both synthetic and real-world datasets to support our claims.
Simpler, Faster, Stronger: Breaking The log-K Curse On Contrastive Learners With FlatNCE
Jul 02, 2021



InfoNCE-based contrastive representation learners, such as SimCLR, have been tremendously successful in recent years. However, these contrastive schemes are notoriously resource demanding, as their effectiveness breaks down with small-batch training (i.e., the log-K curse, whereas K is the batch-size). In this work, we reveal mathematically why contrastive learners fail in the small-batch-size regime, and present a novel simple, non-trivial contrastive objective named FlatNCE, which fixes this issue. Unlike InfoNCE, our FlatNCE no longer explicitly appeals to a discriminative classification goal for contrastive learning. Theoretically, we show FlatNCE is the mathematical dual formulation of InfoNCE, thus bridging the classical literature on energy modeling; and empirically, we demonstrate that, with minimal modification of code, FlatNCE enables immediate performance boost independent of the subject-matter engineering efforts. The significance of this work is furthered by the powerful generalization of contrastive learning techniques, and the introduction of new tools to monitor and diagnose contrastive training. We substantiate our claims with empirical evidence on CIFAR10, ImageNet, and other datasets, where FlatNCE consistently outperforms InfoNCE.
Tight Mutual Information Estimation With Contrastive Fenchel-Legendre Optimization
Jul 02, 2021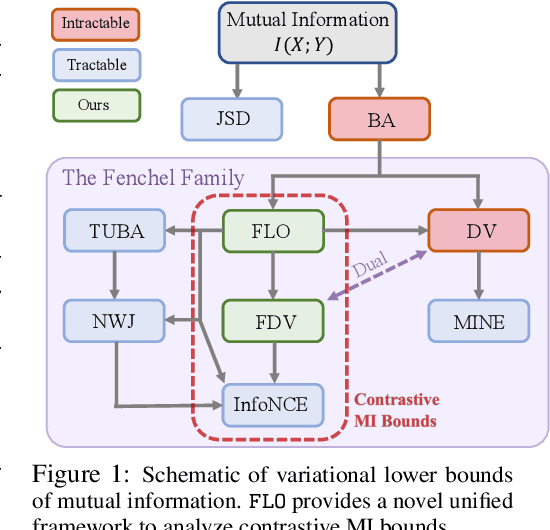
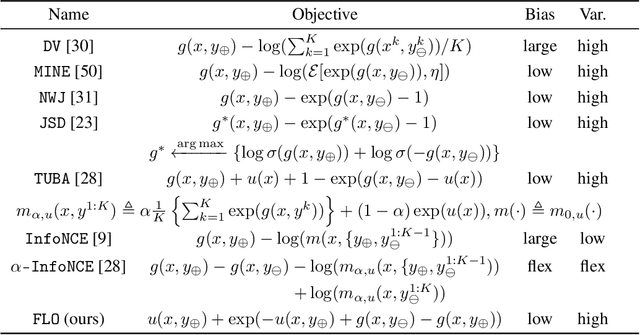
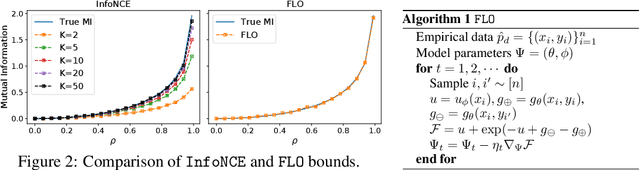

Successful applications of InfoNCE and its variants have popularized the use of contrastive variational mutual information (MI) estimators in machine learning. While featuring superior stability, these estimators crucially depend on costly large-batch training, and they sacrifice bound tightness for variance reduction. To overcome these limitations, we revisit the mathematics of popular variational MI bounds from the lens of unnormalized statistical modeling and convex optimization. Our investigation not only yields a new unified theoretical framework encompassing popular variational MI bounds but also leads to a novel, simple, and powerful contrastive MI estimator named as FLO. Theoretically, we show that the FLO estimator is tight, and it provably converges under stochastic gradient descent. Empirically, our FLO estimator overcomes the limitations of its predecessors and learns more efficiently. The utility of FLO is verified using an extensive set of benchmarks, which also reveals the trade-offs in practical MI estimation.
Supercharging Imbalanced Data Learning With Causal Representation Transfer
Nov 25, 2020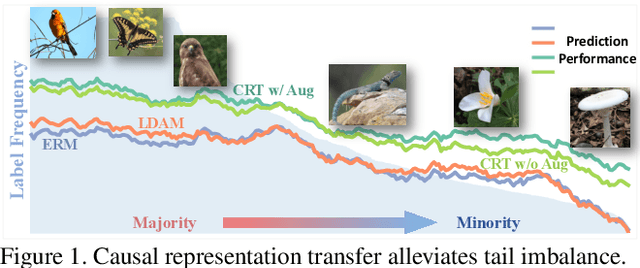
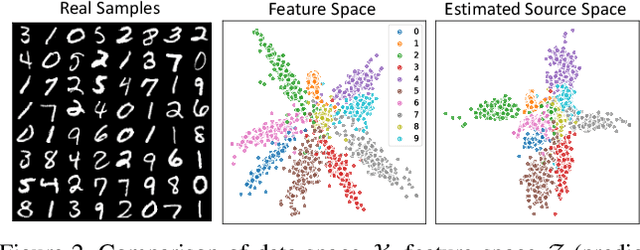
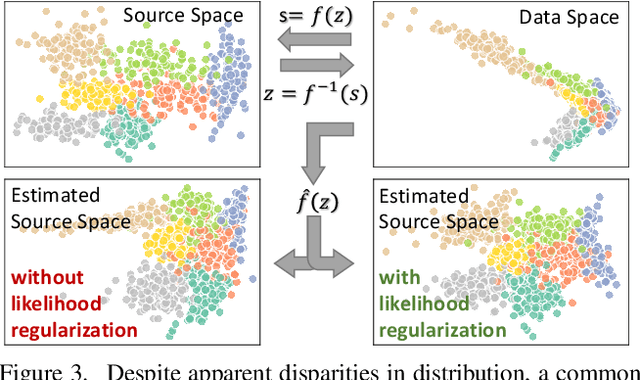
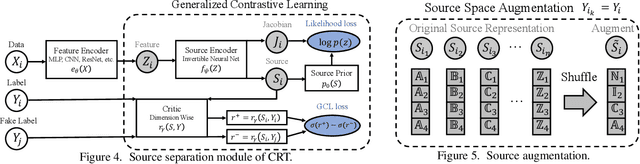
Dealing with severe class imbalance poses a major challenge for real-world applications, especially when the accurate classification and generalization of minority classes is of primary interest. In computer vision, learning from long tailed datasets is a recurring theme, especially for natural image datasets. While existing solutions mostly appeal to sampling or weighting adjustments to alleviate the pathological imbalance, or imposing inductive bias to prioritize non-spurious associations, we take novel perspectives to promote sample efficiency and model generalization based on the invariance principles of causality. Our proposal posits a meta-distributional scenario, where the data generating mechanism is invariant across the label-conditional feature distributions. Such causal assumption enables efficient knowledge transfer from the dominant classes to their under-represented counterparts, even if the respective feature distributions show apparent disparities. This allows us to leverage a causal data inflation procedure to enlarge the representation of minority classes. Our development is orthogonal to the existing extreme classification techniques thus can be seamlessly integrated. The utility of our proposal is validated with an extensive set of synthetic and real-world computer vision tasks against SOTA solutions.
GO Hessian for Expectation-Based Objectives
Jun 16, 2020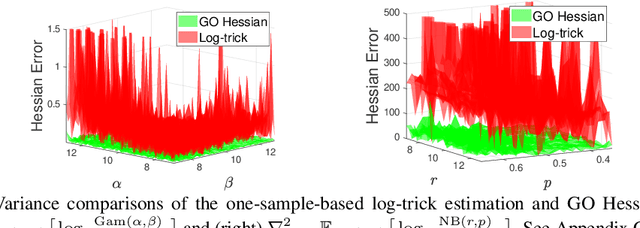

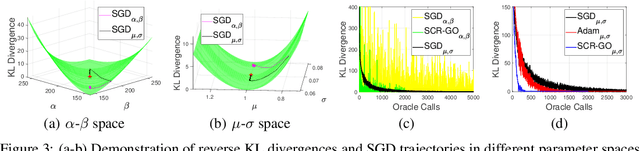
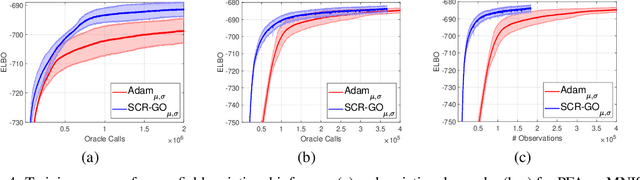
An unbiased low-variance gradient estimator, termed GO gradient, was proposed recently for expectation-based objectives $\mathbb{E}_{q_{\boldsymbol{\gamma}}(\boldsymbol{y})} [f(\boldsymbol{y})]$, where the random variable (RV) $\boldsymbol{y}$ may be drawn from a stochastic computation graph with continuous (non-reparameterizable) internal nodes and continuous/discrete leaves. Upgrading the GO gradient, we present for $\mathbb{E}_{q_{\boldsymbol{\boldsymbol{\gamma}}}(\boldsymbol{y})} [f(\boldsymbol{y})]$ an unbiased low-variance Hessian estimator, named GO Hessian. Considering practical implementation, we reveal that GO Hessian is easy-to-use with auto-differentiation and Hessian-vector products, enabling efficient cheap exploitation of curvature information over stochastic computation graphs. As representative examples, we present the GO Hessian for non-reparameterizable gamma and negative binomial RVs/nodes. Based on the GO Hessian, we design a new second-order method for $\mathbb{E}_{q_{\boldsymbol{\boldsymbol{\gamma}}}(\boldsymbol{y})} [f(\boldsymbol{y})]$, with rigorous experiments conducted to verify its effectiveness and efficiency.