 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRDiff: Feature Reuse for Exquisite Zero-shot Acceleration of Diffusion Models
Dec 06, 2023The substantial computational costs of diffusion models, particularly due to the repeated denoising steps crucial for high-quality image generation, present a major obstacle to their widespread adoption. While several studies have attempted to address this issue by reducing the number of score function evaluations using advanced ODE solvers without fine-tuning, the decreased number of denoising iterations misses the opportunity to update fine details, resulting in noticeable quality degradation. In our work, we introduce an advanced acceleration technique that leverages the temporal redundancy inherent in diffusion models. Reusing feature maps with high temporal similarity opens up a new opportunity to save computation without sacrificing output quality. To realize the practical benefits of this intuition, we conduct an extensive analysis and propose a novel method, FRDiff. FRDiff is designed to harness the advantages of both reduced NFE and feature reuse, achieving a Pareto frontier that balances fidelity and latency trade-offs in various generative tasks.
Temporal Dynamic Quantization for Diffusion Models
Jun 04, 2023The diffusion model has gained popularity in vision applications due to its remarkable generative performance and versatility. However, high storage and computation demands, resulting from the model size and iterative generation, hinder its use on mobile devices. Existing quantization techniques struggle to maintain performance even in 8-bit precision due to the diffusion model's unique property of temporal variation in activation. We introduce a novel quantization method that dynamically adjusts the quantization interval based on time step information, significantly improving output quality. Unlike conventional dynamic quantization techniques, our approach has no computational overhead during inference and is compatible with both post-training quantization (PTQ) and quantization-aware training (QAT). Our extensive experiments demonstrate substantial improvements in output quality with the quantized diffusion model across various datasets.
Zero-Shot Learning of a Conditional Generative Adversarial Network for Data-Free Network Quantization
Oct 26, 2022


We propose a novel method for training a conditional generative adversarial network (CGAN) without the use of training data, called zero-shot learning of a CGAN (ZS-CGAN). Zero-shot learning of a conditional generator only needs a pre-trained discriminative (classification) model and does not need any training data. In particular, the conditional generator is trained to produce labeled synthetic samples whose characteristics mimic the original training data by using the statistics stored in the batch normalization layers of the pre-trained model. We show the usefulness of ZS-CGAN in data-free quantization of deep neural networks. We achieved the state-of-the-art data-free network quantization of the ResNet and MobileNet classification models trained on the ImageNet dataset. Data-free quantization using ZS-CGAN showed a minimal loss in accuracy compared to that obtained by conventional data-dependent quantization.
Dual-Teacher Class-Incremental Learning With Data-Free Generative Replay
Jun 17, 2021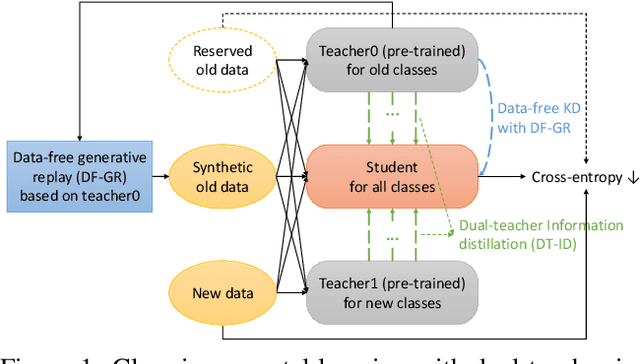

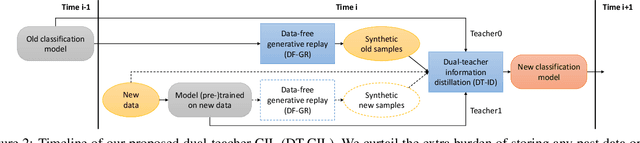

This paper proposes two novel knowledge transfer techniques for class-incremental learning (CIL). First, we propose data-free generative replay (DF-GR) to mitigate catastrophic forgetting in CIL by using synthetic samples from a generative model. In the conventional generative replay, the generative model is pre-trained for old data and shared in extra memory for later incremental learning. In our proposed DF-GR, we train a generative model from scratch without using any training data, based on the pre-trained classification model from the past, so we curtail the cost of sharing pre-trained generative models. Second, we introduce dual-teacher information distillation (DT-ID) for knowledge distillation from two teachers to one student. In CIL, we use DT-ID to learn new classes incrementally based on the pre-trained model for old classes and another model (pre-)trained on the new data for new classes. We implemented the proposed schemes on top of one of the state-of-the-art CIL methods and showed the performance improvement on CIFAR-100 and ImageNet datasets.
Towards Fair Federated Learning with Zero-Shot Data Augmentation
Apr 27, 2021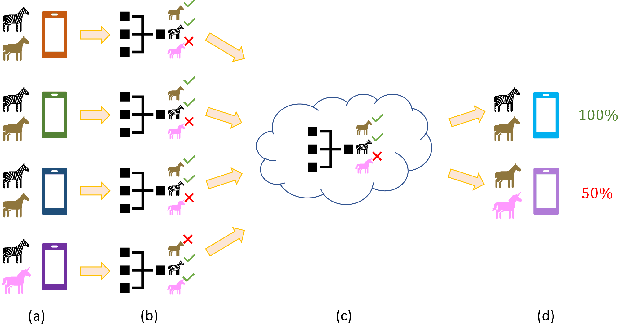
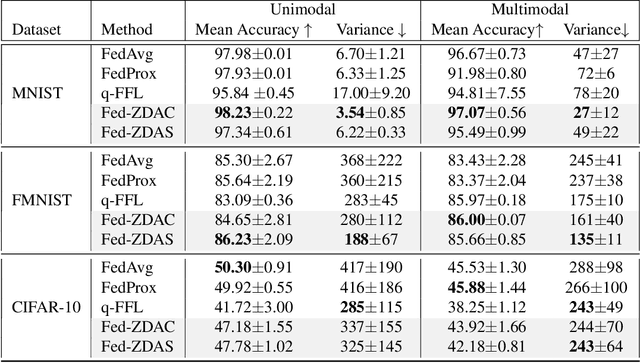
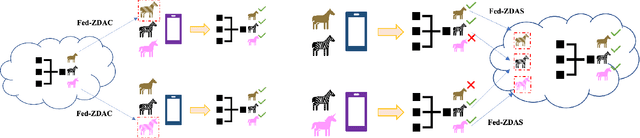
Federated learning has emerged as an important distributed learning paradigm, where a server aggregates a global model from many client-trained models while having no access to the client data. Although it is recognized that statistical heterogeneity of the client local data yields slower global model convergence, it is less commonly recognized that it also yields a biased federated global model with a high variance of accuracy across clients. In this work, we aim to provide federated learning schemes with improved fairness. To tackle this challenge, we propose a novel federated learning system that employs zero-shot data augmentation on under-represented data to mitigate statistical heterogeneity and encourage more uniform accuracy performance across clients in federated networks. We study two variants of this scheme, Fed-ZDAC (federated learning with zero-shot data augmentation at the clients) and Fed-ZDAS (federated learning with zero-shot data augmentation at the server). Empirical results on a suite of datasets demonstrate the effectiveness of our methods on simultaneously improving the test accuracy and fairness.
Data-Free Network Quantization With Adversarial Knowledge Distillation
May 08, 2020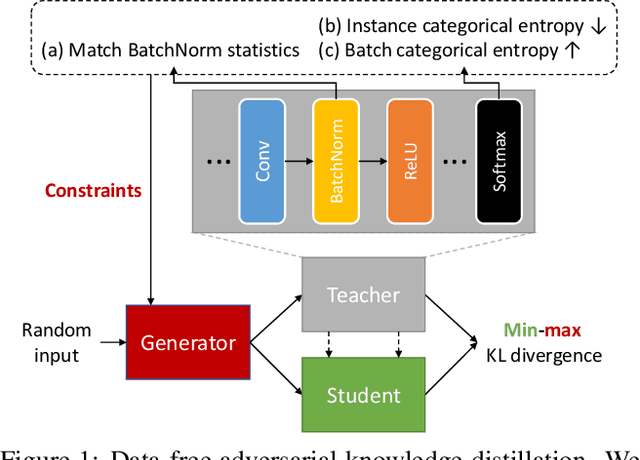


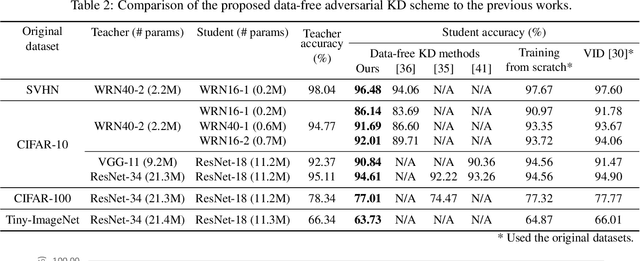
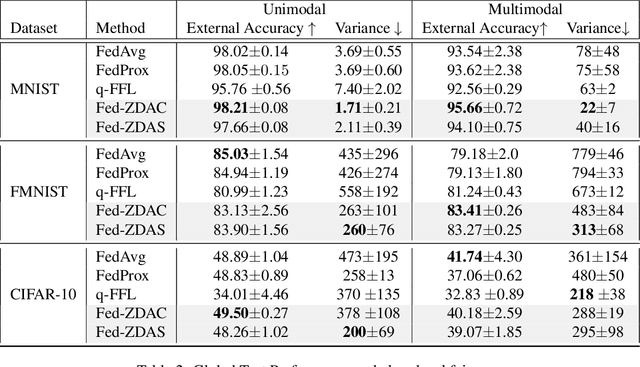
Network quantization is an essential procedure in deep learning for development of efficient fixed-point inference models on mobile or edge platforms. However, as datasets grow larger and privacy regulations become stricter, data sharing for model compression gets more difficult and restricted. In this paper, we consider data-free network quantization with synthetic data. The synthetic data are generated from a generator, while no data are used in training the generator and in quantization. To this end, we propose data-free adversarial knowledge distillation, which minimizes the maximum distance between the outputs of the teacher and the (quantized) student for any adversarial samples from a generator. To generate adversarial samples similar to the original data, we additionally propose matching statistics from the batch normalization layers for generated data and the original data in the teacher. Furthermore, we show the gain of producing diverse adversarial samples by using multiple generators and multiple students. Our experiments show the state-of-the-art data-free model compression and quantization results for (wide) residual networks and MobileNet on SVHN, CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets. The accuracy losses compared to using the original datasets are shown to be very minimal.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020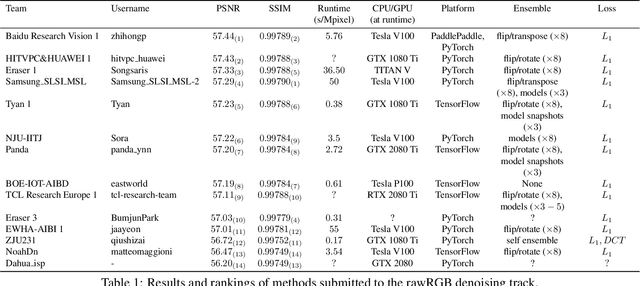
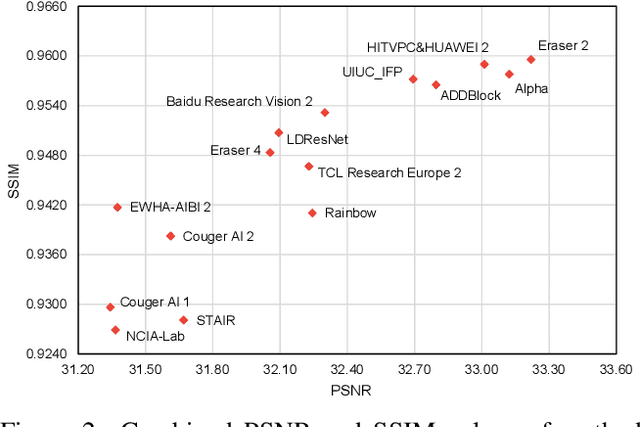
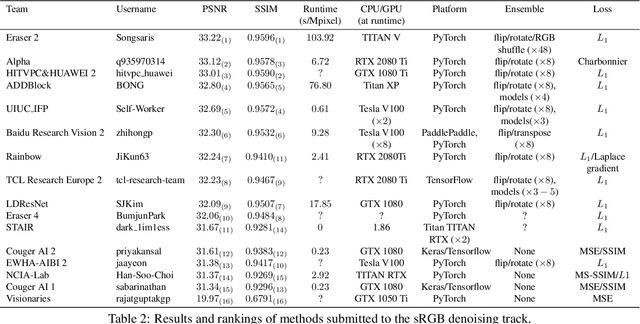
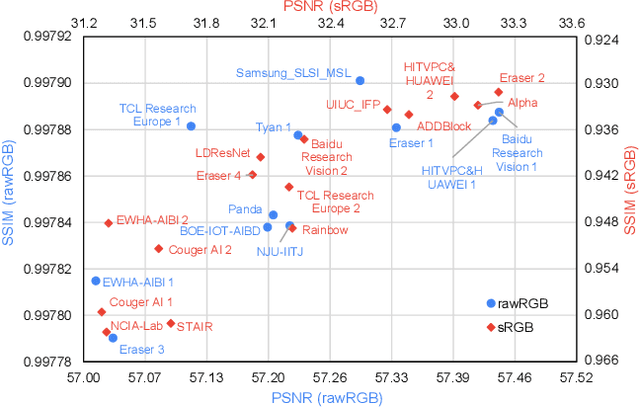
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
NTIRE 2020 Challenge on Real-World Image Super-Resolution: Methods and Results
May 05, 2020
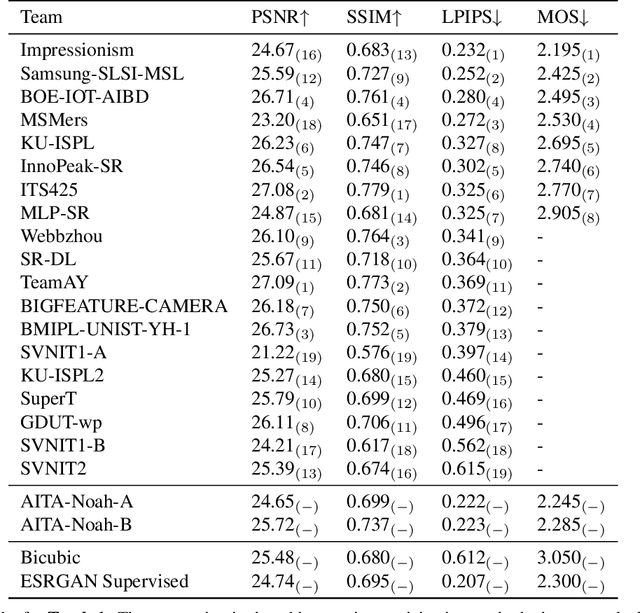
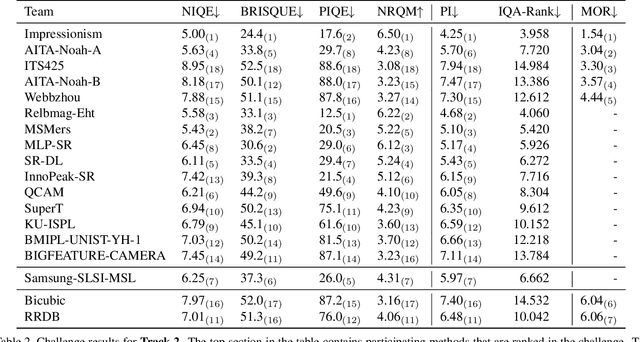

This paper reviews the NTIRE 2020 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided along with a set of unpaired high-quality target images. In Track 1: Image Processing artifacts, the aim is to super-resolve images with synthetically generated image processing artifacts. This allows for quantitative benchmarking of the approaches \wrt a ground-truth image. In Track 2: Smartphone Images, real low-quality smart phone images have to be super-resolved. In both tracks, the ultimate goal is to achieve the best perceptual quality, evaluated using a human study. This is the second challenge on the subject, following AIM 2019, targeting to advance the state-of-the-art in super-resolution. To measure the performance we use the benchmark protocol from AIM 2019. In total 22 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
GSANet: Semantic Segmentation with Global and Selective Attention
Feb 14, 2020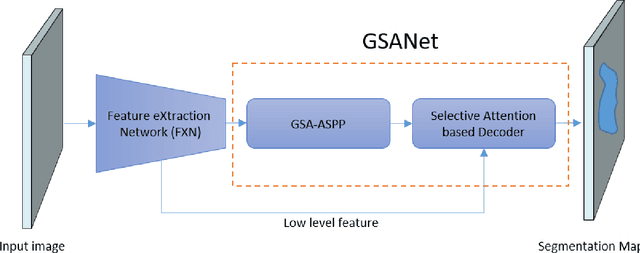
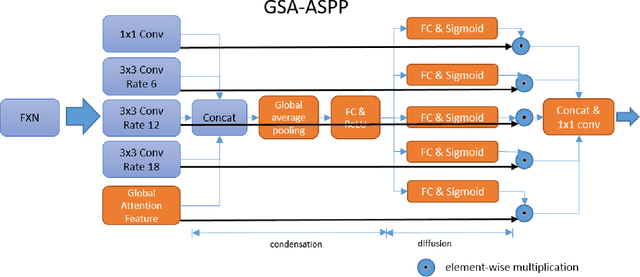
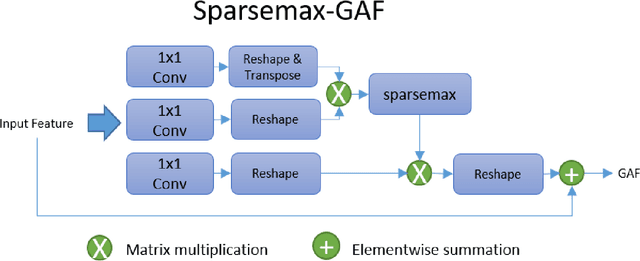

This paper proposes a novel deep learning architecture for semantic segmentation. The proposed Global and Selective Attention Network (GSANet) features Atrous Spatial Pyramid Pooling (ASPP) with a novel sparsemax global attention and a novel selective attention that deploys a condensation and diffusion mechanism to aggregate the multi-scale contextual information from the extracted deep features. A selective attention decoder is also proposed to process the GSA-ASPP outputs for optimizing the softmax volume. We are the first to benchmark the performance of semantic segmentation networks with the low-complexity feature extraction network (FXN) MobileNetEdge, that is optimized for low latency on edge devices. We show that GSANet can result in more accurate segmentation with MobileNetEdge, as well as with strong FXNs, such as Xception. GSANet improves the state-of-art semantic segmentation accuracy on both the ADE20k and the Cityscapes datasets.
HyperCon: Image-To-Video Model Transfer for Video-To-Video Translation Tasks
Dec 10, 2019
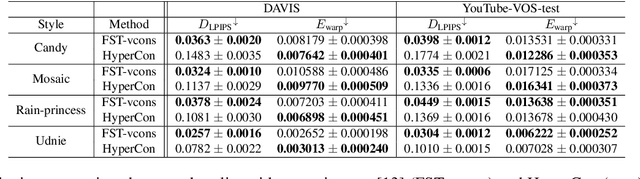
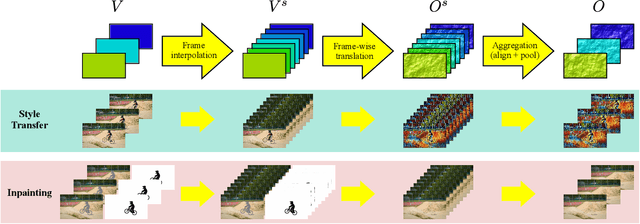

Video-to-video translation for super-resolution, inpainting, style transfer, etc. is more difficult than corresponding image-to-image translation tasks due to the temporal consistency problem that, if left unaddressed, results in distracting flickering effects. Although video models designed from scratch produce temporally consistent results, training them to match the vast visual knowledge captured by image models requires an intractable number of videos. To combine the benefits of image and video models, we propose an image-to-video model transfer method called Hyperconsistency (HyperCon) that transforms any well-trained image model into a temporally consistent video model without fine-tuning. HyperCon works by translating a synthetic temporally interpolated video frame-wise and then aggregating over temporally localized windows on the interpolated video. It handles both masked and unmasked inputs, enabling support for even more video-to-video tasks than prior image-to-video model transfer techniques. We demonstrate HyperCon on video style transfer and inpainting, where it performs favorably compared to prior state-of-the-art video consistency and video inpainting methods, all without training on a single stylized or incomplete video.