 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReViSQL: Achieving Human-Level Text-to-SQL
Mar 20, 2026Translating natural language to SQL (Text-to-SQL) is a critical challenge in both database research and data analytics applications. Recent efforts have focused on enhancing SQL reasoning by developing large language models and AI agents that decompose Text-to-SQL tasks into manually designed, step-by-step pipelines. However, despite these extensive architectural engineering efforts, a significant gap remains: even state-of-the-art (SOTA) AI agents have not yet achieved the human-level accuracy on the BIRD benchmark. In this paper, we show that closing this gap does not require further architectural complexity, but rather clean training data to improve SQL reasoning of the underlying models. We introduce ReViSQL, a streamlined framework that achieves human-level accuracy on BIRD for the first time. Instead of complex AI agents, ReViSQL leverages reinforcement learning with verifiable rewards (RLVR) on BIRD-Verified, a dataset we curated comprising 2.5k verified Text-to-SQL instances based on the BIRD Train set. To construct BIRD-Verified, we design a data correction and verification workflow involving SQL experts. We identified and corrected data errors in 61.1% of a subset of BIRD Train. By training on BIRD-Verified, we show that improving data quality alone boosts the single-generation accuracy by 8.2-13.9% under the same RLVR algorithm. To further enhance performance, ReViSQL performs inference-time scaling via execution-based reconciliation and majority voting. Empirically, we demonstrate the superiority of our framework with two model scales: ReViSQL-235B-A22B and ReViSQL-30B-A3B. On an expert-verified BIRD Mini-Dev set, ReViSQL-235B-A22B achieves 93.2% execution accuracy, exceeding the proxy human-level accuracy (92.96%) and outperforming the prior open-source SOTA method by 9.8%. Our lightweight ReViSQL-30B-A3B matches the prior SOTA at a 7.5$\times$ lower per-query cost.
Pervasive Annotation Errors Break Text-to-SQL Benchmarks and Leaderboards
Jan 13, 2026Researchers have proposed numerous text-to-SQL techniques to streamline data analytics and accelerate the development of database-driven applications. To compare these techniques and select the best one for deployment, the community depends on public benchmarks and their leaderboards. Since these benchmarks heavily rely on human annotations during question construction and answer evaluation, the validity of the annotations is crucial. In this paper, we conduct an empirical study that (i) benchmarks annotation error rates for two widely used text-to-SQL benchmarks, BIRD and Spider 2.0-Snow, and (ii) corrects a subset of the BIRD development (Dev) set to measure the impact of annotation errors on text-to-SQL agent performance and leaderboard rankings. Through expert analysis, we show that BIRD Mini-Dev and Spider 2.0-Snow have error rates of 52.8% and 62.8%, respectively. We re-evaluate all 16 open-source agents from the BIRD leaderboard on both the original and the corrected BIRD Dev subsets. We show that performance changes range from -7% to 31% (in relative terms) and rank changes range from $-9$ to $+9$ positions. We further assess whether these impacts generalize to the full BIRD Dev set. We find that the rankings of agents on the uncorrected subset correlate strongly with those on the full Dev set (Spearman's $r_s$=0.85, $p$=3.26e-5), whereas they correlate weakly with those on the corrected subset (Spearman's $r_s$=0.32, $p$=0.23). These findings show that annotation errors can significantly distort reported performance and rankings, potentially misguiding research directions or deployment choices. Our code and data are available at https://github.com/uiuc-kang-lab/text_to_sql_benchmarks.
A GPT-based Decision Transformer for Multi-Vehicle Coordination at Unsignalized Intersections
Oct 08, 2024
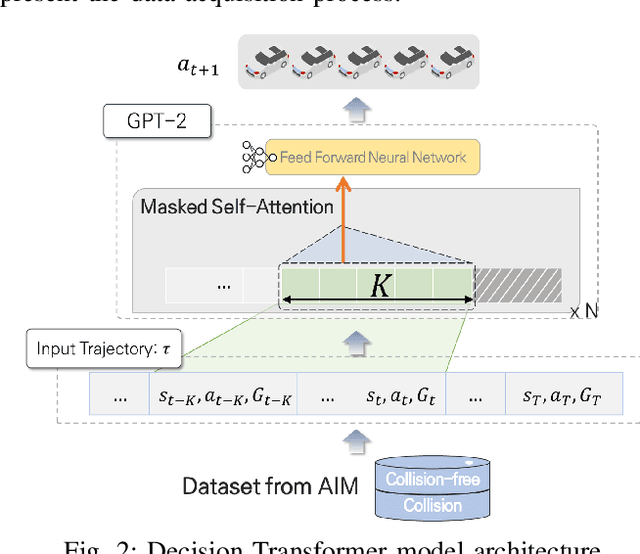
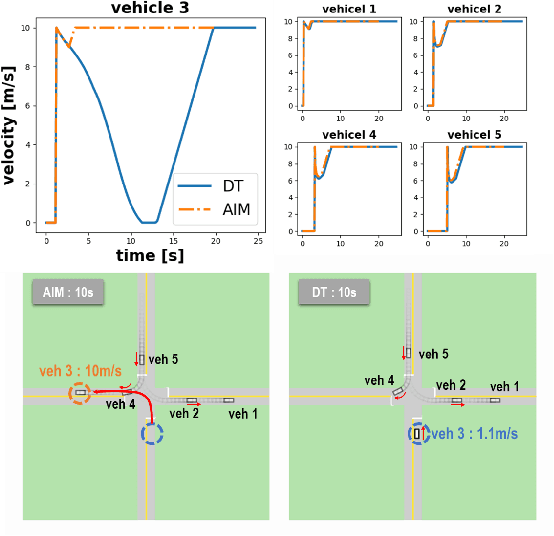
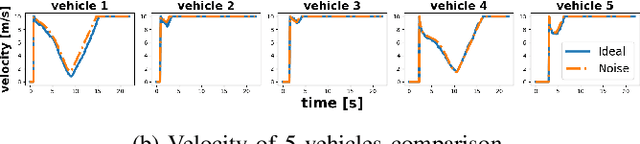
In this paper, we explore the application of the Decision Transformer, a decision-making algorithm based on the Generative Pre-trained Transformer (GPT) architecture, to multi-vehicle coordination at unsignalized intersections. We formulate the coordination problem so as to find the optimal trajectories for multiple vehicles at intersections, modeling it as a sequence prediction task to fully leverage the power of GPTs as a sequence model. Through extensive experiments, we compare our approach to a reservation-based intersection management system. Our results show that the Decision Transformer can outperform the training data in terms of total travel time and can be generalized effectively to various scenarios, including noise-induced velocity variations, continuous interaction environments, and different vehicle numbers and road configurations.
PPG to ECG Signal Translation for Continuous Atrial Fibrillation Detection via Attention-based Deep State-Space Modeling
Sep 27, 2023An electrocardiogram (ECG or EKG) is a medical test that measures the heart's electrical activity. ECGs are often used to diagnose and monitor a wide range of heart conditions, including arrhythmias, heart attacks, and heart failure. On the one hand, the conventional ECG requires clinical measurement, which restricts its deployment to medical facilities. On the other hand, single-lead ECG has become popular on wearable devices using administered procedures. An alternative to ECG is Photoplethysmography (PPG), which uses non-invasive, low-cost optical methods to measure cardiac physiology, making it a suitable option for capturing vital heart signs in daily life. As a result, it has become increasingly popular in health monitoring and is used in various clinical and commercial wearable devices. While ECG and PPG correlate strongly, the latter does not offer significant clinical diagnostic value. Here, we propose a subject-independent attention-based deep state-space model to translate PPG signals to corresponding ECG waveforms. The model is highly data-efficient by incorporating prior knowledge in terms of probabilistic graphical models. Notably, the model enables the detection of atrial fibrillation (AFib), the most common heart rhythm disorder in adults, by complementing ECG's accuracy with continuous PPG monitoring. We evaluated the model on 55 subjects from the MIMIC III database. Quantitative and qualitative experimental results demonstrate the effectiveness and efficiency of our approach.
Zero-Shot Learning of a Conditional Generative Adversarial Network for Data-Free Network Quantization
Oct 26, 2022


We propose a novel method for training a conditional generative adversarial network (CGAN) without the use of training data, called zero-shot learning of a CGAN (ZS-CGAN). Zero-shot learning of a conditional generator only needs a pre-trained discriminative (classification) model and does not need any training data. In particular, the conditional generator is trained to produce labeled synthetic samples whose characteristics mimic the original training data by using the statistics stored in the batch normalization layers of the pre-trained model. We show the usefulness of ZS-CGAN in data-free quantization of deep neural networks. We achieved the state-of-the-art data-free network quantization of the ResNet and MobileNet classification models trained on the ImageNet dataset. Data-free quantization using ZS-CGAN showed a minimal loss in accuracy compared to that obtained by conventional data-dependent quantization.
Toward Sustainable Continual Learning: Detection and Knowledge Repurposing of Similar Tasks
Oct 11, 2022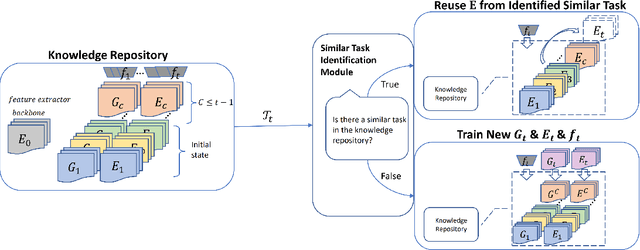

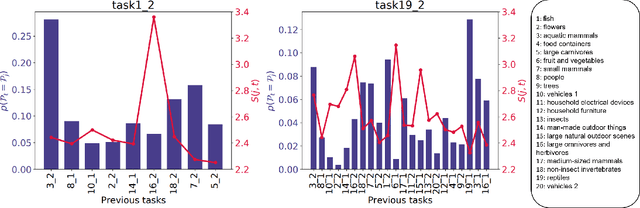
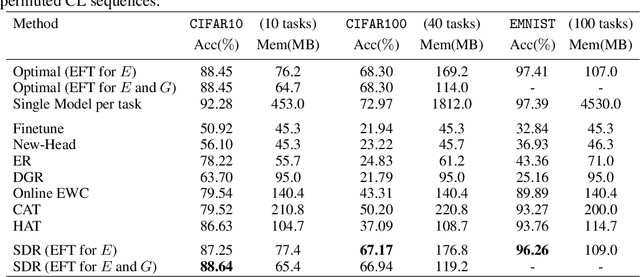
Most existing works on continual learning (CL) focus on overcoming the catastrophic forgetting (CF) problem, with dynamic models and replay methods performing exceptionally well. However, since current works tend to assume exclusivity or dissimilarity among learning tasks, these methods require constantly accumulating task-specific knowledge in memory for each task. This results in the eventual prohibitive expansion of the knowledge repository if we consider learning from a long sequence of tasks. In this work, we introduce a paradigm where the continual learner gets a sequence of mixed similar and dissimilar tasks. We propose a new continual learning framework that uses a task similarity detection function that does not require additional learning, with which we analyze whether there is a specific task in the past that is similar to the current task. We can then reuse previous task knowledge to slow down parameter expansion, ensuring that the CL system expands the knowledge repository sublinearly to the number of learned tasks. Our experiments show that the proposed framework performs competitively on widely used computer vision benchmarks such as CIFAR10, CIFAR100, and EMNIST.
Dual-Teacher Class-Incremental Learning With Data-Free Generative Replay
Jun 17, 2021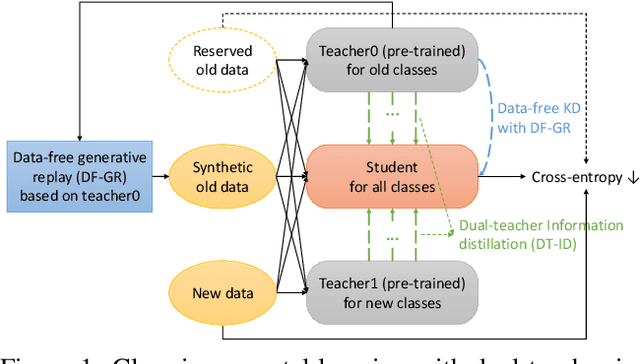

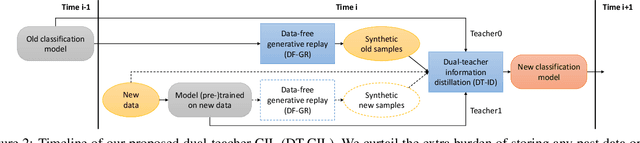

This paper proposes two novel knowledge transfer techniques for class-incremental learning (CIL). First, we propose data-free generative replay (DF-GR) to mitigate catastrophic forgetting in CIL by using synthetic samples from a generative model. In the conventional generative replay, the generative model is pre-trained for old data and shared in extra memory for later incremental learning. In our proposed DF-GR, we train a generative model from scratch without using any training data, based on the pre-trained classification model from the past, so we curtail the cost of sharing pre-trained generative models. Second, we introduce dual-teacher information distillation (DT-ID) for knowledge distillation from two teachers to one student. In CIL, we use DT-ID to learn new classes incrementally based on the pre-trained model for old classes and another model (pre-)trained on the new data for new classes. We implemented the proposed schemes on top of one of the state-of-the-art CIL methods and showed the performance improvement on CIFAR-100 and ImageNet datasets.
Data-Free Network Quantization With Adversarial Knowledge Distillation
May 08, 2020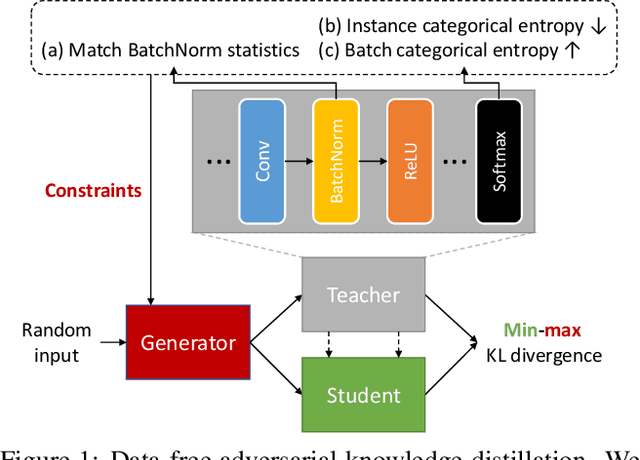


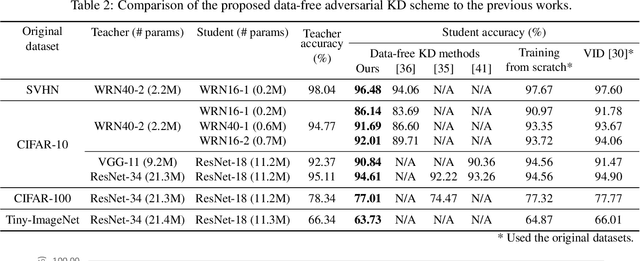
Network quantization is an essential procedure in deep learning for development of efficient fixed-point inference models on mobile or edge platforms. However, as datasets grow larger and privacy regulations become stricter, data sharing for model compression gets more difficult and restricted. In this paper, we consider data-free network quantization with synthetic data. The synthetic data are generated from a generator, while no data are used in training the generator and in quantization. To this end, we propose data-free adversarial knowledge distillation, which minimizes the maximum distance between the outputs of the teacher and the (quantized) student for any adversarial samples from a generator. To generate adversarial samples similar to the original data, we additionally propose matching statistics from the batch normalization layers for generated data and the original data in the teacher. Furthermore, we show the gain of producing diverse adversarial samples by using multiple generators and multiple students. Our experiments show the state-of-the-art data-free model compression and quantization results for (wide) residual networks and MobileNet on SVHN, CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets. The accuracy losses compared to using the original datasets are shown to be very minimal.
Variable Rate Deep Image Compression With a Conditional Autoencoder
Sep 11, 2019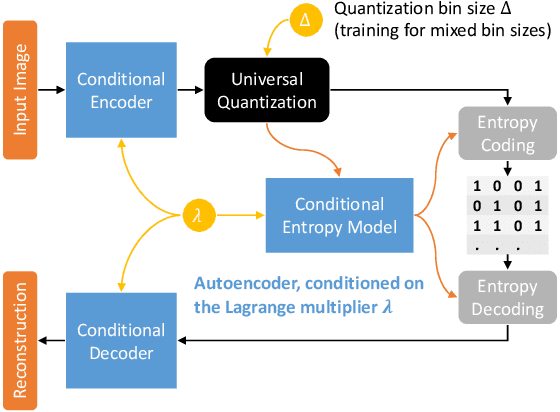

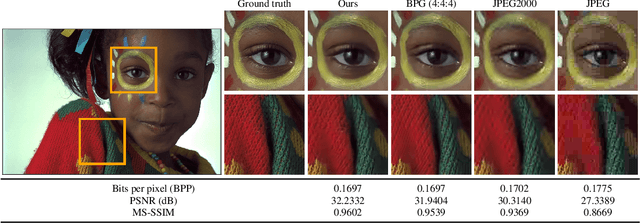
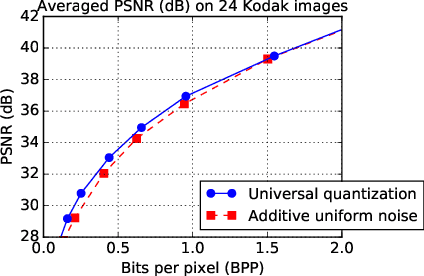
In this paper, we propose a novel variable-rate learned image compression framework with a conditional autoencoder. Previous learning-based image compression methods mostly require training separate networks for different compression rates so they can yield compressed images of varying quality. In contrast, we train and deploy only one variable-rate image compression network implemented with a conditional autoencoder. We provide two rate control parameters, i.e., the Lagrange multiplier and the quantization bin size, which are given as conditioning variables to the network. Coarse rate adaptation to a target is performed by changing the Lagrange multiplier, while the rate can be further fine-tuned by adjusting the bin size used in quantizing the encoded representation. Our experimental results show that the proposed scheme provides a better rate-distortion trade-off than the traditional variable-rate image compression codecs such as JPEG2000 and BPG. Our model also shows comparable and sometimes better performance than the state-of-the-art learned image compression models that deploy multiple networks trained for varying rates.
Wyner VAE: Joint and Conditional Generation with Succinct Common Representation Learning
May 27, 2019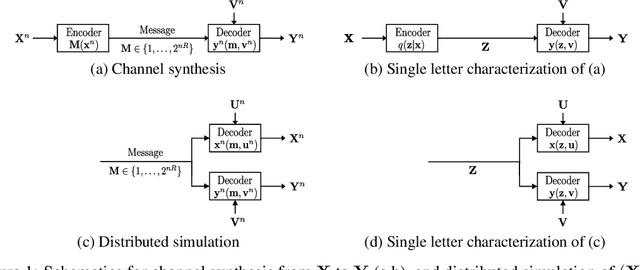

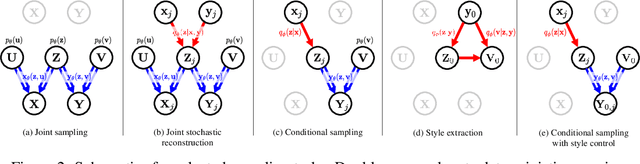

A new variational autoencoder (VAE) model is proposed that learns a succinct common representation of two correlated data variables for conditional and joint generation tasks. The proposed Wyner VAE model is based on two information theoretic problems---distributed simulation and channel synthesis---in which Wyner's common information arises as the fundamental limit of the succinctness of the common representation. The Wyner VAE decomposes a pair of correlated data variables into their common representation (e.g., a shared concept) and local representations that capture the remaining randomness (e.g., texture and style) in respective data variables by imposing the mutual information between the data variables and the common representation as a regularization term. The utility of the proposed approach is demonstrated through experiments for joint and conditional generation with and without style control using synthetic data and real images. Experimental results show that learning a succinct common representation achieves better generative performance and that the proposed model outperforms existing VAE variants and the variational information bottleneck method.