 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyDRA: Hybrid Domain-Aware Robust Architecture for Heterogeneous Collaborative Perception
Mar 25, 2026In collaborative perception, an agent's performance can be degraded by heterogeneity arising from differences in model architecture or training data distributions. To address this challenge, we propose HyDRA (Hybrid Domain-Aware Robust Architecture), a unified pipeline that integrates intermediate and late fusion within a domain-aware framework. We introduce a lightweight domain classifier that dynamically identifies heterogeneous agents and assigns them to the late-fusion branch. Furthermore, we propose anchor-guided pose graph optimization to mitigate localization errors inherent in late fusion, leveraging reliable detections from intermediate fusion as fixed spatial anchors. Extensive experiments demonstrate that, despite requiring no additional training, HyDRA achieves performance comparable to state-of-the-art heterogeneity-aware CP methods. Importantly, this performance is maintained as the number of collaborating agents increases, enabling zero-cost scaling without retraining.
High-Density Automated Valet Parking with Relocation-Free Sequential Operations
Mar 25, 2026In this paper, we present DROP, high-Density Relocation-free sequential OPerations in automated valet parking. DROP addresses the challenges in high-density parking & vehicle retrieval without relocations. Each challenge is handled by jointly providing area-efficient layouts and relocation-free parking & exit sequences, considering accessibility with relocation-free sequential operations. To generate such sequences, relocation-free constraints are formulated as explicit logical conditions expressed in boolean variables. Recursive search strategies are employed to derive the logical conditions and enumerate relocation-free sequences under sequential constraints. We demonstrate the effectiveness of our framework through extensive simulations, showing its potential to significantly improve area utilization with relocation-free constraints. We also examine its viability on an application problem with prescribed operational order. The results from all experiments are available at: https://drop-park.github.io.
Miniature Testbed for Validating Multi-Agent Cooperative Autonomous Driving
Nov 14, 2025
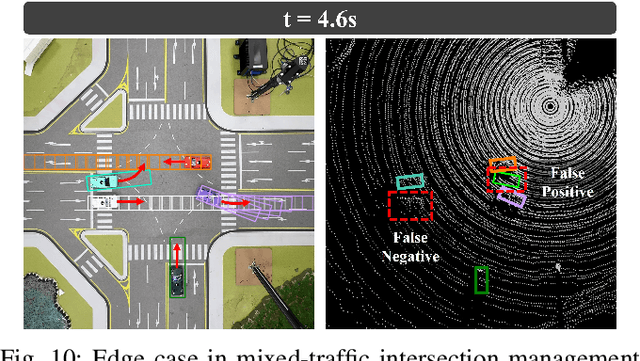
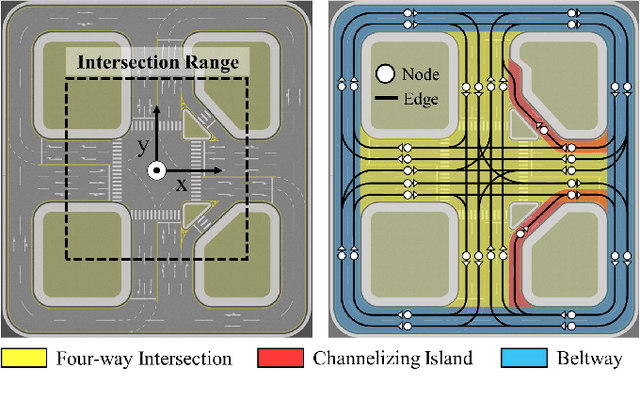
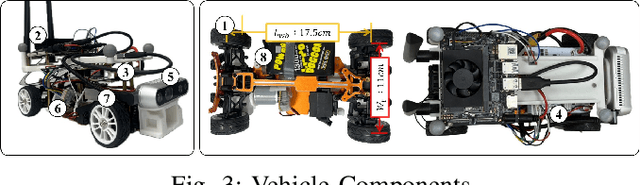
Cooperative autonomous driving, which extends vehicle autonomy by enabling real-time collaboration between vehicles and smart roadside infrastructure, remains a challenging yet essential problem. However, none of the existing testbeds employ smart infrastructure equipped with sensing, edge computing, and communication capabilities. To address this gap, we design and implement a 1:15-scale miniature testbed, CIVAT, for validating cooperative autonomous driving, consisting of a scaled urban map, autonomous vehicles with onboard sensors, and smart infrastructure. The proposed testbed integrates V2V and V2I communication with the publish-subscribe pattern through a shared Wi-Fi and ROS2 framework, enabling information exchange between vehicles and infrastructure to realize cooperative driving functionality. As a case study, we validate the system through infrastructure-based perception and intersection management experiments.
Rethinking the Role of Infrastructure in Collaborative Perception
Oct 15, 2024Collaborative Perception (CP) is a process in which an ego agent receives and fuses sensor information from surrounding vehicles and infrastructure to enhance its perception capability. To evaluate the need for infrastructure equipped with sensors, extensive and quantitative analysis of the role of infrastructure data in CP is crucial, yet remains underexplored. To address this gap, we first quantitatively assess the importance of infrastructure data in existing vehicle-centric CP, where the ego agent is a vehicle. Furthermore, we compare vehicle-centric CP with infra-centric CP, where the ego agent is now the infrastructure, to evaluate the effectiveness of each approach. Our results demonstrate that incorporating infrastructure data improves 3D detection accuracy by up to 10.87%, and infra-centric CP shows enhanced noise robustness and increases accuracy by up to 42.53% compared with vehicle-centric CP.
A GPT-based Decision Transformer for Multi-Vehicle Coordination at Unsignalized Intersections
Oct 08, 2024
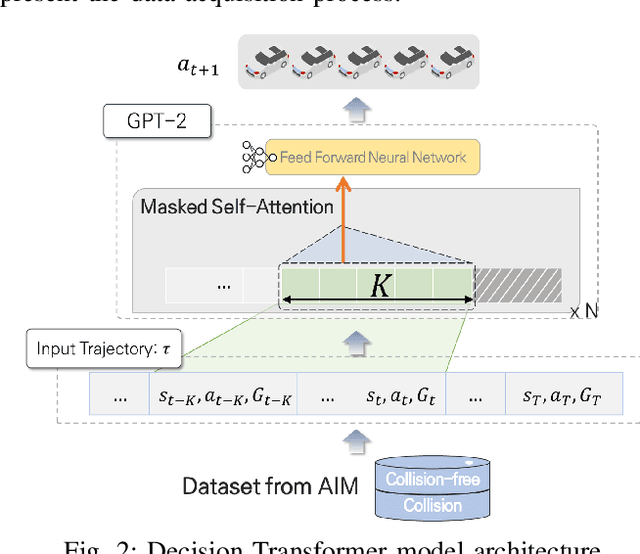
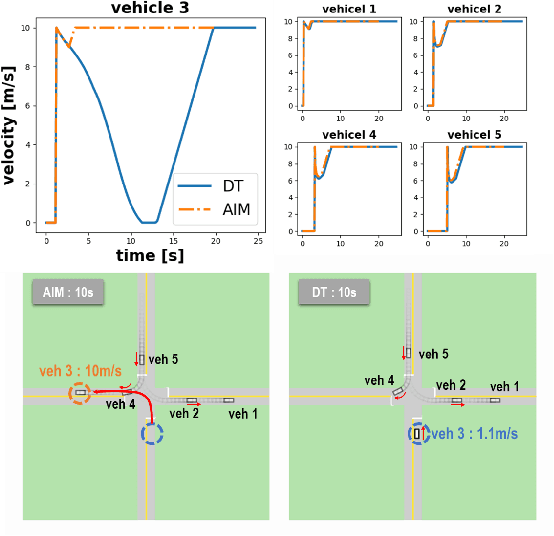
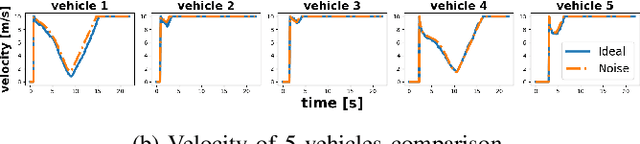
In this paper, we explore the application of the Decision Transformer, a decision-making algorithm based on the Generative Pre-trained Transformer (GPT) architecture, to multi-vehicle coordination at unsignalized intersections. We formulate the coordination problem so as to find the optimal trajectories for multiple vehicles at intersections, modeling it as a sequence prediction task to fully leverage the power of GPTs as a sequence model. Through extensive experiments, we compare our approach to a reservation-based intersection management system. Our results show that the Decision Transformer can outperform the training data in terms of total travel time and can be generalized effectively to various scenarios, including noise-induced velocity variations, continuous interaction environments, and different vehicle numbers and road configurations.
V2X-M2C: Efficient Multi-Module Collaborative Perception with Two Connections
Jul 16, 2024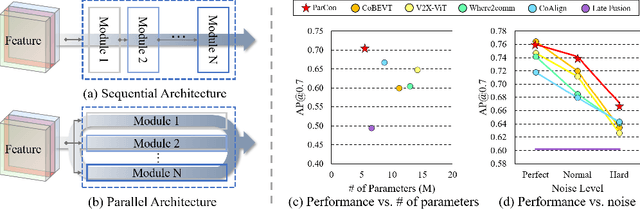
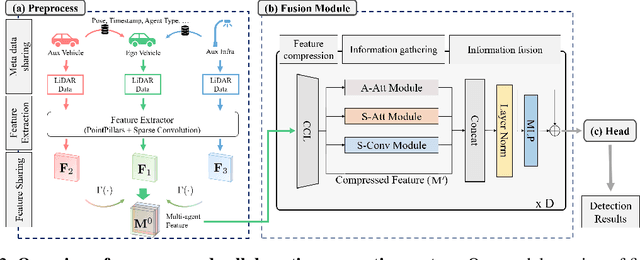
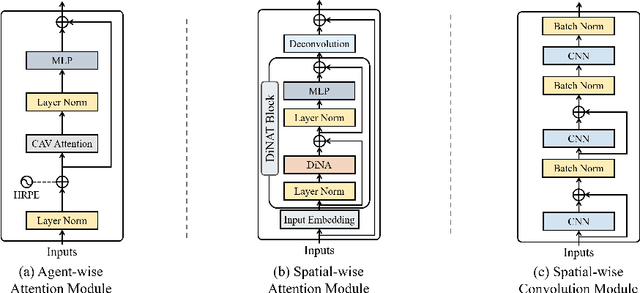
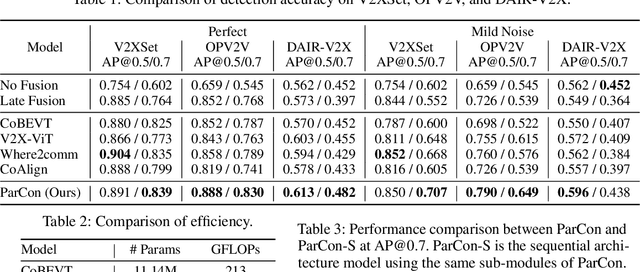
In this paper, we investigate improving the perception performance of autonomous vehicles through communication with other vehicles and road infrastructures. To this end, we introduce a collaborative perception model $\textbf{V2X-M2C}$, consisting of multiple modules, each generating inter-agent complementary information, spatial global context, and spatial local information. Inspired by the question of why most existing architectures are sequential, we analyze both the $\textit{sequential}$ and $\textit{parallel}$ connections of the modules. The sequential connection synergizes the modules, whereas the parallel connection independently improves each module. Extensive experiments demonstrate that V2X-M2C achieves state-of-the-art perception performance, increasing the detection accuracy by 8.00% to 10.87% and decreasing the FLOPs by 42.81% to 52.64%.